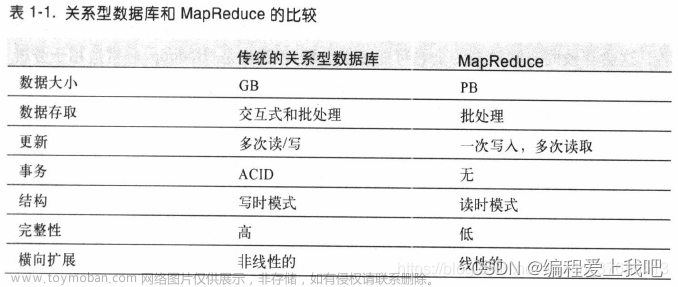
第一章

目前被称为纯种的Unix指的是System V以及BSD这两套软件。
要实现多任务的环境,除了硬件(主要是CPU)需要能够具有多任务的特性外,操作系统也需要支持这个功能。
如果网络有问题时,去/var/log目录查日志。
第二章 主机规划与磁盘分区
各个组件或设备在Linux下面都是一个文件。
Linux中,几乎所有的硬件设备文件都在/dev这个目录内。

正常的物理机器大概使用的都是/dev/sd[a-p]的磁盘文件名,至于虚拟机环境中,为了急速,可能就会使用/dev/vd[a-p]这种设备的文件名。
MSDOS(MBR) 与 GPT 磁盘分区表(partition table)
通常磁盘可能有多个磁盘盘,所有磁盘盘的同一个磁道我们称为磁柱 (Cylinder), 通常那是文件系统的最小单位,也就是分区槽的最小单位啦!
近来有 GPT 这个可达到 64bit 纪录功能的分区表, 现在我们甚至可以使用扇区 (sector)号码来作为分区单位哩!
1. MSDOS (MBR) 分区表格式与限制
早期, Linux 系统为了兼容于 Windows 的磁盘,因此使用的是支持 Windows 的 MBR(Master Boot Record, 主要开机纪录区) 的方式来处理开机管理程序与分区表!
启动引导程序记录区与分区表则通通放在磁盘的第一个扇区, 这个扇区通常是512bytes 的大小 (旧的磁盘扇区都是 512bytes),所以说,第一个扇区 512bytes 会有这两个数据:
- 主要启动记录区(Master Boot Record, MBR):可以安装开机管理程序的地方,有 446 bytes
- 分区表(partition table):记录整颗硬盘分区的状态,有 64 bytes。
由于分区表所在区块仅有 64 bytes 容量,因此最多仅能有四组记录区,每组记录区记录了该区段的启始与结束的柱面号码。
这四个分区的记录被称为主要(Primary)或扩展(Extended)分区。重要信息:
- 其实所谓的分区只是针对那个64字节的分区表进行设置而已。
- 硬盘默认的分区表技能写入四组分区信息。
- 这四组划分信息我们称为主要(Primary)或扩展(Extended)分区。
- 分区的最小单位通常是柱面。
- 当系统要写入磁盘时,一定会参考磁盘分区表,才能针对某个分区进行数据的处理。
扩展分区的目的是使用额外的扇区来记录分区信息,扩展分区本身并不能被拿来格式化。
扩展分区可以切出来逻辑分区,其中逻辑分区的/dev/sda1 - 4,前四个号码都是保留给主要分区或扩展分区使用的,所以逻辑分区的设备名称号码就是从5开始。
MBR主要分区、扩展分区与逻辑分区的特性如下:
- 主要分区与扩展分区最多可以有4个(硬盘的限制)
- 扩展分区最多只能有1个(操作系统的限制)
- 逻辑分区是由扩展分区划分出来的分区
- 能够被格式化后作为数据存储的分区是主分区和逻辑分区,扩展分区无法格式化
- 逻辑分区的数量依操作系统而不同,在Linux系统中SATA硬盘已经可以突破63个以上的分区限制。
分区是以柱面为单位的连续磁盘空间。
如果扩展分区被破坏了,所有逻辑分区将会被删除。
MBR的问题:
- 操作系统无法使用2.2TB以上的磁盘容量;
- MBR仅有一个区块,若被破坏后,经常无法或很难恢复;
- MBR内的存放启动引导程序的区块仅446字节,无法存储较多的程序代码。
2.GPT磁盘分区表
现在 GPT 分区预设可以提供多达 128 笔纪录,而在 Linux 本身的核心装置纪录中,针对单一磁盘来说,虽然过去最多只能到达 15 个分区槽,不过由于 Linux kernel 透过 udev 等方式的处理,现在Linux 也已经没有这个限制在了。
此外, GPT 分区已经没有所谓的主、延伸、逻辑分区的概念,既然每笔纪录都可以独立存在, 当然每个都可以视为是主分区!每一个分区都可以拿来格式化使用喔!
新的机制的关系中, 分区槽已经可以突破核心限制的状况。为了查询正确性,网络上有朋友实际拿一颗磁盘分区出 130 个以上的分区槽, 结果他发现 120 个以前的分区槽均可以格式化使用,但是 130 之后的似乎不太能够使用了!或许跟默认的 GPT 共 128 个号码有关!
3.启动流程中的BIOS与UEFI
是否能够读写 GPT 格式与开机的检测程序有关,开机的检测程序又分成 BIOS 与 UEFI 。
目前的主机系统在加载硬件驱动方面的程序,主要有早期的 BIOS 与新的 UEFI 两种机制。
BIOS搭配MBR/GPT的启动流程
BIOS 就是在开机的时候,计算机系统会主动执行的第一个程序。
启动过程:
- BIOS:启动主动执行的固件,会认识第一个可启动的设备;
- MBR:第一个可启动设备的第一个扇区内的主引导记录快,内含启动引导代码;
- 启动引导程序:一个可读取内核文件来执行的软件;
- 内核文件:开始启动操作系统。
如果你的分区表为 GPT 格式的话,那么 BIOS 也能够从 LBA0 的 MBR 兼容区块读取第一阶段的开机管理程序代码, 如果你的开机管理程序能够认识 GPT 的话,那么使用 BIOS同样可以读取到正确的操作系统内核。
Boot loader是操作系统安装在MBR上面的一个软件。由于MBR只有446字节,因此这个启动引导程序是非常小而高效。Boot loader的任务有:
- 提供选项:用户可以选择不同的启动选项,这也是多重引导的重要功能;
- 加载内核文件:直接指向可使用的程序区段来启动操作系统;
- 转交其他启动引导程序:将启动管理功能转交给其他启动引导程序负责。
多重引导总结:
- 每个分区都拥有自己的启动扇区;
- 实际可启动的内核文件是放置到各分区中的;
- 启动引导程序只会认识自己的系统分区内的可启动的内核文件,以及其他启动引导程序而已;
- 启动引导程序可直接指向或间接将管理权转交给另一个管理程序。
UEFI BIOS 搭配GPT启动的流程
UEFI可以直接获取GPT的分区表。
EFI 主要是想要取代 BIOS ,因此我们也称 UEFI 为 UEFI BIOS 就是了。

4.本章重点回顾
(1)新添购计算机硬件配备时,需要考虑的角度有『游戏机/工作机』、『效能/价格比』、『效能/消耗瓦数』、『支持度』等;
(2)旧的硬件配备可能由于保存的问题或者是电子零件老化的问题,导致计算机系统非常容易在运作过程中出现不明的当机情况
(3)Red Hat 的硬件支持: https://hardware.redhat.com/?pagename=hcl
(4)在 Linux 系统中,每个装置都被当成一个文件来对待,每个装置都会有装置文件名。
(5)磁盘装置文件名通常分为两种,实际 SATA/USB 装置文件名为/dev/sd[a-p],而虚拟机的装置可能为/dev/vd[a-p]
(6)磁盘的第一个扇区主要记录了两个重要的信息,分别是: (a)主要启动记录区(Master Boot Record, MBR):可以安装开机管理程序的地方,有 446 bytes (b)分区表(partition table):记录整颗硬盘分区的状态,有 64 bytes;
(7) 磁盘的 MBR 分区方式中,主要与延伸分区最多可以有四个,逻辑分区的装置文件名号码,一定由 5 号开始;
(8)如果磁盘容量大于 2TB 以上时,系统会自动使用 GPT 分区方式来处理磁盘分区。
(9)GPT 分区已经没有延伸与逻辑分区槽的概念,你可以想象成所有的分区都是主分区!
