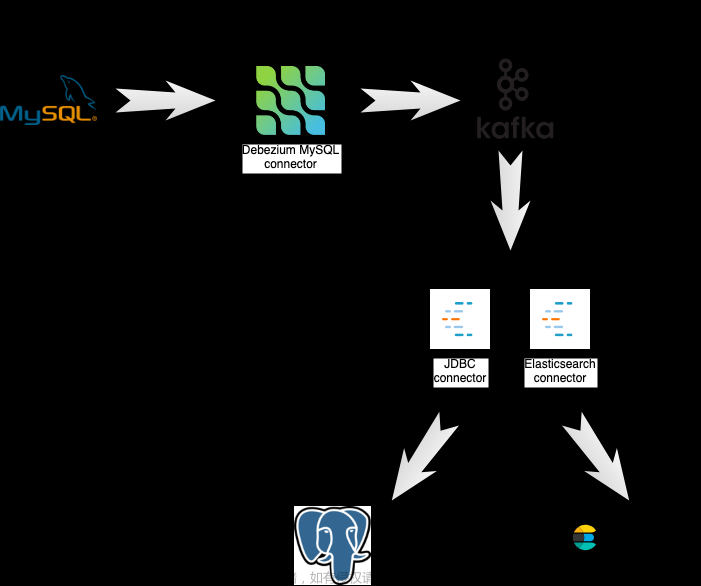
前言
本文记录基于 Docker 容器化技术将 Elasticsearch 集群搭建 + ELFK 数据传输链路打通过程。
一、ELFK 介绍
1.1 ElasticSearch
ES 是基于 Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志。ES 是用 JAVA 开发的,可通过 RESTful Web 接口,让用户可以通过浏览器与 ES 通信。ES 是个分布式搜索和分析引擎,优点是能对大容量的数据进行接近实时的存储、搜索和分析操作。
1.2 Logstash
Logstash 作为数据收集引擎。它支持动态的从各种数据源搜索数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给 ES。
Logstash 由 JRuby 语言编写,运行在 JVM 上,是一款强大的数据处理工具,可以实现数据传输、格式处理、格式化输出。Logstash 具有强大的插件功能,常用于日志处理。
1.3 Kibana
Kibana 是基于 Node.js 开发的展示工具,可以为 Logstash 和 ES 提供图形化的日志分析 Web 界面展示,可以汇总、分析和搜索重要数据日志。
1.4 Filebeat
Filebeat 是一款轻量级的开源日志文件数据搜索器。通常在需要采集数据的客户端安装 Filebeat 并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进行解析,或是直接发给 ES 存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。
1.5 ELFK 使用原因
● 日志主要包括日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
● 往往单台机器的日志我们使用 grep,awk 等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅汇总,集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情。一般我们使用 grep,awk 和 wc 等 Linux 命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
● 一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
1.6 日志系统的基本特征
● 收集:能够采集多种来源的日志数据
● 传输:能够稳定的把日志数据解析过滤并传输到存储系统
● 存储:存储日志数据
● 分析:支持UI分析
● 警告:能够提供错误报告,监控机制
1.7 ELFK 工作原理
● Filebeat 将日志收集后交由 Logstash 处理
● Logstash 进行过滤、格式化等操作,满足过滤条件的数据将发送给 ES
● ES 对数据进行分片存储,并提供索引功能
● Kibana 对数据进行图形化的 Web 展示,并提供索引接口
二、Docker 安装部署 ELFK
2.1 数据流向
简单流程:Filebeat 会定时监听事先指定的日志文件,如果日志文件有变化,会将数据推送至 Logstash,Logstash 通过配置进行过滤筛选存入 ES,最终通过 Kibana 将数据呈现出来。
数据流向: FileBeat -> Logstash -> Elasticsearch -> Kibana
2.2 前置准备
准备这三台服务器:192.168.6.230,192.168.6.238,192.168.6.241 搭建ES集群。
| IP 地址 | 服务器 | 部署服务 |
|---|---|---|
| 192.168.6.238 | es-node-1 | ES,Kibana,Logstash,Filebeat |
| 192.168.6.230 | es-node-2 | ES |
| 192.168.6.241 | es-node-3 | ES |
2.3 ES 集群搭建
1.准备好 ES 的宿主机上的映射路径赋予最高权限
cd /data
#data:存放数据的目录 config:存放配置文件的目录 plugins:存放插件的目录
mkdir elasticsearch
mkdir -p /data/elasticsearch/config
mkdir -p /data/elasticsearch/data
echo "http.host: 0.0.0.0" >> /data/elasticsearch/config/elasticsearch.yml
#递归式赋权
chmod 777 -R /data/elasticsearch/
cd elasticsearch/config/
vim elasticsearch.yml
#点击i进入插入模式,粘贴如下数据后 esc+shift+: wq 保存退出
http.host: 0.0.0.0
cluster.name: es-cluster
node.name: es-node-1
network.bind_host: 0.0.0.0
network.publish_host: 192.168.6.238
http.port: 9200
transport.tcp.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
discovery.seed_hosts: ["192.168.6.238:9300","192.168.6.230:9300","192.168.6.241:9300"]
cluster.initial_master_nodes: ["192.168.6.238:9300","192.168.6.230:9300","192.168.6.241:9300"]
| 参数 | 说明 |
|---|---|
| cluster.name | 集群名称,相同名称为一个集群 |
| node.name | 节点名称,集群模式下每个节点名称唯一 |
| network.bind_host | 监听地址,用于访问该es |
| network.publish_host | 可设置成内网ip,用于集群内各机器间通信 |
