【start:2022.12.15】
1. 参考文献
1.1. 数据集
数据集来源的竞赛:细胞跟踪挑战赛
制作数据集的工具:自制VOC2007数据集——train、trainval、val、test文件的生成
1.2. 可复现的代码
【code】结合YOLOv5的DeepSORT的可成功复现的项目:https://github.com/HowieMa/DeepSORT_YOLOv5_Pytorch
本文复现基于上述项目
1.3. YOLO教程
【YOLOv3】yolov3训练自己的数据集
【YOLOv5】3小时把YOLOv5解读、训练、复现都讲清楚透彻了!
模型讲解不错
1.4. DeepSORT教程
【ref】Yolov5 + Deepsort 重新训练自己的数据(保姆级超详细)
【ref】Yolov5 + Deepsort 重新训练自己的数据(保姆级超详细)
【ref】目标追踪—deepsort原理讲解
流程图不错,级联匹配没展开讲
【ref】目标追踪–deepsort算法的讲解和训练自己的特征提取网络
流程图讲解不错,级联匹配没展开讲
【ref】多目标跟踪(二)DeepSort——级联匹配Matching Cascade
级联匹配讲的不错
1.5. 集成软件
【ref】MATLAB科研图像处理——细胞追踪
【software】trackmate软件
https://imagej.net/plugins/trackmate/getting-started
https://imagej.net/plugins/piv-analyser
【python library】trackpy库
http://soft-matter.github.io/trackpy/v0.5.0/
2. 图片预处理-OpenCV
该节可跳过
虽然数据增强工作不是必须的,但是做了可以显著提高目标检测效果
2.1. 原图

2.2. Close运算

2.3. Close运算+Sobel算子

3. 数据集制作-labelimg
3.1. labelimg标签
首先创建如下格式的文件夹
在python环境中下载插件:pip install labelimg
选择保存格式为yolo,然后开始打标签
获得含标签结果的txt文件(用于yolo,马上用)和xml文件(用于deepsort,见后文),
其中,xml格式包含的信息会多一些,所以可以优先保存xml文件
注意,每次开始打标签前,要确定标签名字没有打错,否则后期得一个一个改。。。
3.2. img生成txt和xml文件
为了让yolo能够根据路径找到训练集,用多个txt文件,生成含所有有标签路径的txt文件
用一个含有多张图片的文件夹,生成含有所有图片路径的txt文件
'''
image gen all_images_txt
generate file name in a big file_box
'''
import glob
path = r'D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label'
def generate_train_and_val(image_path, txt_file):
print(image_path)
print(txt_file)
with open(txt_file, 'w') as tf:
print('open')
print(glob.glob(image_path + '\*.png'))
for jpg_file in glob.glob(image_path + '\*.png'):
tf.write(jpg_file + '\n')
# print(glob.glob(image_path + '\*.jpg'))
# for jpg_file in glob.glob(image_path + '\*.jpg'):
# tf.write(jpg_file + '\n')
generate_train_and_val(path + r'\images\train', path + r'\\train.txt')
generate_train_and_val(path + r'\images\val', path + '\\val.txt')
疑问:
在小目标检测(跟踪)项目中,需要制作(YOLO)训练集时,如果一张图中有很多小目标,是否要把整张图作为一个训练样本?还是只需要截取包含部分目标的图?