(10)某些操作系统要使用 GPT 分区时,必须要搭配 UEFI 的新型 BIOS 格式才可安装使用。
(11)开机的流程由: BIOS–>MBR–>-->boot loader–>核心文件;
(12)boot loader 的功能主要有:提供选单、加载核心、转交控制权给其他 loader
(13)boot loader 可以安装的地点有两个,分别是 MBR 与 boot sector
(14)Linux 操作系统的文件使用目录树系统,与磁盘的对应需要有『挂载』的动作才行;
(15)新手的简单分区,建议只要有/及 swap 两个分区槽即可
第三章 安装CentOS 7.x
分区:/boot、/、/home、/swap;
GRUB2一般指GRUB。 GNU GRUB(GRand Unified Bootloader简称“GRUB”)是一个来自GNU项目的多操作系统启动程序。GRUB是多启动规范的实现,它允许用户可以在计算机内同时拥有多个操作系统,并在计算机启动时选择希望运行的操作系统。
记住:XFS、LVM
本章重点回顾
- (1)不论你要安装什么样的 Linux 操作系统角色,都应该要事先规划例如分区、开机管理程序等;
- (2)建议练习机安装时的磁盘分区能有/, /boot, /home, swap 四个分区槽;
- (3)安装 CentOS 7.x 的模式至少有两种,分别是图形接口与文字接口;
- (4)CentOS 7 会主动依据你的磁盘容量判断要用 MBR 或 GPT 分区方式,你也可以强迫使用 GPT;
- (5)若安装笔记本电脑时失败,可尝试在开机时加入『linux nofb apm=off acpi=off』来关闭省电功能;
- (6)安装过程进入分区后,请以『自定义的分区模式』来处理自己规划的分区方式;
- (7)在安装的过程中,可以建立逻辑滚动条管理员 (LVM);
- (8)一般要求 swap 应该要是 1.5~2 倍的物理内存量,但即使没有 swap 依旧能够安装与运作 Linux 操作系统;
- (9)CentOS 7 预设使用 xfs 作为文件系统
- (10)没有连上 Internet 时,可尝试关闭防火墙,但 SELinux 最好选择『强制』状态;
- (11)设定时不要选择启动 kdump,因为那是给核心开发者查阅当机数据的;
- (12)可加入时间服务器来同步化时间,台湾可选择 tock.stdtime.gov.tw 这一部;
- (13)尽量使用一般用户来操作 Linux,有必要再转身份成为 root 即可。
- (14)即使是练习机,在建置 root 密码时,建议依旧能够保持良好的密码规则,不要随便设定!
第四章 首次登录与在线求助
服务器要挂一个UPS,以防断电。
在Linux中,默认root的提示字符是#,而一般身份用户的提示字符是$。
命令行:无论空几个空格,shell都视为一格。当命令太长,可以使用反斜杠(\)来转义回车。
如果命令的输入信息相当长,可以使用shift+PageUp/PageDown,来上下翻页。
locale:显示目前所支持的语系
Linux 的默认壳程序就是 bash。
某个命令忘记怎么用了,可以 --help
关机
如果要看目前有谁在在线,可以下达『who』这个指令
如果要看网络的联机状态,可以下达『netstat -a 』这个指令
如果要看后台执行的程序可以执行『ps -aux 』这个指令
使用这些指令可以让你稍微了解主机目前的使用状态。
正确关机方式:sync;sync;sync;reboot
本章重点回顾
- (1)为了避免瞬间断电造成的 Linux 系统危害,建议做为服务器的 Linux 主机应该加上不断电系统来持续提供稳定的电力;
- (2)养成良好的操作习惯,尽量不要使用 root 直接登入系统,应使用一般账号登入系统,有需要再转换身份
- (3) 可以透过『活动总览』查看系统所有使用的软件及快速启用惯用软件
- (4)在 X 的环境下想要『强制』重新启动 X 的组合按键为:『[alt]+[ctrl]+[backspace]』;
- (5) 预设情况下, Linux 提供 tty1~tty6 的终端机界面;
- (6) 在终端机环境中,可依据提示字符为$或#判断为一般账号或 root 账号;
- (7)取得终端机支持的语系数据可下达『echo $LANG』或 『locale』指令;
- (8)date 可显示日期、 cal 可显示日历、 bc 可以做为计算器软件;
- (9)组合按键中, [tab]按键可做为(1)命令补齐或(2)档名补齐或(3)参数选项补齐, [crtl]-[c]可以中断目前正在运作中的程序;
- (10)Linux 系统上的英文大小写为不同的资料
- (11)联机帮助系统有 man 及 info 两个常见的指令;
- (12) man page 说明后面的数字中, 1 代表一般账号可用指令, 8 代表系统管理员常用指令, 5 代表系统配置文件格式;
- (13)info page 可将一份说明文件拆成多个节点(node)显示,并具有类似超链接的功能,增加易读性;
- (14) 系统需正确的关机比较不容易损坏,可使用 shutdown, poweroff 等指令关机
第五章 Linux的文件权限与目录配置
Linux中,所有账号信息存储在/etc/passwd文件内,密码存储在/etc/shadow文件内,所有组名存储在/etc/group中。
d:目录
-:文件
l:链接文件
b:设备文件里面的可供存储的周边设备
c:设备文件里面的串行端口设备,例如键盘、鼠标
对于文件夹的权限,如果权限是[r--],由于没有x权限,因为没办法进入该目录。
1. 修改文件属性与权限
chgrp:修改文件所属用户组
chown:修改文件拥有者
chmod:修改文件的权限,SUID/SGID/SBIT等的特性
-R是递归修改
例子:
chgrp users aaa.conf 修改文件所属组为users
chown xyw aaa.conf 修改文件的所有者是xyw
chmod 777 aaa.conf 用数字类型的方式修改文件权限
chmod u=rwx,go=rwx aaa.conf 用符号类型方式修改文件权限
符号类型中,各个符号的含义如下:
u代表user,g代表group,o代表other,a代表所有身份。
如果不知道原先的文件属性,而只想要增加aaa.conf 这个文件的每个人均可写入的权限, 那么可以使用:chmod a+w aaa.conf
2. 文件的权限意义
在Linux中,文件是否能被执行,是由是否具有[X]这个权限来决定的,根文件名没关系。
当具有w权限时,可以具有写入、编辑、新增、修改文件内容的权限,但没有删除该文件的权限。
3. 目录的权限意义
r:表示具有读取目录结构的权限,所以当你具有读取一个目录的权限时,表示你可以查询该目录下的文件名数据,所以你就可以利用ls这个命令将该目录的内容列表显示出来。
w:表示具有改动该目录结构列表的权限,包括:
- 建立新的文件与目录;
- 删除已经存在的文件与目录(不论该文件的权限时什么);
- 将已存在的文件或目录进行更名;
- 移动该目录内的文件、目录位置;
- w权限与该目录下的文件名的变动有关。
x:代表的是用户能否进入该目录称为工作目录的用途。
总结,一般来说,rwx主要是针对文件的内容来设计权限,对目录来说,rwx则是针对目录内的文件名列表来设计权限。
通常要放开的目录,一般至少要具备r和x权限。

本章重点回顾
- (1)Linux 的每个文件中,可分别给予使用者、群组与其他人三种身份个别的 rwx 权限;
- (2)群组最有用的功能之一,就是当你在团队开发资源的时候,且每个账号都可以有多个群组的支持;
- (3) 利用 ls -l 显示的文件属性中,第一个字段是文件的权限,共有十个位,第一个位是文件类型, 接下来三个为一组共三组,为使用者、群组、其他人的权限,权限有 r,w,x 三种;
- (4)如果档名之前多一个『. 』,则代表这个文件为『隐藏档』;
- (5)若需要 root 的权限时,可以使用 su - 这个指令来切换身份。处理完毕则使用 exit 离开 su 的指令环境。
- (6)更改文件的群组支持可用 chgrp,修改文件的拥有者可用 chown,修改文件的权限可用 chmod
- (7)chmod 修改权限的方法有两种,分别是符号法与数字法,数字法中 r,w,x 分数为 4,2,1;
- (8)对文件来讲,权限的效能为:
- r:可读取此一文件的实际内容,如读取文本文件的文字内容等;
- w:可以编辑、新增或者是修改该文件的内容(但不含删除该文件);
- x:该文件具有可以被系统执行的权限。
- 对目录来说,权限的效能为:
- r (read contents in directory)
- w (modify contents of directory)
- x (access directory)
- (9)要开放目录给任何人浏览时,应该至少也要给予 r 及 x 的权限,但 w 权限不可随便给;
- (10)能否读取到某个文件内容,跟该文件所在的目录权限也有关系 (目录至少需要有 x 的权限)。
- (11)Linux 档名的限制为:单一文件或目录的最大容许文件名为 255 个英文字符或 128 个汉字字符;
- (12)根据 FHS 的官方文件指出, 他们的主要目的是希望让使用者可以了解到已安装软件通常放置于那个目录下
- (13)FHS 订定出来的四种目录特色为: shareable, unshareable, static, variable 等四类;
- (14)FHS 所定义的三层主目录为: /, /var, /usr 三层而已;