| http.port | es对外提供的http端口,默认 9200 |
| transport.tcp.port | 端口号,默认是9300-9400 |
| http.cors.enabled | 是否支持跨域,是:true,在使用head插件时需要此配置 |
| http.cors.allow-origin | *表示支持所有域名 |
| node.master | 当前节点是否可以被选举为master节点,是:true、否:false |
| node.data | 当前节点是否用于存储数据,是:true、否:false |
| discovery.seed_hosts | es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 |
| cluster.initial_master_nodes | es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master |
下载 Elasticsearch 镜像
docker pull elasticsearch:7.4.2
运行容器
docker run --name elasticsearch --restart always \
-p 9200:9200 -p 9300:9300 \
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" \
-v /data/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /data/elasticsearch/data:/usr/share/elasticsearch/data \
-v /data/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
JVM堆内存大小建议设置大一点,不然可能会报错,建议堆内存设置至少 256M 以上。
#查看运行的容器
docker ps -a
#若发现是 STATUS 是 Exited 可以查看日志
docker logs 容器id
{"type": "server", "timestamp": "2023-08-18T06:24:55,734Z", "level": "INFO", "component": "o.e.b.BootstrapChecks", "cluster.name": "es-cluster", "node.name": "es-node-2", "message": "bound or publishing to a non-loopback address, enforcing bootstrap checks" }
ERROR: [1] bootstrap checks failed
启动报错,可以查看这篇文章:文章地址,调高JVM线程数限制数量
vim /etc/sysctl.conf
->>
vm.max_map_count=262144
# 刷新配置
sysctl -p
在每台机器上分别执行以上步骤:注意配置 yml 文件时记得修改 network.publish_host 和 node.name
2.4 Kibana 环境搭建
下载 Kibana 镜像
docker pull kibana:7.4.2
启动容器
docker run --name kibana --restart always \
-e ELASTICSEARCH_HOSTS=http://192.168.6.238:9200 \
-p 5601:5601 \
-d kibana:7.4.2
进入 kibana 容器控制台,新增配置
[root@huang.bx ~]# docker exec -it kibana /bin/bash
bash-4.2$ ls
LICENSE.txt NOTICE.txt README.txt bin built_assets config data node node_modules optimize package.json plugins src webpackShims x-pack
bash-4.2$ cd config/
bash-4.2$ ls
kibana.yml
bash-4.2$ cat kibana.yml
#
# ** THIS IS AN AUTO-GENERATED FILE **
#
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0.0.0.0"
# elasticsearch 集群地址
elasticsearch.hosts: ["http://192.168.6.238:9200","http://192.168.6.230:9200","http://192.168.6.241:9200"]
xpack.monitoring.ui.container.elasticsearch.enabled: true
# Kibana 界面中文显示
i18n.locale: "zh-CN"
查看 ES 集群节点信息
[root@huang.bx ~]# curl http://192.168.6.238:9200/_cat/nodes?pretty
192.168.6.230 34 43 1 0.12 0.11 0.11 dilm * es-node-3
192.168.6.241 63 82 0 0.05 0.05 0.05 dilm - es-node-2
192.168.6.238 33 80 16 3.85 3.54 3.21 dilm - es-node-1
安装 ik 分词器,参考文章:文章地址,分别安装在这三台机器上
2.5 Filebeat 环境搭建
下载 Filebeat 镜像
docker pull docker.elastic.co/beats/filebeat:7.4.2
运行容器
docker run --name filebeat --restart always \
-v /data/filebeat/log:/var/log/filebeat \
-v /data/filebeat/config/filebeat.yml:/usr/share/filebeat/filebeat.yml \
-v /nas/logs:/nas/logs \