回答:
在小目标检测(跟踪)项目中,通常会将整张图作为一个训练样本。
这是因为目标检测算法需要学习如何从整张图中找出目标,而不是仅仅从部分图像中找出目标。 然而,在整张图像中包含多个小目标的情况下,可以通过标注每个小目标的位置来让算法学习如何检测和识别它们。
一种常用的方法是使用标注工具来手动标注每个小目标的位置,并将这些标注信息保存在标注文件中,如XML或JSON格式。然后,通过解析标注文件并从整张图像中裁剪出包含每个小目标的图像块来生成训练样本。
注意,对于包含许多小目标的图像,裁剪出每个小目标的图像块可能会生成大量的训练样本。在这种情况下,可以考虑使用一些策略来减少训练样本的数量,例如随机选择一些小目标来生成训练样本,或者使用数据增强技术来扩充训练集。
4. 目标检测-YOLOv5
4.1. yolo框架下载
教程:https://www.iotword.com/3391.html
代码:https://github.com/HowieMa/DeepSORT_YOLOv5_Pytorch
4.2. 改data-data.yaml

4.3. 改models-yolo.yaml

4.3.1. 改网络骨架
把class改为自己数据集的类别数
4.3.2. 改anchor框
【ref】YOLOv5的anchor设定
【ref】科普:目标检测Anchor是什么?怎么科学设置?[附代码]
对于目标检测的anchor 设置,一定要根据您的数据分布设置合理的anchor,另外,也要考虑是否是归一化的anchor大小,或者是否做了改变图像长宽比的resize。
问题:
在YOLOv5中,目标检测的类别(class)只有“圆形粒子”一种时,怎么在yaml文件中设置合适的anchor的尺寸?
回答:
在目标检测中,anchor是一组用于估计目标位置和尺寸的预定义框。为了使训练过程更加准确,anchor的大小应该与目标的大小和比例相匹配。如果anchor的大小与目标的大小不匹配,那么检测器可能会出现漏检或误检等问题。
一种常见的做法是使用聚类算法(如k-means算法)从训练数据中学习出最优的anchor尺寸。这种方法可以自适应地生成适合目标大小和比例的anchor,从而提高检测器的准确性。
具体地,对于一个特定的目标类别,你可以从训练数据中提取所有目标的宽度和高度,并使用k-means算法将它们聚类成一组anchor。聚类的结果通常是一组中心点,每个中心点对应一个anchor,anchor的宽度和高度可以根据中心点计算得出。这样,就可以得到一组与目标类别大小和比例相匹配的anchor。
需要注意的是,生成的anchor的数量和大小需要根据目标类别的大小和比例来调整。如果目标类别非常小,则可以生成更小的anchor;如果目标类别较大,则需要生成更大的anchor。另外,如果目标类别有多个子类别,每个子类别可能需要使用不同的anchor尺寸。
4.4. 改utils文件路径
采用别人的框架时,会遇到一种情况,即一个大master里既有yolo又有deepsort,其中deepsort会直接调用yolo,这时,单独训练yolo模块时,yolo可能会找不到自己工具的路径,所以训练yolo时相对路径可能需要手动切换,或者可以采用try except语法一次性解决两种路径情况。

4.5. 改精度half为float
需要将detect.py文件代码中的所有half改为float,map才会上升

原因:
在PyTorch中,数据类型有float16、float32、float64等。这些数据类型的存储空间和精度不同,一般来说,float32的精度最高,float16的精度相对较低,但是存储空间较小。在训练和推理时,通常会使用float32数据类型来保证模型的准确性和稳定性。
在detect.py文件中,模型推理时默认使用float16数据类型来进行计算,这是为了在计算中使用更小的内存。但是,由于float16数据类型的精度较低,可能会导致模型的推理结果不够准确。因此,将float16数据类型改为float32数据类型,可以提高模型推理的精度。
另外,如果你的GPU支持float16计算,那么你可以使用torch.backends.cudnn.benchmark = True来自动选择最快的算法。这个方法也可以提高模型推理的速度和精度。
总的来说,选择合适的数据类型是一个平衡存储空间和计算精度的问题。对于不同的应用场景,需要根据具体情况来选择合适的数据类型。
4.6. 下载预训练pt文件

4.7. yolo训练
4.7.1. 调参
一般选这两个调参对象:conf置信度+iou交并比
YOLO 检测中有两个阈值参数,conf置信度比较好理解,但是IOU交并比 thres比较难理解。
IOU thres过大容易出现一个目标多个检测框;IOU thres过小容易出现检测结果少的问题。
4.7.2. 运行
:: cmd
conda activate F:\CS\Anaconda\envs\deeplearning
cd D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5
::使用默认文件夹的权重