- (15)绝对路径文件名为从根目录 / 开始写起,否则都是相对路径的文件名。
第六章 Linux文件与目录管理
1. 特殊目录
.代表磁层目录
..代表上一层目录
-代表前一个工作目录
~代表家目录
~account代表account这个使用者的家目录
cp:默认的条件中,cp的源文件与目标文件的权限时不同的,目标文件的拥有者通常回事命令操作者本身。
如果想拷贝文件所有特性,加上参数 -a
2. 文件内容查看
cat由第一行开始显示文件内容,一次性显示所有
tac由最后一行开始显示,一次性显示所有
nl显示的时候,同事输出行号,一次性显示所有
more一页一页的显示内容
less与more类似,less还可以往前翻页
head只显示前几行
tail只显示后几行
od以二进制的方式读取文件内容
3. 文件的时间
修改时间:当文件的内容数据变更时,就会更新这个时间。内容数据值的是文件的内容,而不是文件的属性或权限。
状态时间:当该文件的状态改变时,就会更新这个时间。例如权限与属性被更改了,就会更新这个时间。
读取时间:当该文件的内容被读取时,就会更新这个时间。例如用cat读取时,就会更新该时间。
4. 文件/文件夹默认权限
默认情况下:
若用户建立文件,则默认没有可执行(x)权限,也就是最大是666,-rw-rw-rw-
若用户建立文件夹,则默认威所有权军开放,即777,drwxrwxrwx
umask,umask的数字指的是该默认值需要减掉的权限。例如:umask 022
5. 文件的特殊权限:SUID SGID SBIT
SUID
- SUID权限仅对二进制程序有效;
- 执行者对于该程序需要有x的可执行权限;
- 本权限仅在执行该程序的过程中有效;
- 执行者将具有该程序拥有者的权限。
SGID对文件来说,由如下功能:
- SGID对二进制程序有效;
- 程序执行者对于该程序来说,许具备x的权限;
- 执行者在执行的过程中将会获取该程序组的支持。
SGID对文件夹来说,具有如下功能:
- 用户若对于此目录具有r和x的权限时,该用户能够进入此目录;
- 用户在此目录下的有效用户组将变成该目录的用户组;
- 用途:若用户在此目录下具有w的权限,则用户所建立的新文件,该新文件的用户组与此目录的用户组相同。
SBIT目前只针对目录有效,功能如下:
- 当用户对于此目录具有w、x权限,即具有写入的权限;
- 当用户在此目录下建立文件或目录时,仅有自己与root由权利删除该文件。
6. 文件查找
which:是根据path这个环境变量所规范的路径,去查找执行文件的文件名,重点是找出执行文件而已,而且which后面接的是完整的文件名。
where:只找系统某些特定目录下的文件。
locate:它是根据已经建立的数据库来查找,所以需要更新数据库。
find:全盘查找。
find能否进行额外的操作,例如:find /usr/bin /usr/sbin -perm /7000 -exec ls -l {} \;
- {}代表find找到的内容
- -exec一直到\;是关键词,代表find额外操作的开始到结束,这中间就是find命令的额外操作。
- 因为;在bash环境中是特殊意义的,所以利用反斜杠来转义;
本章重点回顾
- (1) 绝对路径:『一定由根目录 / 写起』;相对路径:『不由 / 写起,而是由相对当前目录写起』
- (2)特殊目录有: ., …, -, ~, ~account 需要注意;
- (3)与目录相关的指令有: cd, mkdir, rmdir, pwd 等重要指令;
- (4)rmdir 仅能删除空目录,要删除非空目录需使用『rm -r 』指令;
- (5)用户能使用的指令是依据 PATH 变量所规定的目录去搜寻的;
- (6)ls 可以检视文件的属性,尤其 -d, -a, -l 等选项特别重要!
- (7)文件的复制、删除、移动可以分别使用: cp, rm , mv 等指令来操作;
- (8)检查文件的内容(读文件)可使用的指令包括有: cat, tac, nl, more, less, head, tail, od 等
- (9)cat -n 与 nl 均可显示行号,但默认的情况下,空白行会不会编号并不相同;
- (10)touch 的目的在修改文件的时间参数,但亦可用来建立空文件;
- (11)一个文件记录的时间参数有三种,分别是 access time(atime), status time (ctime), modification time(mtime), ls默认显示的是 mtime。
- (12)除了传统的 rwx 权限之外,在 Ext2/Ext3/Ext4/xfs 文件系统中,还可以使用 chattr 与 lsattr 设定及观察隐藏属性。 常见的包括只能新增数据的 +a 与完全不能更动文件的 +i 属性。
- (13)新建文件/目录时,新文件的预设权限使用 umask 来规范。默认目录完全权限为 drwxrwxrwx, 文件则为-rw-rw-rw-。
- (14)文件具有 SUID 的特殊权限时,代表当用户执行此一 binary 程序时,在执行过程中用户会暂时具有程序拥有者的权限
- (15)目录具有 SGID 的特殊权限时,代表用户在这个目录底下新建的文件之群组都会与该目录的组名相同。
- (16)目录具有 SBIT 的特殊权限时,代表在该目录下用户建立的文件只有自己与 root 能够删除!
- (17)观察文件的类型可以使用 file 指令来观察;
- (18)搜寻指令的完整文件名可用 which 或 type ,这两个指令都是透过 PATH 变量来搜寻文件名;
- (19)搜寻文件的完整档名可以使用 whereis 找特定目录或 locate 到数据库去搜寻,而不实际搜寻文件系统;
- (20)利用 find 可以加入许多选项来直接查询文件系统,以获得自己想要知道的档名。
第七章 Linux磁盘与文件系统管理
超级区块:记录此文件系统的整体信息,包括inode与数据区块的总量、使用量、剩余量,以及文件系统的格式与相关信息等。
inode:记录文件的权限(rwx)和属性(拥有者、用户组、时间参数等),一个文件占用一个inode,同时记录此文件的数据所在的区块号码;
数据区块:世纪记录文件内容,若文件太大时,会占用多个区块。
新建文件夹时:
当我们在Linux下的文件系统建立一个目录时,文件系统会分配一个inode与至少一块区块给该目录。其中,inode记录该目录的相关权限与属性,并可记录分配到的那块block号码;而bolck则是记录在这个目录下的文件名与改文件名所占用的inode号码数据。
注意1:目录并不只会占用一个 block 而已,当在目录底下的文件数如果太多而导致一个 block 无法容纳的下所有的档名与 inode 对照表时, Linux 会给予该目录多一个 block来继续记录相关的数据;
注意2:新增、删除、更改文件名都与目录的w权限有关,是因为文件名是记录在目录的block当中的。因为我们要去读某个文件时,就务必会经过目录的inode与block,然后才能找到那个待读取的文件的inode号码,最终才会读取到正确的文件的block内的数据。
新建文件时:
- 先确定用户对于将新增文件的目录是否具有w与x权限,若有的话才能新增;
- 根据inode对照表找到没有使用的inode号码,并将新文件的额权限与属性写入;
- 根据区块对照表找到没有使用中的区块号码,并将实际的数据写入区块中,且更新inode的区块指向数据。
- 将刚刚写入的inode与区块数据同步更新inode对照表与区块对照表,并更新超级区块的内容。
文件名的记录是在目录的block当中。
因为超级区块、inode对照表以及区块对照表的数据经常变动,每次新增、删除、编辑时都有可能会影响到这三个部门的数据,因此才被称为元数据。
日志文件系统的原理
预备:当系统要写入一个文件时,先会在日志记录区块中记录某个文件准备要写入的信息;
实际写入:开始写入文件的权限与数据;开始更新matedata的数据;
结束:完成数据与metadata的更新后,在日志记录区块当中完成该文件的记录。
Linux文件系统的运行
系统会将常用的文件数据放置到内存的缓冲区,以加速文件系统的读写操作;
承上,因此Linux物理内存最后被会被用光,这是正常的情况,可加速系统的性能;
你可以使用sync来强制内存中的Dirty的文件会写到磁盘中;
若正常关机时,关机命令会主动调用sync来讲内存中的数据会写磁盘内;
若不正常关机,由于数据尚未回写到磁盘内,因此重新启动后可能会花很多时间在进行磁盘校验,甚至可能导致文件系统的损坏(非磁盘损坏)。
挂载点
我们可以通过判断inode号码来确认不同文件名是否为相同的文件。
重点是: 挂载点一定是目录,该目录为进入该文件系统的入口。
XFS系统
基本上 xfs 就是一个日志式文件系统,这个 xfs 就是被开发来用于高容量磁盘以及高性能文件系统之用。
xfs文件系统在数据的分布上,主要规划为三个部分,一个数据区、一个文件系统活动登陆区以及一个实时运行区。
数据区的储存区
xfs 的这个数据区的储存区群组 (allocation groups, AG),你就将它想成是 ext家族的 block 群组 (block groups) 就对了!该数据区也是分为多个储存区群组(allocation groups) 来分别放置文件系统所需要的数据。每个储存区群组都包含了:
- 整个文件系统的 superblock、
- 剩余空间的管理机制、
- inode 的分配与追踪。
此外, inode 与 block 都是系统需要用到时, 这才动态配置产生,所以格式化动作超级快!
