深入解析HashMap
问题1: 请解释HashMap是什么,以及它的工作原理是什么?
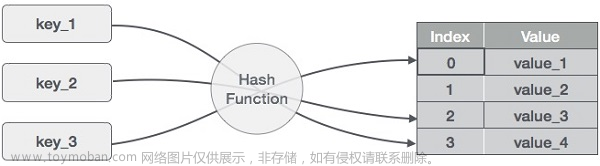
答案: HashMap是Java中常用的集合类之一,用于存储键值对。它基于哈希表(Hash Table)实现,通过将键映射到一个唯一的哈希值,然后将该哈希值映射到数组索引来实现高效的数据访问。当需要插入、查询、删除键值对时,HashMap会根据键的哈希值来定位对应的数组位置,并在该位置上存储或查找数据。
问题2: HashMap中的键和值可以是什么类型?
答案: HashMap的键和值可以是任何引用类型,包括基本数据类型的包装类。键不能重复,即同一个键只能对应一个值,但值可以重复。
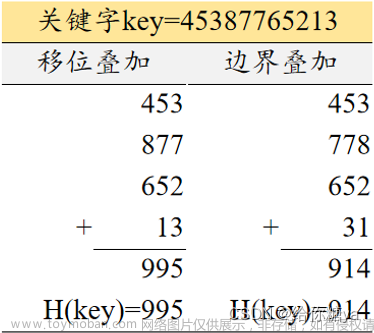
问题3: HashMap的扩容是如何实现的?会有什么影响?
答案: 当HashMap的负载因子(即元素个数与数组长度的比例)超过阈值时,就会触发扩容操作。扩容时,HashMap会创建一个更大的数组,然后将原数组中的元素重新映射到新数组中。这个过程涉及重新计算键的哈希值和重新分配索引位置,可能会导致性能稍微下降,但可以保持较低的负载因子,提高了哈希表的效率。
问题4: HashMap和HashTable的区别是什么?
答案: HashMap和HashTable都是键值对存储的数据结构,但它们有以下主要区别:
线程安全性:HashMap是非线程安全的,HashTable是线程安全的,HashTable的方法都是同步的。 null值:HashMap允许键和值都为null,而HashTable不允许。 性能:由于HashTable的同步机制,其性能通常比HashMap较差。
问题5: 如何处理HashMap中的哈希冲突?
答案: 哈希冲突是指不同的键经过哈希函数计算后,得到了相同的哈希值,从而映射到了相同的数组索引位置。HashMap使用链表或红黑树(Java 8及之后版本)来处理哈希冲突。在数组的每个位置上,都维护一个链表或红黑树,当多个键映射到同一个位置时,它们会以链表或红黑树的形式存储在同一个位置上。
问题6: 在什么情况下会考虑使用HashMap?
答案: 使用HashMap适合需要进行快速插入、删除和查找操作的情况。它是一种高效的数据结构,适用于大多数情况下的键值对存储需求。但在多线程环境下,如果需要考虑线程安全问题,可以选择ConcurrentHashMap。
问题7: 如何遍历HashMap中的键和值?
答案: 可以使用entrySet()方法获得键值对的集合,然后通过迭代器或增强型for循环遍历每个键值对。也可以分别使用keySet()和values()方法获得键集合和值集合,然后进行遍历。
问题8: 为什么在使用HashMap时需要注意键的不可变性?
答案: 在HashMap中,键的哈希值在存储时用于计算索引位置,如果键在存储过程中发生了变化,它的哈希值也会改变,导致无法正确地访问到存储在原位置上的值。因此,为了保证HashMap的正确性,键需要是不可变的,即不会发生变化的对象,如String、包装类型等。
问题9: 什么是负载因子(Load Factor)?它的作用是什么?
答案: 负载因子是HashMap中的一个重要参数,用于衡量已存储元素数量和数组长度之间的比例关系。它的计算方式是:负载因子 = 元素数量 / 数组长度。负载因子的作用是控制数组的填充程度,过高的负载因子可能导致哈希冲突增加,从而降低HashMap的性能。当负载因子超过设定的阈值时,会触发数组扩容,以保持较低的负载因子,提高HashMap的效率。
问题10: 为什么要在HashMap中使用equals()和hashCode()方法?
