Python 文件和正则表达式
文件
打开文件
open 函数用来打开文件,常用模式有:
-
“r”:以只读方式打开文件。文件指针将会放在文件的开头。如果文件不存在,则报错。此种为打开文件的默认模式
-
“w”:以写入方式打开文件,清空文件内容并从头编辑;同时该文件不存在还会自动创建文件
-
“a”:以写入方式打开文件,文件指针放在文件末尾;同时该文件不存在还会自动创建文件
-
“r+”:以读写方式打开文件。文件指针将会放在文件的开头。如果文件不存在,则报错。
-
“w+”:以读写方式打开文件,清空文件内容并从头编辑;同时该文件不存在还会自动创建文件
-
“a”:以读写方式打开文件,文件指针放在文件末尾;同时该文件不存在还会自动创建文件
读取文件
直接读取 read():
fileName=r"./abc/test.txt"
with open(fileName,"r") as fileTxt:
contents=fileTxt.read()
print(contents)
# print(contents.rstrp()) 删除尾部空行
文件路径:在 linux 中采用 / 来分隔, 在 windows 中采用 \ 来分隔,但是 \ 是一个转移字符,需要再采用一个 \ 来进行转义(“C:\\abc\\test.txt”),但在 python 中采用 r 标识一个字符串为一个原生字符串,不会对其中的转义字符进行转义(r"C:\abc\test.txt“)。稳妥起见,在 linux 的路径前也添加上 r。
其中 with 关键字能够在不需要访问文件时,将文件自动关闭,既不需要调用 close() 方法了。当程序出现 bug 无法执行 close() 时,未能妥善地关闭文件可能会导致数据丢失或受损,而这是采用 with 关键字的一个重要原因。
read() 用来读取文件,它将文件的全部内容当作一个长字符串保存在变量中。但是由于 read() 在 print 的时候会在末尾多打印一个空行,这是因为 read() 到达文件尾时返回一个空字符串,而这个空字符串显示出来就是一个空行,此时可以通过 rstrip() 来删除。
逐行读取
采用 for 循环:
fileName=r"./abc/test.txt"
with open(fileName,"r") as fileTxt:
for line in fileTxt:
print(line)
# print(line.rstrip()) 删除多余空行
上面示例打印的时候也会多出一个空白行,这是因为在每行末尾都有一个换行符存在,而 print 本身也会加上一个换行符,所以就有了两个换行符啦,此时也需要通过 rstrip() 来消除这些多余的换行符。
采用 readlines():
在采用 with 关键字时,open 打开的文件对象只能在 with 代码块中可用。这有时候就不太方便了。而通过 readlines(),它从文件中读取每一行内容,并将它们存储在一个列表中,这个列表变量在之后的程序中可以被随时使用。
fileName=r"./abc/test.txt"
with open(fileName,"r") as fileTxt:
lines=fileTxt.readlines()
for line in lines:
print(line.rstrip())
正则表达式
匹配规则
单个字符:
-
\d:匹配数字,即 0-9 如:'00\d'可以匹配'007',但无法匹配'00A' -
\D:匹配非数字,即不是数字 -
\w:匹配非特殊字符,即a-z、A-Z、0-9、汉字,常用的用来匹配字母和数字 -
\W:匹配特殊字符,即非字母、非数字、非汉字 -
.:匹配任意一个任意字符(除了\n) -
\s:匹配一个空白字符,即空格,tab键 -
\S:匹配非空白字符
变长字符:
-
*:表示任意个字符(包括0个)\d*表示任意个数字 -
+:表示至少一个字符\s+表示至少一个空白字符 \d+ … -
?:表示0个或1个字符 -
{n}:表示n个字符\d{3}表示匹配3个数字,例如'010' -
{n,m}:表示 n-m 个字符\d{3,8}表示3-8个数字,例如'1234567' -
[]:匹配 [ ] 中列举的字符,常用来精确匹配,举例如下:
-
如
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线(_是特殊字符,需要转义) -
[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等 -
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是 Python 合法的变量 -
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}匹配的变量长度是1-20个字符(前面1个,后面[0,19])