文件系统活动登录区
这个区域主要被用来记录文件系统的变化,其实有点像日志区。
因为系统所有动作的时候都会在这个区块做个纪录,因此这个区块的磁盘活动是相当频繁的!xfs设计有点有趣,在这个区域中,你可以指定外部的磁盘来作为 xfs 文件系统的日志区块喔!例如,可以将 SSD磁盘作为 xfs 的登录区,这样当系统需要进行任何活动时, 就可以更快速的进行工作!
实时运作区
当有文件要被建立时,xfs 会在这个区段里面找一个到数个的 extent 区块,将文件放置在这个区块内,等到分配完毕后,再写入到 data section 的 inode 与 block 去! 这个 extent 区块的大小得要在格式化的时候就先指定,最小值是 4K 最大可到 1G。一般非磁盘阵列的磁盘默认为 64K容量,而具有类似磁盘阵列的 stripe 情况下,则建议 extent 设定为与 stripe 一样大较佳。这个extent 最好不要乱动,因为可能会影响到实体磁盘的效能。
xfs_info
XFS 文件系统的描述数据观察:xfs_info 例如:xfs_info /dev/sda1
文件系统的操作
整个 Linux 的系统都是透过一个名为 Virtual Filesystem Switch 的核心功能去读取 filesystem 的。
df:列出文件系统的整体磁盘使用量;由于 df 主要读取的数据几乎都是针对一整个文件系统,因此读取的范围主要是在Superblock 内的信息, 所以这个指令显示结果的速度非常的快速!
du:查看文件系统的磁盘使用量
例如:du -sm /* 查看根目录下每个目录所占用的容量
硬链接与符号链接
符号链接:类似于Windows的快捷方式功能的文件,可以让你快速地链接到目标文件;
硬链接:通过文件系统的inode链接来产生新文件名,而不是产生新文件。
硬链接
- 每个文件都会占用一个inode,文件内容由inode的记录来指向;
- 想要读取该文件,必须要经过目录纪录的文件名来指向到正确的inode号码才能读取。
也就是说,文件名至于目录有关,文件内容则有inode有关。有没有可能多个文件名对应到同一个inode号码?有的,这就是硬链接。硬链接只是在某个目录下新增一条文件名链接到某个inode号码的关联记录而已。
如果将任何一个硬链接文件名删除,inode与区块都还是存在的。
硬链接只是在某个目录下的区块多写一个关联数据而已,既不会增加inode也不会消耗区块数量。
硬链接不能跨文件系统,也不能链接目录。
符号链接
符号链接是建立一个独立的文件,而这个文件会让数据的读取指向它链接的那个文件的文件名。
当源文件被删除之后,符号链接的文件会“打不开了”。
由符号链接所连击的文件位一个独立的新文件,会占用inode与区块。
创建方式
ln 【-s】 源文件 目标文件
不加任何参数,就是硬链接。
硬盘的分区、格式化、校验与挂载
磁盘状态
lsblk :列出系统上所有磁盘列表
blkid:列出设备的UUID等参数
parted:列出磁盘的分区表类型与分区信息
磁盘分区
MBR分区表请使用fdisk分区
GPT分区表请使用gdisk分区
分区步骤:
- 先用lsblk或blkid找到磁盘;
- 再用parted /dev/sda print 来找出内部的分区表类型;
- 最后用gdisk或fdisk来操作系统。
Partition Table:msdos表示该硬盘基于MBR格式进行的分区
磁盘格式化
磁盘格式化就是创建文件系统。
命令:make fileysytem,mkfs
文件系统检验
如果文件系统发生了错乱,就需要检验。被检查的硬盘分区务必不可挂载到系统上,需要在卸载的状态。
xfs_repair处理XFS文件系统
fsck.ext4处理ext4文件系统
文件系统的挂载与卸载
注意:
单一文件系统不应该被重复挂载在不同的挂载点(目录)中;
单一目录不应该重复挂载多个文件系统;
要作为挂载点的目录,理论上应该都是空目录才行;
挂载时,最好用设备的UUID。
设置启动挂载
开机挂载,必须要修改/etc/fstab。
系统挂载的限制:
- 根目录 / 是必须要挂载的,而且一定要有先于其他挂载点被挂载进来。
- 其他挂载点必须为已建立的目录,可任意指定,但一定要遵守必须的系统目录架构原则。
- 所有挂载点在同一时间内,只能挂载一次。
- 所有硬盘分区在同一时间内,只能挂载一次。
- 如若进行卸载,您必须先将工作目录移动挂载点之外。
直接到/etc/fstab里面修改,就可以实现启动自动挂载。
本章重点回顾
- (1) 一个可以被挂载的数据通常称为『文件系统, filesystem』而不是分区槽 (partition) 喔!
- (2)基本上 Linux 的传统文件系统为 Ext2 ,该文件系统内的信息主要有:
- superblock:记录此 filesystem 的整体信息,包括 inode/block 的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
- inode:记录文件的属性,一个文件占用一个 inode,同时记录此文件的数据所在的 block 号码;
- block:实际记录文件的内容,若文件太大时,会占用多个 block 。
- (3) Ext2 文件系统的数据存取为索引式文件系统(indexed allocation)
- (4) 需要碎片整理的原因就是文件写入的 block 太过于离散了,此时文件读取的效能将会变的很差所致。 这个时候可以透过碎片整理将同一个文件所属的 blocks 汇整在一起。
- (5)Ext2 文件系统主要有:boot sector, superblock, inode bitmap, block bitmap, inode table, data block 等六大部分。
- (6)data block 是用来放置文件内容数据地方,在 Ext2 文件系统中所支持的 block 大小有 1K, 2K 及 4K 三种而已
- (7)inode 记录文件的属性/权限等数据,其他重要项目为: 每个 inode 大小均为固定,有 128/256bytes 两种基本容量。每个文件都仅会占用一个 inode 而已; 因此文件系统能够建立的文件数量与 inode 的数量有关;
- (8)文件的 block 在记录文件的实际数据,目录的 block 则在记录该目录底下文件名与其 inode 号码的对照表;
- (9)日志式文件系统 (journal) 会多出一块记录区,随时记载文件系统的主要活动,可加快系统复原时间;
- (10)Linux 文件系统为增加效能,会让主存储器作为大量的磁盘高速缓存;
- (11) 实体链接只是多了一个文件名对该 inode 号码的链接而已;
- (12)符号链接就类似 Windows 的快捷方式功能。
- (13) 磁盘的使用必需要经过: 分区、格式化与挂载,分别惯用的指令为: gdisk, mkfs, mount 三个指令
- (14)分区时,应使用 parted 检查分区表格式,再判断使用 fdisk/gdisk 来分区,或直接使用 parted 分区
- (15)为了考虑效能, XFS 文件系统格式化时,可以考虑加上 agcount/su/sw/extsize 等参数较佳
- (16) 如果磁盘已无未分区的容量,可以考虑使用大型文件取代磁盘装置的处理方式,透过 dd 与格式化功能。
- (17) 开机自动挂载可参考/etc/fstab 之设定,设定完毕务必使用 mount -a 测试语法正确否;
第八章 文件与文件系统的压缩
常见压缩文件扩展名:
*.Z
*.zip
*.gz
*.bz2
*.xz
*.tar
*.tar.gz
*.tar.bz2
*.tar.xz
当使用gzip进行压缩时,在默认的状态下原本的文件会被压缩成.gz后缀的文件,源文件就不再存在了。
tar
压缩:tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称
查询:tar -jtv -f filename.tar.bz2
解压缩:tar -jxv -f filename.tar.bz2 -C 欲解压缩的目录
-p:保留备份数据的原本权限与属性,常用语备份重要的配置文件。
-P:在使用命令时,不要加-P这个属性。它会保留文件的根目录,将来解压缩文件时,会自动负载对应目录的文件。
XFS文件系统的备份与还原
用:xfsdump,使用xfsdump时,注意以下限制:
- xfsdump不支持没有挂在的文件系统备份,所以只能备份已挂载的文件系统;
- xfsdump必须使用root权限
- xfsdump只能备份xfs文件系统
- xfsdump备份下来的数据,只能让xfsrestore解析;
- xfsdump是通过文件系统的UUID来变别各备份文件,因此不能让备份两个具有相同UUID的文件系统。
xfsdump默认仅支持文件系统的备份。
其他备份工具
dd:它是直接读取扇区,就算没有用到的扇区也会被写入备份文件。
cpio:一般与find命令一起用。
本章重点回顾
- (1)压缩指令为透过一些运算方法去将原本的文件进行压缩,以减少文件所占用的磁盘容量。 压缩前与压缩后的文件所占用的磁盘容量比值, 就可以被称为是『压缩比』
- (2) 压缩的好处是可以减少磁盘容量的浪费,在 WWW 网站也可以利用文件压缩的技术来进行数据的传送,好让网站带宽的可利用率上升喔
- (3)压缩文件案的扩展名大多是:『*.gz, *.bz2, *.xz, *.tar, *.tar.gz, *.tar.bz2, *.tar.xz』
- (4)常见的压缩指令有 gzip, bzip2, xz。压缩率最佳的是 xz,若可以不计时间成本,建议使用 xz 进行压缩。
- (5)tar 可以用来进行文件打包,并可支持 gzip, bzip2, xz 的压缩。
- (6)压 缩: tar -Jcv -f filename.tar.xz 要被压缩的文件或目录名称
- (7)查 询: tar -Jtv -f filename.tar.xz