答案: 在HashMap中,键的查找和匹配是基于hashCode和equals方法进行的。hashCode方法返回键的哈希值,equals方法用于比较两个键是否相等。HashMap使用键的hashCode值来计算存储位置,并使用equals方法来处理哈希冲突。因此,如果不正确地实现这两个方法,可能会导致无法正确地存储、查找和比较键值对。
问题11: 什么是HashMap的初始容量?为什么要设置初始容量?
答案: 初始容量是HashMap在创建时分配的初始数组大小。设置初始容量可以影响HashMap的性能。如果初始容量设置过小,可能会导致频繁的扩容操作,增加性能开销。如果初始容量设置过大,会浪费内存空间。因此,根据实际数据量和使用情况,选择合适的初始容量是很重要的。
问题12: 如何实现自定义对象作为HashMap的键?
答案: 要自定义对象作为HashMap的键,需要保证这个对象满足以下条件:
实现hashCode()和equals()方法:确保能够正确计算哈希值和比较对象是否相等。 最好使对象不可变:避免在对象作为键的过程中发生变化,影响哈希值和比较结果。
问题13: 在多线程环境下,如何保证HashMap的安全性?
答案: HashMap本身并不是线程安全的,如果在多线程环境下同时进行读写操作,可能会导致不一致性。为了保证安全性,可以采取以下方法:
使用ConcurrentHashMap,它是线程安全的哈希表实现。 使用显示的同步机制,如synchronized来保护HashMap的操作。 使用并发集合代替HashMap,如ConcurrentHashMap或CopyOnWriteHashMap。
问题14: 如何实现HashMap的迭代?
答案: 可以使用entrySet()方法获得键值对的集合,然后通过迭代器或增强型for循环遍历每个键值对。也可以分别使用keySet()和values()方法获得键集合和值集合,然后进行遍历。需要注意的是,当HashMap的结构发生变化(例如插入、删除操作)时,迭代过程可能会出现ConcurrentModificationException异常,可以通过使用迭代器的方式来避免这个问题。
问题15: HashMap中的数组容量为什么要是2的幂次方?
答案: HashMap中的数组容量(即数组的长度)为2的幂次方有助于优化哈希值的映射计算。在计算哈希值对应的数组索引时,采用取模运算(hash & (length - 1))来保证计算结果落在数组范围内。当数组容量是2的幂次方时,length - 1的二进制表示中只有一个位是1,其余位都是0,这可以使位运算更高效,减少哈希冲突。
问题16: 什么是ConcurrentHashMap?
答案: ConcurrentHashMap是Java中的线程安全的哈希表实现,用于解决多线程环境下HashMap的并发问题。它通过分段锁(Segment)来实现并发访问,将整个Map分成多个Segment,每个Segment内部是一个HashTable。这样,不同的线程可以同时操作不同的Segment,从而提高并发性能。
问题17: 在Java 8中,HashMap的内部实现有何变化?
答案: 在Java 8中,HashMap的内部实现进行了一些优化。最显著的变化是在解决哈希冲突时引入了红黑树。当一个链表上的元素数量超过一定阈值(8)时,会将这个链表转换为红黑树,以提高查找效率。另外,Java 8中的HashMap在数据量较小时,采用链表的结构替代了原有的一维数组结构,从而减少内存消耗。
问题18: HashMap的put和get方法的时间复杂度是多少?
答案: 在平均情况下,HashMap的put和get方法的时间复杂度都是O(1)。但在最坏情况下,由于哈希冲突的发生,链表或红黑树的查找时间可能会达到O(n)。因此,尽量保证哈希函数的均匀分布,可以减少哈希冲突,提高HashMap的性能。
问题19: 如何在HashMap中查找一个键值对?
答案: 在HashMap中查找一个键值对,可以使用get方法,将要查找的键作为参数传入。get方法会计算键的哈希值,然后根据哈希值找到数组索引位置,最后在对应位置的链表或红黑树中进行查找。
问题20: 如何在HashMap中插入或更新一个键值对?文章来源:https://www.toymoban.com/news/detail-731467.html
答案: 在HashMap中插入或更新一个键值对,可以使用put方法,将键和值作为参数传入。put方法会根据键的哈希值找到数组索引位置,然后在对应位置的链表或红黑树中进行插入或更新操作。如果键已经存在,会更新对应的值;如果键不存在,会插入新的键值对。文章来源地址https://www.toymoban.com/news/detail-731467.html
到了这里,关于深入解析HashMap的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!