python train.py --batch 16 --epoch 100 --data data/my_particle.yaml --cfg models/my_particle_yolov5s.yaml --weights weights/yolov5s.pt
::使用自己训练的权重
python train.py --batch 16 --epoch 100 --data data/my_particle.yaml --cfg models/my_particle_yolov5s.yaml --weights D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5\runs\exp8\weights\last.pt
经过33个Epoch后,mAP才开始大于0,有时候可能要更久
4.7.3. 结果
经过499个epoch后,结果如下,mAP达到了0.986,足够进行较好的目标检测工作。

4.8. yolo检测
4.8.1. 检测框参数
在该路径下可以修改检测框的外形
4.8.2. 其他参数
conf置信度
置信度用来判断边界框内的物体是正样本还是负样本,大于置信度阈值的判定为正样本,小于置信度阈值的判定为负样本即背景。
iou交并比
IOU被用来判断bbox是正样本还是负样本。
IOU thres过大容易出现一个目标多个检测框;IOU thres过小容易出现检测结果少的问题。
4.8.3. 运行
:: cmd
conda activate F:\CS\Anaconda\envs\deeplearning
D:
cd D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5
::检测1
python detect.py --source D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\images\val\PEG_fliter_5.png --weights D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5\runs\exp8\weights\last.pt --device 'cpu' --conf-thres 0.1 --iou-thres 0.1
::检测2
python detect.py --source D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\images\val\PEG_fliter_5.png --weights D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5\runs\exp9\weights\best.pt --device 'cpu' --conf-thres 0.1 --iou-thres 0.1
4.8.4. 报错
'''
CUDA unavailable, invalid device 'cpu' requested
如下,把部分代码注释掉即可
'''
def select_device(device='', batch_size=None):
# device = 'cpu' or '0' or '0,1,2,3'
cpu_request = device.lower() == 'cpu'
# if device and not cpu_request: # if device requested other than 'cpu'
# os.environ['CUDA_VISIBLE_DEVICES'] = device # set environment variable
# assert torch.cuda.is_available(), 'CUDA unavailable, invalid device %s requested' % device # check availablity
4.8.5. 结果
conf取的越小,能检测出来的框越多;iou取的越大,重叠的框越多
–conf-thres 0.75 --iou-thres 0.1
–conf-thres 0.7 --iou-thres 0.1
4.9. 提高训练精度
4.9.1. 检查训练集
图片img和标签txt数量、匹配是否有错?
比如,如果训练集图片的index从0开始,放4张ig,素材应该取0,1,2,3,而不是0,1,2,3,4
4.9.2. 改预设锚定框
先明确anchor的单位是多少
调整yolo.yaml中的anchors
# anchors
anchors:
- [5,6, 7,8, 9,10] # P3/8
- [25,26, 27,28, 29,30] # P4/16
- [35,36, 37,38, 39,40] # P5/32
# anchors:
# - [10,13, 16,30, 33,23] # P3/8
# - [30,61, 62,45, 59,119] # P4/16
# - [116,90, 156,198, 373,326] # P5/32
4.10. 其他疑问
通过完整图片(385x385)训练得到权重模型,再用该模型测试裁剪后的图片(150x150),发现检测不到结果。
plt.savefig后,图像shape改变怎么办?