- (8)解压缩: tar -Jxv -f filename.tar.xz -C 欲解压缩的目录
- (9) xfsdump 指令可备份文件系统或单一目录
- (10)xfsdump 的备份若针对文件系统时,可进行 0-9 的 level 差异备份!其中 level 0 为完整备份;
- (11)xfsrestore 指令可还原被 xfsdump 建置的备份档;
- (12)要建立光盘刻录数据时,可透过 mkisofs 指令来建置;
- (13)可透过 wodim 来写入 CD 或 DVD 刻录机
- (14) dd 可备份完整的 partition 或 disk ,因为 dd 可读取磁盘的 sector 表面数据
- (15)cpio 为相当优秀的备份指令,不过必须要搭配类似 find 指令来读入欲备份的文件名数据,方可进行备份动作。
第九章 VIM程序编辑器
vi有三种模式:一般命令模式、编辑模式、命令行模式。
0:移动到本行最前面
$:移动到本行最后面
gg:移动到文件第一行
G:移动到文件最后一行
dd:删除光标所的那一行
yy:复制光标所在的那一行
u:恢复上一个操作
.swap文件的处理
虽然有六个选项,但日常中通常有2种处理方式:
R:就是Recover,加载xx.swapde文件的内容,然后自己手动删除.swap文件。
D:就是Delete it,删除掉这个缓存文件,会加载原本的文件。
可视区块
v:字符选择,会将光标经过的地方反白选择
V:行选择,会将广播啊经过的行反白选择
Ctrl + v :可视区块,可以用矩形的方式选择数据
y:将反白的地方复制起来
d:将反白的地方删除
p:将刚刚复制的区块,在光标所在处粘贴
本章重点回顾
- (1)Linux 底下的配置文件多为文本文件,故使用 vim 即可进行设定编辑;
- (2)vim 可视为程序编辑器,可用以编辑 shell script, 配置文件等,避免打错字;
- (3)vi 为所有 unix like 的操作系统都会存在的编辑器,且执行速度快速;
- (4)vi 有三种模式,一般指令模式可变换到编辑与指令列模式,但编辑模式与指令列模式不能互换;
- (5) 常用的按键有 i, [Esc], :wq 等;
- (6)vi 的画面大略可分为两部份, (a)上半部的本文与(b)最后一行的状态+指令列模式;
- (7)数字是有意义的,用来说明重复进行几次动作的意思,如 5yy 为复制 5 列之意;
- (8)光标的移动中,大写的 G 经常使用,尤其是 1G, G 移动到文章的头/尾功能!
- (9) vi 的取代功能也很棒! :n1,n2s/old/new/g 要特别注意学习起来;
- (10) 小数点『. 』为重复进行前一次动作,也是经常使用的按键功能!
- (11)进入编辑模式几乎只要记住: i, o, R 三个按钮即可!尤其是新增一列的 o 与取代的 R
- (12) vim 会主动的建立 swap 暂存档,所以不要随意断线!
- (13) 如果在文章内有对齐的区块,可以使用 [ctrl]-v 进行复制/贴上/删除的行为
- (14)使用 :sp 功能可以分区窗口
- (15) 若使用 vim 来撰写网页,若需要 CSS 元素数据,可透过 [crtl]+x, [crtl]+o 这两个连续组合按键来取得关键词
- (16)vim 的环境设定可以写入在 ~/.vimrc 文件中;
- (17)可以使用 iconv 进行文件语系编码的转换
- (18) 使用 dos2unix 及 unix2dos 可以变更文件每一列的行尾断行字符。
第十章 认识与学习BASH
我们必须通过Shell将我们输入的命令与内核沟通,好让内核可以控制硬件来正确无误地工作。
应用程序其实是在最外层,就如同鸡蛋的外壳一样,因此这个东西叫壳程序。
壳程序的功能只是提供用户操作系统的一个界面,因此这个壳程序需要可以调用其他软件才行。
/bin/bash 是Linux默认的Shell。
父进程的自定义变量无法在子进程内使用,但是可以通过export将变量编程环境变量后,就能够在子进程中使用了。
login与 non-login shell
login shell:取得bash时需要完整的登录流程,就成为login shell。例如通过输入账号密码取得bash就称为login shell。
non-login shell:取得bash的方法不需要重复登录的操作,例如,(1)通过x window 登录Linux,再以X图形化接口启动终端,此时这个终端并没有需要再次输入账号密码,该bash环境就称为non-login shell。(2)在原本bash环境下再次执行bash命令,同样也没输入账号密码,那么第二个bash也是non-login shell。
一般login shell只会读取两个文件:
- /etc/pfofile:这是系统整体的设置,最好不要修改该文件;
- ~/.bash_profile或~/.bash_login或~/.profile:属于用户个人设置,你要添加自己的数据,就写入这里。
bash的login shell 情况下,所取得的整体环境配置文件其实只有/etc/pfofile,但/etc/pfofile会调用出其他的配置文件。
source:读入环境变量文件的命令
Ctrl + S:暂停屏幕的输出
Ctrl + Q:恢复屏幕的输出
数据流重定向
标准输出指的是命令还行所返回的正确信息
标准错误输出可以理解为命令执行失败后,所返回的错误信息。
标准输入:代码为0,使用<或<<
标准输出:代码为1,使用>或>>
标准错误输出:代码为2,使用2> 或 2>>
1>:以覆盖的方法将正确的数据输出到指定的文件或设备上;
1>>:以累加的方法将正确的数据输出到指定的文件或设备上;
2>:以覆盖的方法将错误的数据输出到指定的文件或设备上;
2>>:以累加的方法将错误的数据输出到指定的文件或设备上;
把正确数据和错误数据都写入到文件时,可能会有错乱的现象,这个时候需要这样写:
find /home -name .bashrc > list 2>&1
find /home -name .bashrc &> list
如果不想要错误信息则可以: 2> /dev/null
本章重点回顾
- (1)由于核心在内存中是受保护的区块,因此我们必须要透过『Shell 』将我们输入的指令与 Kernel 沟通,好让 Kernel 可以控制硬件来正确无误的工作
- (2)学习 shell 的原因主要有:文字接口的 shell 在各大 distribution 都一样;远程管理时文字接口速度较快;
- shell 是管理 Linux 系统非常重要的一环,因为 Linux 内很多控制都是以 shell 撰写的。
- (3)系统合法的 shell 均写在 /etc/shells 文件中;
- (4) 用户默认登入取得的 shell 记录于 /etc/passwd 的最后一个字段;
- (5)bash 的功能主要有:命令编修能力;命令与文件补全功能;命令别名设定功能;工作控制、前景背景控制;程序化脚本;通配符
- (6)type 可以用来找到执行指令为何种类型,亦可用于与 which 相同的功能;
- (7) 变量就是以一组文字或符号等,来取代一些设定或者是一串保留的数据
- (8)变量主要有环境变量与自定义变量,或称为全局变量与局部变量
- (9)使用 env 与 export 可观察环境变量,其中 export 可以将自定义变量转成环境变量;
- (10)set 可以观察目前 bash 环境下的所有变量;
- (11) $? 亦为变量,是前一个指令执行完毕后的回传值。在 Linux 回传值为 0 代表执行成功;
- (12) locale 可用于观察语系资料;
- (13) 可用 read 让用户由键盘输入变量的值
- (14) ulimit 可用以限制用户使用系统的资源情况
- (15) bash 的配置文件主要分为 login shell 与 non-login shell。 login shell 主要读取 /etc/profile 与 ~/.bash_profile,
- non-login shell 则仅读取 ~/.bashrc
- (16)在使用 vim 时,若不小心按了 [crtl]+s 则画面会被冻结。你可以使用 [ctrl]+q 来解除冻结
- (17)通配符主要有: *, ?, [] 等等
- (18) 数据流重导向透过 >, 2>, < 之类的符号将输出的信息转到其他文件或装置去;
- (19) 连续命令的下达可透过 ; && || 等符号来处理
- (20) 管线命令的重点是:『管线命令仅会处理 standard output,对于 standard error output 会予以忽略』 『管线命令必须要能够接受来自前一个指令的数据成为 standard input 继续处理才行。』
- (21) 本章介绍的管线命令主要有: cut, grep, sort, wc, uniq, tee, tr, col, join, paste, expand, split, xargs 等。
第十一章 正则表达式与文件格式化处理
grep在数据中查询一个字符串时,是以“整行”为单位来进行数据的选取。例如一个文件内有10行,其中有2行具有我们所查询的字符串,则将那两行显示在屏幕上,其他的就丢弃了。
awk
例如:last -n 5 | awk '{print $1 "\t" $3}'
awk的括号内,每一行的每个字段都是有变量名称,那就是$1,$2等。
awk是以行为一次处理的单位,而以字段为最小的处理单位。
本章重点回顾
- (1)正规表示法就是处理字符串的方法,他是以行为单位来进行字符串的处理行为;
- (2)正规表示法透过一些特殊符号的辅助,可以让使用者轻易的达到『搜寻/删除/取代』某特定字符串的处理程序;
- (3)只要工具程序支持正规表示法,那么该工具程序就可以用来作为正规表示法的字符串处理之用;
- (4)正规表示法与通配符是完全不一样的东西!通配符 (wildcard) 代表的是 bash 操作接口的一个功能, 但正规表示法则是一种字符串处理的表示方式!
