导语
爬虫技术是一种通过网络爬取目标网站的数据并进行分析的技术,它可以用于各种领域,如电子商务、社交媒体、新闻、教育等。本文将介绍如何使用爬虫技术对携程网旅游景点和酒店信息进行数据挖掘和分析,以及如何利用Selenium库和代理IP技术实现爬虫程序。
概述
携程网是中国领先的在线旅行服务公司,提供酒店预订、机票预订、旅游度假、商旅管理等服务。携程网上有大量的旅游景点和酒店信息,这些信息对于旅行者和旅游业者都有很大的价值。通过爬虫技术,我们可以从携程网上获取这些信息,并进行数据清洗、数据分析、数据可视化等操作,从而得到有用的洞察和建议。例如,我们可以分析国庆十一假期期间各地的旅游景点和酒店的热度、价格、评价等指标,为旅行者提供合理的出行建议,为酒店业者提供市场动态和竞争策略。
正文
为了实现爬虫程序,我们需要使用Python语言和一些第三方库,如Selenium、requests、BeautifulSoup、pandas、matplotlib等。Selenium是一个自动化测试工具,可以模拟浏览器操作,如打开网页、点击链接、输入文本等。requests是一个HTTP库,可以发送HTTP请求,如GET、POST等。BeautifulSoup是一个HTML解析库,可以从HTML文档中提取数据。pandas是一个数据分析库,可以对数据进行处理和计算。matplotlib是一个数据可视化库,可以绘制各种图表。
由于携程网有一定的反爬措施,如检测User-Agent、封IP等,我们需要使用代理IP技术来绕过这些限制。代理IP技术是指通过一个中间服务器来转发我们的请求,从而隐藏我们的真实IP地址。我们可以使用亿牛云爬虫代理服务来获取代理IP,并设置在Selenium或requests中。亿牛云爬虫代理服务提供了域名、端口、用户名、密码等信息,我们可以根据这些信息来设置代理服务器和身份认证。
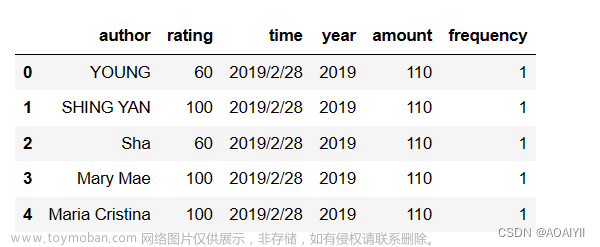
下面是一个简单的示例代码,展示了如何使用Selenium库和代理IP技术来爬取携程网上北京市的旅游景点信息,并保存到CSV文件中:文章来源:https://www.toymoban.com/news/detail-731790.html
# 导入相关库
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import pandas as pd
# 设置目标URL
target_url = "https://you.ctrip.com/sight/beijing1.html"
# 亿牛云 爬虫加强版代理服务器 (产品官网 www.16yun.cn)
proxy_host = "www.16yun.cn"
proxy_port = "31111"
# 代理验证信息
proxy_user = "16YUN"
proxy_pass = "16IP"
# 设置Chrome选项
chrome_options = Options()
# 设置代理IP
chrome_options.add_argument('--proxy-server= http://%(user)s:%(pass)s@%(host)s:%(port)s' % {
"host": proxy_host,
"port": proxy_port,
"user": proxy_user,
"pass": proxy_pass,
})
# 设置无头模式(不打开浏览器)
chrome_options.add_argument('--headless')
# 创建Chrome浏览器实例
driver = webdriver.Chrome(options=chrome_options)
# 打开目标URL
driver.get(target_url)
# 等待页面加载完成
time.sleep(3)
# 创建空列表存储数据
data_list = []
# 循环爬取前10页的数据
for i in range(10):
# 获取当前页面的景点元素
sights = driver.find_elements_by_class_name("rdetailbox")
# 循环遍历每个景点元素
for sight in sights:
# 获取景点名称
name = sight.find_element_by_class_name("rdtitle").text
# 获取景点评分
score = sight.find_element_by_class_name("score").text
# 获取景点评价数
comment = sight.find_element_by_class_name("comment").text
# 获取景点排名
rank = sight.find_element_by_class_name("ranking").text
# 将数据添加到列表中
data_list.append([name, score, comment, rank])
# 点击下一页按钮
next_page = driver.find_element_by_class_name("nextpage")
next_page.click()
# 等待页面加载完成
time.sleep(3)
# 关闭浏览器
driver.quit()
# 将列表转换为DataFrame
df = pd.DataFrame(data_list, columns=["name", "score", "comment", "rank"])
# 保存数据到CSV文件
df.to_csv("sights.csv", index=False, encoding="utf-8")
# 打印数据
print(df)
结语
通过上述的示例代码,我们可以看到使用爬虫技术对携程网旅游景点和酒店信息进行数据挖掘和分析是可行的,并且可以利用Selenium库和代理IP技术来提高爬虫的效率和稳定性。当然,这只是一个简单的示例,实际的爬虫程序可能需要更多的功能和优化,如异常处理、数据清洗、数据分析、数据可视化等。希望本文能够对有兴趣的读者有所启发和帮助。文章来源地址https://www.toymoban.com/news/detail-731790.html
到了这里,关于爬虫技术对携程网旅游景点和酒店信息的数据挖掘和分析应用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!