分享40个Python源代码总有一个是你想要的
源码下载链接:https://pan.baidu.com/s/1PNR3_RqVWLPzSBUVAo2rnA?pwd=8888
提取码:8888
下面是文件的名字。
dailyfresh-天天生鲜
Django-Quick-Start
freenom-自动续期域名的脚本
Full Stack Python简体中文翻译项目
GLaDOS 自动签到⚡
izone后台管理
learndemo
learn_python3_spider
Mini-Python
monitor-linux监控
peeplus 后台管理系统
PHP调用Python程序
Python 代码、单元测试和项目规范
Python 音频加密解密工具库
python-selenium2-master
PythonCrawler
python_code_audit-master
Python爬虫从入门到实战2
python爬虫实战日记
Python爬虫数据分析
Python爬虫订票
Python爬虫项目demo
python的WebUI自动化测试
Python编程与实战 上有关项目实战的代码
Python项目-打外星人游戏

walle-web框架
亁颐堂乾颐盾Python网络编程PyQYT项目
今日热榜项目TopList的Python实现
使用Flask的Python项目
匠果招聘
区块链论坛项目BBS
基于flask的博客系统
基于Python的一些项目
小的python项目
广东邮证app 查询 身份证ems邮寄记录
新冠疫情&电商订单分析bigdata_analyse-main
有趣的Python爬虫和数据分析小项目
毕业设计 --外包项目网站
简单的招聘网站示例
计算机视觉小项目
import os
import shutil
def void_folder(path):
# 访问path路径下的文件或文件夹
lst = os.listdir(path)
# 打印每一层的文件或文件夹
for name in lst:
# 拼接名称,得到绝对路径,判断该文件是否符合是文件夹
real_path = os.path.join(path, name)
# 如果是文件夹,则打空格表示,并且递归访问下一层
if os.path.isdir(real_path):
# print(name)
files = os.listdir(real_path)
if len(files) == 0:
print("void_folder():"+name)
shutil.rmtree(real_path)
endindex = len(real_path) - len(name)
real_path = real_path[0:endindex]
void_folder(real_path)
else:
void_folder(real_path)
# 如果不是文件夹,直接打印,不再递归访问下一层
else:
#print(name)
pass
def void_file(dirPath):
dirs = os.listdir(dirPath) # 查找该层文件夹下所有的文件及文件夹,返回列表
for file in dirs:
file_full_name = dirPath + '/' + file
file_ext = os.path.splitext(file_full_name)[-1]
if file_ext is None or file_ext=="":
continuewalle-web框架
- 类
gitlab的RESTful API,类gitlab的权限模型。将来打通gitlab,良心的惊喜 - 空间管理。意味着有独立的空间资源:环境管理、用户组、项目、服务器等
- 灰度发布。呼声不断,终于来了
- 项目管理。Deploy、Release的前置及后置hook,自定义全局变量;自带检测、复制功能,都贴心到这种程度了
websocket实时展示部署中的shell console,跟真的终端长得一样。- 完善的通知机制。邮件、钉钉
- 全新的UI,我自己都被震撼到了,如丝般流畅
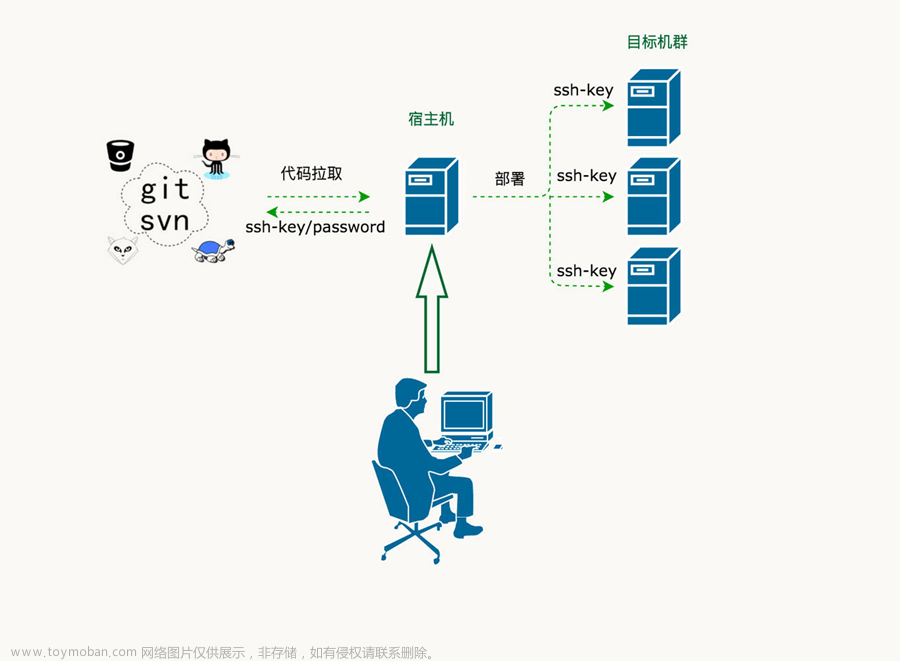
learndemo
- roncoo-pay-dubbo 基于dubbo的微服务分布式事务解决方案
- spring-cloud-microservice-in-action spring cloud 例子
- ctoedu-dubbo dubbo rest
- ctoedu-dubbo-demo 使用dubbo注解方式
- mybatis 简单的mybatis例子(初学)
- ctoedu-ldap 基于ldap实现
- ctoedu-jap-example jpa 多对多 一对多等映射例子
- ctoedu-oauth spring security oauth2 实现认证
- cto-edu-springboot-demo-two 例子:缓存(redis ehcache)/ 发送邮件 /spring security /rabbitmq
- ctoedu-ThreadPool-TaskExecutor 线程池异步阻塞调用
- ctoedu-redis redis 线程池 管道
- ctoedu-rabitmq rabitmq 使用
- elasticsearch-analysis-ik-5.2.0 ik分词器支持乐加载