- (5) 使用 grep 或其他工具进行正规表示法的字符串比对时,因为编码的问题会有不同的状态,因此, 你最好将 LANG 等变量设定为 C 或者是 en 等英文语系!
- (6)grep 与 egrep 在正规表示法里面是很常见的两支程序,其中, egrep 支持更严谨的正规表示法的语法;
- (7) 由于编码系统的不同,不同的语系 (LANG) 会造成正规表示法撷取资料的差异。因此可利用特殊符号如[:upper:] 来替代编码范围较佳;
- (8)由于严谨度的不同,正规表示法之上还有更严谨的延伸正规表示法;
- (9)基础正规表示法的特殊字符有: *, ., [], [-], [^], ^, $ 等!
- (10) 常见的支持正规表示法的工具软件有: grep , sed, vim 等等
- (11)printf 可以透过一些特殊符号来将数据进行格式化输出;
- (12)awk 可以使用『字段』为依据,进行数据的重新整理与输出;
- (13)文件的比对中,可利用 diff 及 cmp 进行比对,其中 diff 主要用在纯文本文件方面的新旧版本比对
- (14)patch 指令可以将旧版数据更新到新版 (主要亦由 diff 建立 patch 的补丁来源文件)
第十二章 学习shell脚本
脚本的第一行是:#!/bin/bash
shell脚本跟踪
sh -x aaa.sh
-x:将使用到的脚本内容显示到屏幕上,这是很有用的。
第十三章 Linux账号管理与ACL权限设置
每个登录的用户至少都会获取2个ID,UID、GID。
/etc/passwd
这个文件的构造是这样的:每一行都代表一个帐号,有几行就代表有几个帐号在 你的系统中! 不过需要特别留意的是,里头很多帐号本来就是系统正常运行所必须要 的,我们可以简称他为系统帐号, 例如 bin, daemon, adm, nobody 等等,这些帐号请不要 随意的杀掉他呢!这个文件的内容有点像这样:

每一行使用:分隔开
内容解释:
1. 帐号名称: 就是帐号啦!用来提供给对数字不太敏感的人类使用来登陆系统的!需要用来对应 UID 喔。例如 root 的 UID 对应就是 0 (第三字段);
2. 密码:早期 Unix 系统的密码就是放在这字段上!但是因为这个文件的特性是所有的程序 都能够读取,这样一来很容易造成密码数据被窃取, 因此后来就将这个字段的密 码数据给他改放到 /etc/shadow 中了。所以这里你会看到一个“ x ”,呵呵!
3.UID:用户标识符。通常 Linux 对于 UID 有几个限制需要说给您了解一下:

4. GID:这个与 /etc/group 有关!其实 /etc/group 的观念与 /etc/passwd 差不多,只是他是用 来规范群组名称与 GID 的对应而已!
5. 使用者信息说明栏: 这个字段基本上并没有什么重要用途,只是用来解释这个帐号的意义而已!不过, 如果您提供使用 finger 的功能时, 这个字段可以提供很多的讯息呢!本章后面的 chfn 指令会来解释这里的说明。
6. 主文件夹:这是使用者的主文件夹,以上面为例, root 的主文件夹在 /root ,所以当 root 登陆 之后,就会立刻跑到 /root 目录里头啦!呵呵! 如果你有个帐号的使用空间特别的 大,你想要将该帐号的主文件夹移动到其他的硬盘去该怎么作? 没有错!可以在 这个字段进行修改呦!默认的使用者主文件夹在 /home/yourIDname
7. Shell:我们在第十章 BASH 提到很多次,当使用者登陆系统后就会取得一个 Shell 来与系 统的核心沟通以进行使用者的操作任务。那为何默认 shell 会使用 bash 呢?就是在 这个字段指定的啰! 这里比较需要注意的是,有一个 shell 可以用来替代成让帐号 无法取得 shell 环境的登陆动作!那就是 /sbin/nologin 这个东西!这也可以用来制作 纯 pop 邮件帐号者的数据呢!
/etc/shadow
专门管理密码相关数据。同样以:作为分隔符,如果数一数,会发现共有九个字段。
内容解释:
账号名称:由于密码也需要与账号对应啊~因此,这个文件的第一栏就是账号,必须要与 /etc/passwd 相同才行!
密码:这个字段内的数据才是真正的密码,而且是经过编码的密码(加密)啦! 你只会看到有一些特殊符号的字母就是了!需要特别留意的是,虽然这些加密过的密码很难被解出来, 但是“很难“不等于”不会“,所以,这个文件的预设权限是[-r------] 或者是[-------],亦即只有 root 才可以读写就是了! 你得随时注意,不要不小心更动了这个文件的权限呢!
另外,由于各种密码编码的技术不一样,因此不同的编码系统会造成这个字段的长度不相同。 举例来说,旧式的 DES.MD5 编码系统产生的密码长度就与目前惯用的 SHA 不同(注 2)! SHA 密码长度明显的比较长些。由于固定的编码系统产生的密码长度必须一致,因此”当你让这个字段的长度改变后,该密码就会失效(算不出来)“。很多软件透过这个功能,在此字段前加上 !或 * 改变密码字段长度,就会让密码”暂时失效“了。
最近更动密码的日期:这个字段记录了”更动密码那一天“的日期。
密码不可被更动的天数:(与第 3 字段相比)第四个字段记录了: 这个账号的密码在最近一次被更改后需要经过几天才可以再被变更。如果是 0 的话,表示密码随时可以更动的意思。这的限制是为了怕密码被某些人一改再改而设计的。如果设定为 20 天的话,那么当你设定了密码之后,20 天之内都无法改变这个密码呦。
密码需要重新变更的天数:(与第 3字段相比)经常变更密码是个好习惯。为了强制要求用户变更密码,这个字段可以指定在最近一次更改密码后, 在多少天数内需要再次的变更密码才行。你必须要在这个天数内重新设定你的密码,否则这个账号的密码将会[变为过期特性]。 而如果像上面的 99999(计算为 273 年)的话,那就表示,呵呵,密码的变更没有强制性之意。
密码需要变更期限前的警告天数:(与第 5字段相比)当账号的密码有效期限快要到的时候(第 5 字段),系统会依据这个字段的设定,发出[警告]言论给这个账号,提醒他[再过天你的密码就要过期了,请尽快重新设定你的密码呦,如上面的例子,则是密码到期之前的 7 天之内,系统会警告该用户。
密码过期后的账号宽限时间(密码失效日):(与第 5 字段相比)密码有效日期为[更新日期(第 3 字段)] +[重新变更日期(第 5 字段)],过了该期限后用户依旧没有更新密码,那该密码就算过期了。 虽然密码过期但是该账号还是可以用来进行其他工作的,包括登入系统取得bash 。不过如果密码过期了, 那当你登入系统时,系统会强制要求你必须要重新设定密码才能登入继续使用喔,这就是密码过期特性。那这个字段的功能是什么呢?是在密码过期几天后,如果使用者还是没有登入更改密码,那么这个账号的密码将会了失效, 亦即该账号再也无法使用该密码登入了。要注意密码过期与密码失效并不相同。
账号失效日期:这个日期跟第三个字段一样,都是使用 1970 年以来的总日数设定。这个字段表示: 这个账号在此字段规定的日期之后,将无法再使用。 就是所谓的了账号失效,此时不论你的密码是否有过期,这个账号都不能再被使用!这个字段会被使用通常应该是在[收费服务]的系统中,你可以规定一个日期让该账号不能再使用啦!