plt.savefig后,图像尺寸从 150x150 变成 369x369
150x150
369x369
经过如下操作,打印出来尺寸是 115x115 的图片,依然不是150x150 。
pic = imageio.imread(path + png_name)[30:180,170:320]
fig,ax = plt.subplots(figsize=(1,1))
plt.axis('off')
plt.imshow(pic)
plt.savefig(save_path_img_fliter, bbox_inches='tight',pad_inches = 0,dpi=150 )
总之,问题暂未解决
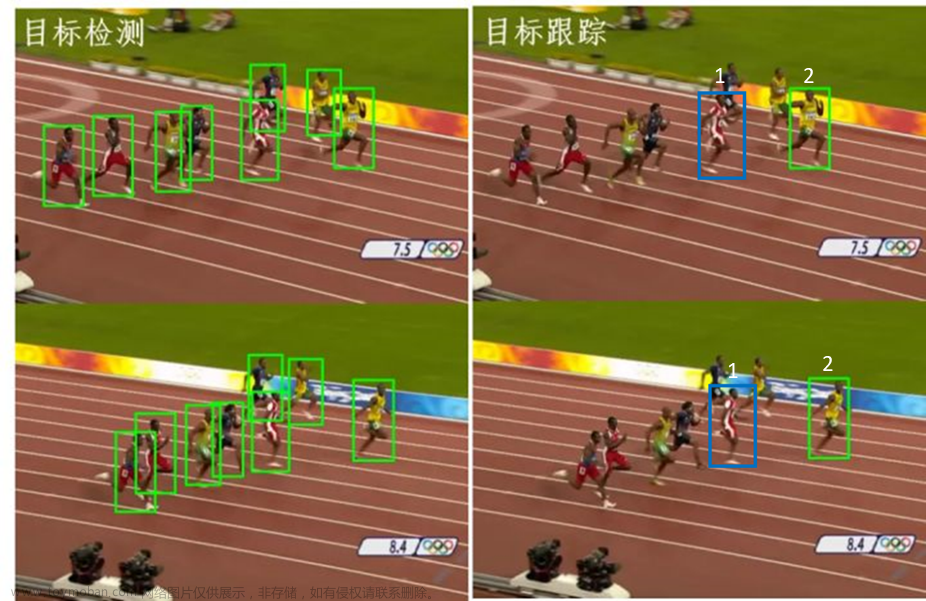
5. 目标跟踪-DeepSORT
以下简称DeepSORT为dps
5.1. dps简介
5.1.1. 常见名词
ReID
ReID,也就是 Re-identification,其定义是利用算法,在图像库中找到要搜索的目标的技术,所以它是属于图像检索的一个子问题。 在监控拍不到人脸的情况下,ReID可以替代传统人工查询和人脸识别在视频序列当中找到目标对象。
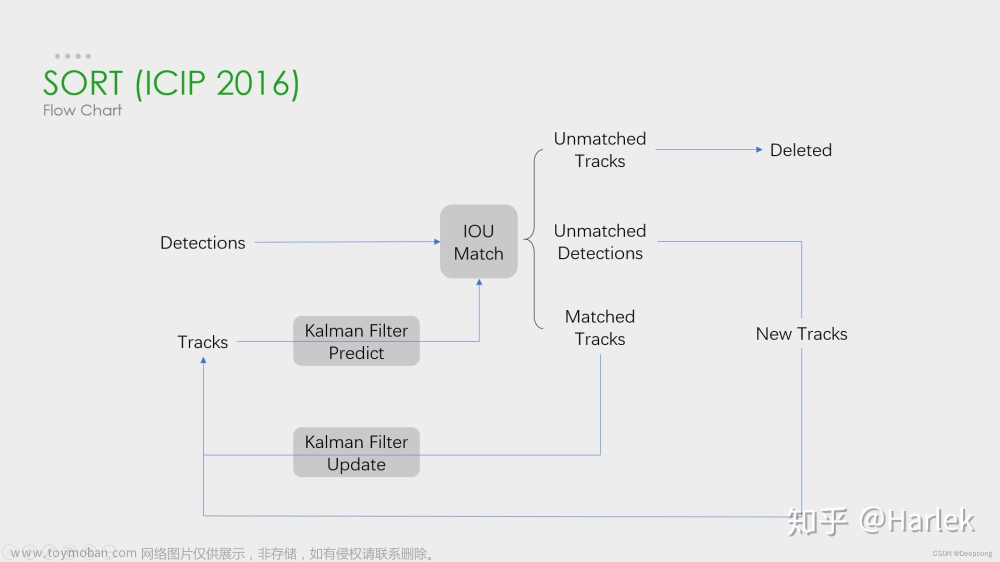
5.1.2. 原理
(1)给定视频原始帧
(2)目标检测器(Faster R-CNN, yolov5, SSD等)获取目标检测框
(3)将目标框中对应的目标抠出来,进行特征提取(包括外观特征和运动特征)
(4)相似度计算,计算前后两帧目标间的匹配程度(前后属于同一目标的距离小,不同目标的距离较大)。
(5)数据关联,为每个对象分配目标ID。
【ref】deepsort原理快速弄懂——时效比最高的
对dps工作流程的描述言简意赅
5.2. dps训练集
5.2.1. 目标
对于多目标跟踪,无论是单分类还是多分类,为了训练**“外观特征提取网络”**(deepsort相较于sort特有的),我们需要为每一个目标建立一个图片集,为每个独特的个体训练独特的特征(不一定是每个,也可以是每类)。
以cell训练集为例,训练集中的一个目标指的就是一个细胞,虽然他们都属于cell类,但是具体到某一个细胞,可能会发现他哪里比较大,哪里有一个棱角,这就需要多张图片来训练。总之,为每一个cell个体都创建一个train和test集,就可以更好地区分不同的细胞。
不过,在比较简单的场景中,如果每一个cell长得真得很像,没有分类的必要;或者你觉得数据好,跟踪难度不大,运动特征就足够追踪了,不想浪费资源在外观特征上,那就可以随便放一个文件夹,取名为“今天我一个人代表所有人”,只用它来训练就好了。
从这个角度来看,下面的koutu.py文件和fenlei.py文件的输入数据的单元应该是一张大图,这个大图中只有那只cell,而且还得有好多只那只cell。
5.2.2. 新建cuts文件夹
建议放在images和labels文件夹的同级目录下
5.2.3. 抠图
使用代码koutu.py,把检测框从图片中抠出来
import cv2
import xml.etree.ElementTree as ET
import numpy as np
import xml.dom.minidom
import os
import argparse
def main():
# JPG文件的地址
img_path = r'D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\images\val\\'
# XML文件的地址
anno_path = r'D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\labels\val\\'
# 存结果的文件夹
cut_path = r'D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\cuts\\'
if not os.path.exists(cut_path):
os.makedirs(cut_path)
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
# print(imagelist
for image in imagelist:
image_pre, ext = os.path.splitext(image)
img_file = img_path + image