-d docker.elastic.co/beats/filebeat:7.4.2
查看容器运行状态,发现是 restarting
[root@bogon config]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
47847caf2c1a docker.elastic.co/beats/filebeat:7.4.2 "/usr/local/bin/dock…" 7 seconds ago Restarting (1) 2 seconds ago
查看 filebeat 运行日志
[root@bogon config]# docker logs filebeat
2023-09-01T05:39:56.184Z INFO instance/beat.go:607 Home path: [/usr/share/filebeat] Config path: [/usr/share/filebeat] Data path: [/usr/share/filebeat/data] Logs path: [/usr/share/filebeat/logs]
2023-09-01T05:39:56.191Z INFO instance/beat.go:615 Beat ID: 45712b1b-e90f-43a4-b33e-ae5c7822fb16
2023-09-01T05:39:56.191Z INFO instance/beat.go:366 filebeat stopped.
2023-09-01T05:39:56.191Z ERROR instance/beat.go:878 Exiting: error initializing processors: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
Exiting: error initializing processors: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
2023-09-01T05:39:56.569Z INFO instance/beat.go:607 Home path: [/usr/share/filebeat] Config path: [/usr/share/filebeat] Data path: [/usr/share/filebeat/data] Logs path: [/usr/share/filebeat/logs]
2023-09-01T05:39:56.569Z INFO instance/beat.go:615 Beat ID: 45712b1b-e90f-43a4-b33e-ae5c7822fb16
2023-09-01T05:39:56.571Z INFO instance/beat.go:366 filebeat stopped.
2023-09-01T05:39:56.571Z ERROR instance/beat.go:878 Exiting: error initializing processors: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?
发现是自己配置 filebeat.yml 有问题
[root@bogon config]# cat filebeat.yml
filebeatt.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
processors:
- add_cloud_metadata: ~
- add_docker_metadata: ~
filebeat.inputs:
- type: log
enabled: true
paths:
- /nas/logs/zuul/zuul-test-prod-*.log
fields:
document_type: zuul
output:
logstash:
hosts: ["172.16.6.238:5044"]
需要重网上下载 filebeat.yml 默认配置文件,拷贝到 config 目录下,重新运行容器就可以了。
2.6 Logstash 环境搭建
下载 Logstash:根据自己ES,FileBeat,Kibana 版本下载 Logstash(最好版本都一致)Logstash下载链接
创建 logstash 安装目录
cd /data
mkdir logstash
解压安装包
cd logstash
tar zxvf logstash-7.4.2.tar.gz
配置 logstash 配置文件
cd logstash-7.4.2/config/
touch logstash.conf
vim logstash.conf
input {
beats {
port => 5044
client_inactivity_timeout => 36000
}
}
filter {
}
output {
elasticsearch {
hosts => ["192.168.6.238:9200","192.168.6.230:9200","192.168.6.241:9200"]
index => "zuul"
document_type => "%{[@metadata][type]}"
sniffing => true
template_overwrite => true
}
stdout {
codec => rubydebug
}
}
后台启动
cd /data/logstash/logstash.7.4.2
nohup bin/logstash -f config/logstash.conf &
查看 Kibana 界面,日志成功输出到 ES文章来源:https://www.toymoban.com/news/detail-730965.html
 文章来源地址https://www.toymoban.com/news/detail-730965.html
文章来源地址https://www.toymoban.com/news/detail-730965.html
到了这里,关于Elasticsearch集群搭建 + ELFK数据传输链路打通的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!