保留:最后一个字段是保留的,看以后有没有新功能加入。
群组
/etc/group 文件结构
这个文件就是在记录GID与组名的对应关系。
这个文件每一行代表一个群组,也是以冒号 : 作为字段的分隔符,共分为四栏,每一字段的意义是:
组名:就是组名啦!同样用来给人类使用的,基本上需要与第三字段的 GID 对应。
群组密码:通常不需要设定,这个设定通常是给[群组管理员] 使用的,目前很少有这个机会设定群组管理员啦! 同样的,密码已经移动到 /etc/gshadow 去,因此这个字段只会存在一个 x 而已。
GID:就是群组的 ID 啊。我们 etc/passwd 第四个字段使用的 GID 对应的群组名,就是由这里对应出来的!
此群组支持的账号名称:我们知道一个账号可以加入多个群组,那某个账号想要加入此群组时,将该账号填入这个字段即可。 举例来说,如果我想要让 dmtsai 与 aex 也加入 root 这个群组,那么在第一行的最后面加上 [dmtsai.alex]注意不要有空格,使成为” root:x:0:dmtsai.alex “就可以了。
/etc/group,/etc/passwd,/etc/shadow之间的关系
谈完了etc/passwd,/etc/shadow,/etc/group 之后,我们可以使用一个简单的图示来了解一下UID/GID 与密码之间的关系, 图示如下。其实重点是 /etc/passwd ,其他相关的数据都是根据这个文件的字段去找寻出来的。下图中, root 的 UID 是 0,而 GID 也是 0 ,去找 /etc/group 可以知道 GID 为 0 时的组名就是 root 。至于密码的寻找中,会找到 etc/shadow 与 /etc/passwd 内同账号名称的那一行,就是密码相关数据了。

至于在 /etc/group 比较重要的特色在于第四栏啦,因为每个使用者都可以拥有多个支持的群组,这就好比在学校念书的时候, 我们可以加入多个社团一样!
groups
知道所有支持的群组。
这个命令,可以查询用户同时属于哪几个群组,而且,第一个输出的群组即为有效群组 (effective group) 了。如果用户dmtsai的有效群组为 dmtsai ,此时,如果以 touch 去建立一个新档,例如: touch test ,那么这个文件的拥有者为 dmtsai,而且群组也是 dmtsai 。
newgrp
有效群组的切换。不过使用 newgrp 是有限制的,那就是你想要切换的群组必须是你已经有支持的群组。这个指令可以变更目前用户的有效群组, 而且是另外以一个 shell 来提供这个功能的,所以,使用者会是以另一个 shell 登入的,而且新的 shell 给予用户有效 GID为新组了。如图:

虽然用户的环境设定(例如环境变量等等其他数据)不会有影响,但是使用者的[群组权限] 将会重新被计算。但是需要注意,由于是新取得一个 shell ,因此如果你想要回到原本的环境中,请输入 exit回到原本的 shell 喔!
/etc/gshadow
gshadow 最大的功能就是建立群组管理员。由于目前有类似 sudo 之类的工具, 所以这个群组管理员的功能已经很少使用了。
四个字段的意义为:
- 组名
- 密码栏,同样的,开头为 !表示无合法密码,所以无群组管理员。
- 群组管理员的账号 (相关信息在 gpasswd 中介绍)
- 有加入该群组支持的所属账号 (与 /etc/group )内容相同
账号管理
useradd
| [root@study ~]# useradd [-u UID] [-g 初始群组] [-G 次要群组] [-mM]\ > [-c 说明栏] [-d 主文件夹绝对路径] [-s shell] 使用者帐号名 选项与参数: -u :后面接的是 UID ,是一组数字。直接指定一个特定的 UID 给这个帐号; -g :后面接的那个群组名称就是我们上面提到的 initial group 啦~ 该群组的 GID 会被放置到 /etc/passwd 的第四个字段内。 -G :后面接的群组名称则是这个帐号还可以加入的群组。 这个选项与参数会修改 /etc/group 内的相关数据喔! -M :强制!不要创建使用者主文件夹!(系统帐号默认值) -m :强制!要创建使用者主文件夹!(一般帐号默认值) -c :这个就是 /etc/passwd 的第五栏的说明内容啦~可以随便我们设置的啦~ -d :指定某个目录成为主文件夹,而不要使用默认值。务必使用绝对路径! -r :创建一个系统的帐号,这个帐号的 UID 会有限制 (参考 /etc/login.defs) -s :后面接一个 shell ,若没有指定则默认是 /bin/bash 的啦~ -e :后面接一个日期,格式为“YYYY-MM-DD”此项目可写入 shadow 第八字段, 亦即帐号失效日的设置项目啰; -f :后面接 shadow 的第七字段项目,指定密码是否会失效。0为立刻失效, -1 为永远不失效(密码只会过期而强制于登陆时重新设置而已。) 范例一:完全参考默认值创建一个使用者,名称为 vbird1 [root@study ~]# useradd vbird1 [root@study ~]# ll -d /home/vbird1 drwx------. 3 vbird1 vbird1 74 Jul 20 21:50 /home/vbird1 # 默认会创建使用者主文件夹,且权限为 700 !这是重点! [root@study ~]# grep vbird1 /etc/passwd /etc/shadow /etc/group /etc/passwd:vbird1:x:1003:1004::/home/vbird1:/bin/bash /etc/shadow:vbird1:!!:16636:0:99999:7::: /etc/group:vbird1:x:1004: <==默认会创建一个与帐号一模一样的群组名 |
CentOS 这些默认值主要会帮我们处理几个项目:
- 在 /etc/passwd 里面建立一行与账号相关的数据,包括建立 UID/GID/家目录等:
- 在 /etc/shadow 里面将此账号的密码相关参数填入,但是尚未有密码;
- 在 /etc/group 里面加入一个与账号名称一模一样的组名;
- 在 /home 底下建立一个与账号同名的目录作为用户家目录,且权限为 700。
我们在谈到 UID 的时候曾经说过一般账号应该是 1000 号以后,那用户自己建立的系统账号则一般是小于 1000 号以下的。 所以在这里我们加上 -r 这个选项以后,系统就会主动将账号与账号同名群组的 UID/GID 都指定小于 1000 以下, 在本案例中则是使用 699(UID) 与699(GID)。
useradd参考文件
(1)/etc/default/useradd
useradd的默认数据都是参考的这个文件。但是Centos有自己的机制,默认值略有不同。useradd 的默认值可以使用下面的方法调用出来:

| 这个数据其实是由 /etc/default/useradd 调用出来的!你可以自行用 vim 去观察该 文件的内容。搭配上头刚刚谈过的范例一的运行结果,上面这些设置项目所造成的行为 分别是: GROUP=100:新建帐号的初始群组使用 GID 为 100 者 系统上面 GID 为 100 者即是 users 这个群组,此设置项目指的就是让新设使 用者帐号的初始群组为 users 这一个的意思。 但是我们知道 CentOS 上面并不是这 样的,在 CentOS 上面默认的群组为与帐号名相同的群组。 举例来说, vbird1 的初 始群组为 vbird1 。怎么会这样啊?这是因为针对群组的角度有两种不同的机制所 致, 这两种机制分别是: 私有群组机制:系统会创建一个与帐号一样的群组给使用者作为初始群组。 这种群组的 设置机制会比较有保密性,这是因为使用者都有自己的群组,而且主文件夹权 限将会设置为 700 (仅有自己可进入自己的主文件夹) 之故。使用这种机制将 不会参考 GROUP=100 这个设置值。代表性的 distributions 有 RHEL, Fedora, CentOS 等; 公共群组机制:就是以 GROUP=100 这个设置值作为新建帐号的初始群组,因此每个帐号 都属于 users 这个群组, 且默认主文件夹通常的权限会是“ drwxr-xr-x ... username users ... ”,由于每个帐号都属于 users 群组,因此大家都可以互相分享主文件夹 内的数据之故。代表 distributions 如 SuSE等。 