- p3test python 接口测试
izone后台管理
说明
项目功能是 上传图片视频并分类展示 图床使用的是七牛云,可自行注册并开通内容存储 项目未上传本地配置常量文件 local_settings.py 内容如下
QINIU_AK = 'ak'
QINIU_SK = 'sk'
QINIU_BUCKET = '七牛云存储镜像'
QINIU_DOMAIN = '七牛云存储域名'
TMP_FILE_NAME = 'clipboard.png'
SQLPWD = "mysql的密码"
项目使用
- 启动mysql和redis
- 首先创建一个数据库名为
izone - 在系统/目录下创建 data/upload 目录
- 依次执行下面命令
pip install -r req.txt
python manage.py db init
python manage.py db migrate
python manage.py db upgrade
# 如果以上都没有问题
python manage.py runserver
peeplus 后台管理系统
- 项目说明
1、基于flask和vue打造的前后端分离项目
2、前后端只依赖于token
3、前端vue动态路由
- 前端项目路径: ~@/app/templates/frontEnd
- 后端路径:~@/app
Python爬虫数据分析
Python_Crawler:Python爬虫和Python数据分析小项目
简介
可以用Python实现的小项目,内容包括Python爬虫、Python数据分析等,持续更新中。
本Repository主要用于存放项目代码,对应的项目文章可以关注CSDN博客。
博客地址:curd_boy_数据分析与数据挖掘,爬虫项目,后端开发-CSDN博客
微信:why19970628
欢迎与我交流 😊
1.普通的爬虫项目介绍
- Sina_Topic_Spider:
- 内容: 爬取某位明星的微博超话的上万条用户信息,对爬取的结果进行EDA分析与数据可视化,如分析用户年龄,性别分布、粉丝团的地区分布,词云打榜微博内容。
- 对应CSDN文章:《爬取新浪微博某超话用户信息》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★★☆☆
- LaGou:
- 内容: 爬取拉勾网的职位的信息,爬取方式通过静态和动态网页,对爬取的结果进行EDA分析与数据可视化。
- 对应CSDN文章:《Python爬虫实战之爬取拉勾网职位》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★★☆☆
- ele_me:
- 内容: 爬取饿了么某地区的外卖信息,并对外卖商铺信息、商品数据进行初步可视化。
- 对应CSDN文章:《Python爬虫实战之爬取饿了么信息》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★★☆☆
- DangDang_Books:
- 内容:爬虫:当当网图书书名、书图、价格、简介、评分、评论数量等大约1000条Python图书数据。数据分析:图书评论数量分布的漏斗图、价格分布的柱状图、评论量Top、图书图片墙等可视化展示。(代码截止2019-08-25测试无误)
- 对应CSDN文章:《当当网图书爬虫与数据分析》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- LianJia:
- 内容:多线程爬取链家的北京每个地区的所有小区的信息数据。
- 对应CSDN文章:《爬取链家的小区信息》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- 51_job:
- 内容: 爬取51job前程无忧简关于数据分析的职位信息,并对获取的数据进行数据清洗与分析,如各城市招聘岗位数、薪资与各城市工作地点数量,关系,学历,经验要求等关系、公司类型与对应岗位数、职位要求等可视化。
- 对应CSDN文章:《爬取51job前程无忧简历》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★★☆☆
- Baidu_Music:
- 内容: 批量下载百度音乐(千千音乐)任意歌手的所有歌曲。
- 对应CSDN文章:《爬取百度音乐歌曲》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- QiDian_Story:
- 内容: 批量下载起点中文小说网的所有小说,自动生成对应小说文件夹,并获取某一文件夹下含有某字符结尾的文件信息。
- 对应CSDN文章:《爬取起点小说》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- DouBan_Movie:
- 内容: 利用正则爬取豆瓣电影所有标签下的电影详情,数据导入数据库,并批量生成词云图。
- 对应CSDN文章:《Python爬虫实战之爬取豆瓣详情以及影评》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- taobao_photo:
- 内容: 批量下载淘宝搜索页面(代码截止2019-08-26测试无误)。
- 对应CSDN文章:《博客地址》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- 高考网:
- 内容: 爬取高考网所有大学信息,对爬取的结果进行数据分析与数据可视化,如分析大学数量、地区分布、985 211地区分布、高校类型与属性分布等,初步分析我国高等教育分布的不均衡问题。
- 对应CSDN文章:《爬取新浪微博某超话用户信息》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- Movie_tiantang:
- 内容: 下载电影天堂最新电影数据(代码截止2019-08-28测试无误)。
- 对应CSDN文章:《博客地址》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- yixuela.com:
- 内容: 下载易学啦各个版本所有图书信息(代码截止2020-08-27测试无误)。
- 难度:★★☆☆☆
2.selenium框架自动化爬虫项目介绍
- taobao:
- 内容: 爬取淘宝搜索美食的所有页面,并存入mysql/mongodb数据库,并对美食数据进行商品标题、销量排名与商铺信息、销量的城市排名、店铺所在城市分布情况、商品价格与销售额的关系等探索性数据分析。
- 对应CSDN文章:《selenium爬取淘宝美食信息》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★★☆☆
- Baidu_Address:
- 内容: 利用selenium爬取百度地图的某地区的公司信息,包括公司名称,公司地址等。csv文件大约几十条数据
- 对应博客文章:《博客地址》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- DouYu:
- 内容: 利用selenium爬取斗鱼网所有主播的类别,房间标题,房间ID,主播名称,热度,csv文件大约15000条数据。
- 对应CSDN文章:《博客地址》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
- WangYi_Music:
- 内容: 利用selenium爬取网易云音乐关于许嵩共计175首歌曲信息及歌词信息可视化。
- 对应CSDN文章:《利用selenium爬取网易云音乐歌手歌曲信息并分析》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
3.Scrapy框架爬虫项目介绍
- Qsbk:
- 内容: 利用Scrapy框架爬取糗事百科段子。
- 对应CSDN文章:《利用Scrapy框架爬取糗事百科段子》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者
- 难度:★★☆☆☆
- ChuanZhi_Class:
- 内容: 利用Scrapy框架爬取传智播客课程数据。
- 对应CSDN文章:《利用Scrapy框架爬取传智播客课程数据》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者
- 难度:★★☆☆☆
- DangDang_Books/dangdang:
- 内容:爬虫:利用Scrapy框架爬取当当网搜索界面图书书名、价格、评论数量等信息
- 对应CSDN文章:《当当网图书爬虫与数据分析》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者、数据可视化学习者
- 难度:★★☆☆☆
4.多线程爬虫
- Photo_qiantu:
- 内容:利用线程批量下载千图网的图片(代码截止2019-07-05测试无误)
- 对应CSDN文章:《利用多线程爬取千图网的素材图片》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者
- 难度:★★☆☆☆
- Movie_maoyan:
- 内容: 利用多线程下载猫眼榜单电影电影数据(电影标题,导演,评分,排名,上映时间,电影封面地址等)(代码截止2019-09-04测试无误)。
- 对应CSDN文章:《博客地址》
- 适合人群:Python爬虫学习者、Pandas使用者
- 难度:★★☆☆☆
5.scrapy-redis分布式爬虫
- dangdangbook:
- 内容:利用分布式爬虫, 爬取当当网的图书信息(代码截止2020-06-07测试无误)
- 对应CSDN文章:《博客地址》
- 适合人群:Python爬虫学习者
- 难度:★★★☆☆
6.模拟登录与其他
- Photo_Position_GoldenAPI:
- 内容:调用高德地图的WEB-API接口,获取图片定位(代码截止2019-08-28测试无误)
- 对应CSDN文章:《靠一张图片获取女朋友的定位》
- 适合人群:Python爬虫学习者、Python数据分析学习者、Pandas使用者
- 难度:★★☆☆☆
最后送大家一首诗:文章来源:https://www.toymoban.com/news/detail-731437.html
山高路远坑深,
大军纵横驰奔,
谁敢横刀立马?
惟有点赞加关注大军。
文章来源地址https://www.toymoban.com/news/detail-731437.html
到了这里,关于分享40个Python源代码总有一个是你想要的的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!