img = cv2.imread(img_file)
xml_file = anno_path + image_pre + '.xml'
# DOMTree = xml.dom.minidom.parse(xml_file)
# collection = DOMTree.documentElement
# objects = collection.getElementsByTagName("object")
tree = ET.parse(xml_file)
root = tree.getroot()
# if root.find('object') == None:
# return
obj_i = 0
for obj in root.iter('object'):
obj_i += 1
print(obj_i)
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
b = [int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)),
int(float(xmlbox.find('xmax').text)),
int(float(xmlbox.find('ymax').text))]
img_cut = img[b[1]:b[3], b[0]:b[2], :]
path = os.path.join(cut_path, cls)
# 目录是否存在,不存在则创建
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(path)
# 注意,图片名不能含‘_’,否则最后只会生成一个类别的文件夹,而不是多类别的文件夹
image_pre = image_pre.replace('_','')
print(image_pre, obj_i)
try:
cv2.imwrite(os.path.join(cut_path, cls, '{}_{:0>2d}.jpg'.format(image_pre, obj_i)), img_cut)
except:
continue
print("&&&&")
if __name__ == '__main__':
main()
koutu.py代码生成的图片如下,其中每张图片都是一个检测框分割出来的图片,它们将被存放在一个自动生成的particle文件夹中
另外要注意,图片名在最后一个下划线符号前不能有其他下划线符号,否则会导致后续的fenlei.py代码分类出错。
5.2.4. 分集
使用代码feilei.py,把训练框图分为训练集和测试集
import os
from PIL import Image
from shutil import copyfile, copytree, rmtree, move
PATH_DATASET = 'D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\cuts\particle' # 需要处理的文件夹
PATH_NEW_DATASET = 'D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_label\cuts\cuts_split' # 处理后的文件夹
PATH_ALL_IMAGES = PATH_NEW_DATASET + '\\all_images'
PATH_TRAIN = PATH_NEW_DATASET + '\\train'
PATH_TEST = PATH_NEW_DATASET + '\\test'
# 定义创建目录函数
def mymkdir(path):
path = path.strip() # 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符号
isExists = os.path.exists(path) # 判断路径是否存在
if not isExists:
os.makedirs(path) # 如果不存在则创建目录
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = PATH_DATASET # 表示需要命名处理的文件夹
# 修改图像尺寸
def resize(self):
for aroot, dirs, files in os.walk(self.path):