其他字符:
-
^表示行的开头,^\d表示必须以数字开头。 -
$表示行的结束,\d$表示必须以数字结束。 -
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。
py也可以匹配'python',但是加上^py$就变成了整行匹配,就只能匹配'py'了。
re 模块
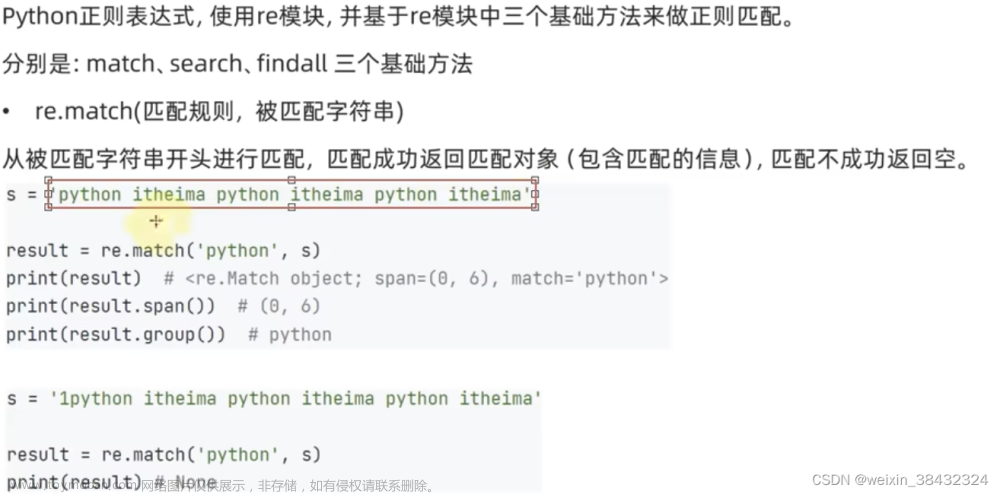
match 方法:
从字符串的起始位置开始匹配,如果匹配成功,就返回第一个对象。:
import re
m=re.match(r"^\d{3}[a-zA-Z]$","897y")
if(m):
print("ok")
else:
print("failed")
上例匹配一个三个数字开头一个字母结尾的字符串,采用了 match 方法,如果匹配成功,返回第一个 Match 对象,否则返回 None。
search 方法
工作方式与 match 类似,只是 search 从字符串的任意位置开始匹配,并返回第一个匹配的 Match 对象。区别在于:
n = re.search(r"bat|bae","eabat") # 能找到 bat
n = re.match(r"bat|bae","eabat") # 不能找到
group 方法
通过在正则表达式中使用小括号(),来对匹配到的数据进行分组,然后通过group([n]) 和 groups()获取对应的分组数据。值得一提的是,group() 是 Match 类中的方法,其他的方法还包括 groups(),start(),end(),span() ,这些方法都是用于从匹配的字符串中(或者说是从 Match对象中)获取相关信息。
import re
m = re.match(r"([0-9]*)([a-z]*)([0-9]*)","123abc456")
print(m.group()) # 输出匹配的完整字符串:123abc456
print(m.group(0)) # 输出匹配的完整字符串:123abc456
print(m.group(1)) # 从匹配的字符串中获取第一个分组:123
print(m.group(2)) # 从匹配的字符串中获取第二个分组:abc
print(m.group(3)) # 从匹配的字符串中获取第三个分组:456
split 方法
使用分隔符将字符串进行切割,将被切割后的子串以列表的形式返回。
正常的采用空格分隔字符串的 split() 示例如下:
str="a b c"
s=str.split(" ") # 返回 [”a”, ”b”, ”c”]
采用正则表达式的 split 方法如下:它的功能更加强大
import re
s=re.split(r"\s+", "a b c") # 返回 [”a”, ”b”, ”c”]
s=re.split(r"[\s\,]+", "a,b, c d") # 返回 [”a”, ”b”, ”c”, ”d”]
s=re.split(r"[\s\,\;]+", "a,b;; c d") # 返回 [”a”, ”b”, ”c”, ”d”]
s = pattern.split(r"\d+", "abc23de3fgh") # 返回 [”abc”, ”de”, ”fgh”]
#分隔符加上小括号之后,返回的字符串列表会保留分隔符
s = pattern.split(r"(\d+)", "abc23de3fgh")
# 返回 [“abc“, “23“, “de“, “3“, “fgh“]
编译:compile 方法
在 Python 中使用正则表达式时,re 模块内部会干两件事情:
-
编译正则表达式,如果正则表达式的字符串本身不合法,会报错;
-
用编译后的正则表达式去匹配字符串。
如果一个正则表达式需要使用多次,出于效率的考虑,我们可以先预编译该正则表达式,这样后面直接使用就好啦。示例如下:
import re
reObj = re.compile(r"^(\d{3})-(\d{3,8})$")
s=reObj.match("010-45263")
print(s.group()) # 010-45263
编译后生成 Regular Expression 对象,由于该对象自己包含了正则表达式,所以调用对应的方法时不用给出正则字符串。文章来源:https://www.toymoban.com/news/detail-732197.html
其他方法的使用可参考:python字符串_Python字符串匹配6种方法的使用文章来源地址https://www.toymoban.com/news/detail-732197.html
到了这里,关于Python 文件介绍和正则表达式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!