# aroot是self.path目录下的所有子目录(含self.path),dir是self.path下所有的文件夹的列表.
filelist = files # 注意此处仅是该路径下的其中一个列表
# print('list', list)
# filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(aroot), item)
# 修改图片尺寸到128宽*256高
im = Image.open(src)
out = im.resize((128, 256), Image.ANTIALIAS) # resize image with high-quality
out.save(src) # 原路径保存
def rename(self):
for aroot, dirs, files in os.walk(self.path):
# aroot是self.path目录下的所有子目录(含self.path),dir是self.path下所有的文件夹的列表.
filelist = files # 注意此处仅是该路径下的其中一个列表
# print('list', list)
# filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
i = 1 # 表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(aroot), item)
# 根据图片名创建图片目录
dirname = str(item.split('_')[0])
# 为相同车辆创建目录
# new_dir = os.path.join(self.path, '..', 'bbox_all', dirname)
new_dir = os.path.join(PATH_ALL_IMAGES, dirname)
if not os.path.isdir(new_dir):
mymkdir(new_dir)
# 获得new_dir中的图片数
num_pic = len(os.listdir(new_dir))
dst = os.path.join(os.path.abspath(new_dir),
dirname + 'C1T0001F' + str(num_pic + 1) + '.jpg')
# 处理后的格式也为jpg格式的,当然这里可以改成png格式 C1T0001F见mars.py filenames 相机ID,跟踪指数
# dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg') 这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式
try:
copyfile(src, dst) # os.rename(src, dst)
print('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print('total %d to rename & converted %d jpgs' % (total_num, i))
def split(self):
# ---------------------------------------
# train_test
images_path = PATH_ALL_IMAGES
train_save_path = PATH_TRAIN
test_save_path = PATH_TEST
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
os.mkdir(test_save_path)
for _, dirs, _ in os.walk(images_path, topdown=True):
for i, dir in enumerate(dirs):
for root, _, files in os.walk(images_path + '/' + dir, topdown=True):
for j, file in enumerate(files):
if (j == 0): # test dataset;每个车辆的第一幅图片
print("序号:%s 文件夹: %s 图片:%s 归为测试集" % (i + 1, root, file))
src_path = root + '/' + file
dst_dir = test_save_path + '/' + dir
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
dst_path = dst_dir + '/' + file
move(src_path, dst_path)
else:
src_path = root + '/' + file
dst_dir = train_save_path + '/' + dir
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
dst_path = dst_dir + '/' + file
move(src_path, dst_path)
rmtree(PATH_ALL_IMAGES)
if __name__ == '__main__':
demo = BatchRename()
demo.resize()
demo.rename()
demo.split()
feilei.py文件生成的文件如下
5.2.5. 移动
将train和test移动到deep_sort/deep目录下。
5.3. dps框架修缮
第一步,修改train.py中train dataset的预处理操作
transform_train = torchvision.transforms.Compose([
torchvision.transforms.Resize((128, 64)),
torchvision.transforms.RandomCrop((128, 64), padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
第二步,修改权重保存路径
torch.save(checkpoint, './checkpoint/ckpt1.t7')
第三步,在model.py中修改类别数num_classes
class Net(nn.Module):
def __init__(self, num_classes= 1 ,reid=False):
super(Net,self).__init__()
# 3 128 64
self.conv = nn.Sequential(
nn.Conv2d(3,64,3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# nn.Conv2d(32,32,3,stride=1,padding=1),
# nn.BatchNorm2d(32),
# nn.ReLU(inplace=True),
nn.MaxPool2d(3,2,padding=1),
)
5.4. dps调参
若不追求精度,可跳过本节
5.4.1. 跟踪框参数
调跟踪框大小、颜色等
【ref】python opencv cv2.rectangle 参数含义
5.4.2. 其他参数
调yaml中的参数
【ref】deepSORT目标检测框架参数设置
直接介绍yaml参数的定义
其他训练技巧
【ref】deepsort训练车辆特征参数
使用537个车辆数据集ID数;提到了很多训练技巧
5.5. dps训练
问题:
deepsort训练的目的是?它是在训练什么东西?
回答:
训练神经网络以提取跟踪对象的形态特征
训练命令:
python train.py --data-dir D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\deep_sort\deep )
)
5.6. dps检测
cd D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\
视频地址:
D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_video\fliter_result.gif
yolo权重地址:
D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5\runs\exp12\weights\best.pt
deep_sort权重地址:
D:\JoeOffice\jupyter_notebook\computer_vision\small_object_track\my_yolo\Yolov5-Deepsort-main\deep_sort\deep_sort\deep\checkpoint\ckpt_particle.t7
观察deepsort框架main.py文件中参数的格式,发现跟踪的权重应该放在config文件里,如果直接写权重地址,会发生格式错误的情况,想在参数这栏改好,几乎是天方夜谭的,所以应该直接到config里去改

正确命令:
python main.py --input_path --weights
即:python main.py --input_path D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\PEG\PEG_video\fliter_result.gif --weights D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\yolov5\runs\exp12\weights\best.pt

跟踪结果带编号,如下所示:
N_INIT: 1
N_INIT: 3
5.7. 报错
错误命令:python main.py --weights 你的yolo权重 --input_path 你的视频 --config_deepsort 你的deepsort权重 --device cpu --save-vid
这说明无法解析args中的参数,一般可能是路径出错,前文提到deepsort路径应该写在config而不是参数中,否则不能解析。
6. 跟踪评价-参考MOT数据集
6.1. 参考文献
多目标跟踪评价指标
https://zhuanlan.zhihu.com/p/366855898
mot数据集
https://blog.csdn.net/weixin_42300418/article/details/112162067
mot数据集格式
https://www.cnblogs.com/codingbigdog/p/16522411.html
darklabel教程
https://zhuanlan.zhihu.com/p/430965819
darklable按钮详解
https://blog.csdn.net/weixin_43611754/article/details/127956436
darklabel视频
https://www.bilibili.com/video/BV1Vb4y187pM/?spm_id_from=333.337.search-card.all.click&vd_source=89d33093b3c31564cd844b3e79889e3b
MOT多目标跟踪评价指标代码py-motmetrics
https://blog.csdn.net/sleepinghm/article/details/119538354
deepsort如何得到标准的gt文件?
deepsort和MOT16指标评价
https://blog.csdn.net/weixin_44238733/article/details/124148469
MOT官方评估工具安装与使用+py-motmetrics Python版本评估程序使用
https://blog.csdn.net/qq_51682716/article/details/120012932
6.2. 评价指标
MOT有如下四个基础的评价指标:
- MT(Mostly Tracked):满足Ground Truth至少在80%的时间内都匹配成功的tracks,在所有追踪目标中所占的比例。
- ML(Mostly Lost):满足Ground Truth仅在小于20%的时间内匹配成功的tracks,在所有追踪目标中所占的比例。
- ID Switch:Ground Truth所分配的ID发生变化的次数。
- FM(Fragmentation):计算跟踪有多少次被打断,即ground truth的状态为:tracked -> untracked -> tracked
基于上述四个基础指标,还可以将他们组合成MOTA(MOT Accuracy)指标和MOTP(MOT Precision)指标,前者可以衡量检测物体和保持轨迹方面的性能,后者可以衡量定位精度。
【ref】K. Bernardin and R. Stiefelhagen, “Evaluating multiple object tracking performance: The CLEAR MOT metrics,” EURASIP J. Image Video Process, vol. 2008,2008.
6.3. darklabel手工标注
需要对视频每一帧做手动标注,生成pt文件
6.4. 评价结果
具体见“py-motmetrics.py”评估工具
python eval_motchallenge.py D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\output\gt D:\JoeOffice\jupyter_notebook\computer_vision\particle_track\track4-DeepSORT_YOLOv5_Pytorch\output\predict
如下,结果暂未跑通,待续…文章来源:https://www.toymoban.com/news/detail-730688.html
 文章来源地址https://www.toymoban.com/news/detail-730688.html
文章来源地址https://www.toymoban.com/news/detail-730688.html
到了这里,关于【CV\tracking】多目标跟踪(OpenCV+YOLO+DeepSORT)|| 项目实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!