由于我们的 CentOS 使用私有群组机制,因此这个设置项目是不会生效的! 不要太紧张啊! HOME=/home:使用者主文件夹的基准目录(basedir) 使用者的主文件夹通常是与帐号同名的目录,这个目录将会放置在此设置值的目录后。所以 vbird1 的主文件夹就会在 /home/vbird1/ 了!很容易理解吧! INACTIVE=-1:密码过期后是否会失效的设置值 我们在 shadow 文件结构当中谈过,第七个字段的设置值将会影响到密码过 期后, 在多久时间内还可使用旧密码登陆。这个项目就是在指定该日数啦!如果 是 0 代表密码过期立刻失效, 如果是 -1 则是代表密码永远不会失效,如果是数 字,如 30 ,则代表过期 30 天后才失效。 EXPIRE=:帐号失效的日期 就是 shadow 内的第八字段,你可以直接设置帐号在哪个日期后就直接失 效,而不理会密码的问题。 通常不会设置此项目,但如果是付费的会员制系统, 或许这个字段可以设置喔! SHELL=/bin/bash:默认使用的 shell 程序文件名 SKEL=/etc/skel:使用者主文件夹参考基准目录 这个咚咚就是指定使用者主文件夹的参考基准目录啰~举我们的范例一为 例, vbird1 主文件夹 /home/vbird1 内的各项数据,都是由 /etc/skel 所复制过去的~ 所以呢,未来如果我想要让新增使用者时,该使用者的环境变量 ~/.bashrc 就设置 妥当的话,您可以到 /etc/skel/.bashrc 去编辑一下,也可以创建 /etc/skel/www 这个 目录,那么未来新增使用者后,在他的主文件夹下就会有 www 那个目录了!这样 瞭呼? CREATE_MAIL_SPOOL=yes:创建使用者的 mailbox 你可以使用“ ll /var/spool/mail/vbird1 ”看一下,会发现有这个文件的存在 喔!这就是使用者的邮件信箱! |
(2)/etc/login.defs

| 这个文件规范的数据则是如下所示: mailbox 所在目录: 使用者的默认 mailbox 文件放置的目录在 /var/spool/mail,所以 vbird1 的 mailbox 就是在 /var/spool/mail/vbird1 啰! shadow 密码第 4, 5, 6 字段内容: 通过 PASS_MAX_DAYS 等设置值来指定。所以你知道为何默认的 /etc/shadow 内每一行都会有“ 0:99999:7 ”的存在了吗?^_^!不过要注意的是,由于目前我们登 陆时改用 PAM 模块来进行密码检验,所以那个 PASS_MIN_LEN 是失效的! UID/GID 指定数值: 虽然 Linux 核心支持的帐号可高达 232 这么多个,不过一部主机要作出这么多帐号,在管理上也是很麻烦的! 所以在这里就针对 UID/GID 的范围进行规范。上表中的 UID_MIN 指的就是可登陆系统的一般帐号的最小 UID ,至于UID_MAX则是最大UID之意。 要注意的是,系统给予一个帐号 UID 时,他是 (1)先参考 UID_MIN 设置值取得最小数值; (2)由 /etc/passwd 搜寻最大的 UID 数值, 将 (1) 与 (2) 相比, 找出最大的那个再加一就是新帐号的 UID 了。我们上面已经作出 UID 为 1500 的 vbird2 , 如果再使用“ useradd vbird4 ”时,你猜 vbird4 的 UID 会是多少?答案是: 1501 。 所以中间的 1004~1499 的号码就空下来啦! 而如果我是想要创建系统用的帐号,所以使用 useradd -r sysaccount 这个 -r 的选项 时,就会找“比 201 大但比 1000 小的最大的 UID ”就是了。 ^_^ 用户家目录设置值: 为何我们系统默认会帮使用者创建主文件夹?就是这个“CREATE_HOME = yes”的设置值。这个设置值会让你在使用 useradd 时, 主动加入“ -m ”这个产生主文件夹的选项。如果不想要创建使用者主文件夹,就只能强制加上“ -M ”的选项在 useradd 指令执行时啦!至于创建主文件夹的权限设置呢?就通过 umask 这个设置 值啊!因为是 077 的默认设置,因此使用者主文件夹默认权限才会是“ drwx------ ”哩! 使用者删除与密码设置值:使用“USERGROUPS_ENAB yes”这个设置值的功能是: 如果使用 userdel 去删除一 个帐号时,且该帐号所属的初始群组已经没有人隶属于该群组了, 那么就删除掉 该群组,举例来说,我们刚刚有创建 vbird4 这个帐号,他会主动创建 vbird4 这个 群组。 若 vbird4 这个群组并没有其他帐号将他加入支持的情况下,若使用 userdel vbird4 时,该群组也会被删除的意思。 至于“ENCRYPT_METHOD SHA512”则表示 使用 SHA512 来加密密码明文,而不使用旧式的 MD5。 |
现在你知道啦,使用 useradd 这支程序在创建 Linux 上的帐号时,至少会参考:
/etc/default/useradd, /etc/login.defs, /etc/skel/*这些文件,不过,最重要的其实是创建 /etc/passwd, /etc/shadow, /etc/group, /etc/gshadow 还有使用者主文件夹就是了~所以,如果你了解整个系统运行的状态,也是可以手动直接修改这几个文件就是了。
passwd
要帮一般账号建立密码需要使用『passwd 账号 』的格式,使用『passwd 』表示修改自己的密码!
usermod
usermod命令修改系统帐户及账户相关的各项属性。如果用户的数字用户ID、用户名或用户的主目录发生更改,则必须确保在执行此命令时,命名用户未执行任何进程。usermod在Linux上对此进行检查,但仅检查用户是否根据其他架构上的utmp登录。您必须手动更改任何crontab文件或at作业的所有者。必须在NIS服务器上进行涉及NIS的任何更改。usermod命令的操作修改的是/etc/passwd和/etc/shadow这两个文件中的内容。
userdel
通常我们要移除一个账号的时候,也可以手动的将 /etc/passwd 与/etc/shadow 里头的该账号取消即可!
一般而言,如果该账号只是『暂时不启用』的话,那么将/etc/shadow 里头账号失效日期 (第八字段) 设定为 0 就可以让该账号无法使用,但是所有跟该账号相关的数据都会留下来!
用户功能
id
查询某人或自己相关的UID/GID;id 这个指令则可以查询某人或自己的相关 UID/GID 等等的信息。
finger
finger 类似指纹的功能,他会将使用者的相关属性列出来!其实他列出来的几乎都是 /etc/passwd 文件里面的东西。
chfn
除非是你的主机有很多的用户,否则倒真是用不着这个程序。
chsh
列出目前系统上面可用的 shell ,其实就是 /etc/shells 的内容。设置修改自己的 Shell。
不论是 chfn 与 chsh ,都是能够让一般使用者修改 /etc/passwd 这个系统文件的! 所以你猜猜,这两个文件的权限是什么? 一定是 SUID 的功能啦!
新增删与删除用户组
groupadd
groupmod
groupdel
gpasswd
使用外部身份认证系统
有时候,除了本机的帐号之外,我们可能还会使用到其他外部的身份验证服务器 所提供的验证身份的功能!举例来说, windows 下面有个很有名的身份验证系统,称为 Active Directory (AD)的东西,还有 Linux 为了提供不同主机使用同一组帐号密码, 也会使用到 LDAP, NIS 等服务器提供的身份验证等等!如果你的 Linux 主机要使用到上面提到的这些外部身份验证系统时,可能就得要 额外的设置一些数据了! 为了简化使用者的操作流程,所以 CentOS 提供一只名为 authconfig-tui 的指令给我们参考。
ACL
谨记在Linux中 ACL权限针对的是分区,所以要给某个文件设置ACL权限时,首先要查看文件所在的分区是否开启了ACL权限。

ACL 可以针对单一使用者,单一文件或目录来进行 r,w,x 的权限规范,对于需要特殊权限的使用状况非常有帮助。ACL 主要可以针对哪些方面来控制权限呢?他主要可以针对几个项目:
- 使用者 (user):可以针对使用者来设置权限;
- 群组 (group):针对群组为对象来设置其权限;
- 默认属性 (mask):还可以针对在该目录下在创建新文件/目录时,规范新数据的 默认权限;
也就是说,如果你有一个目录,需要给一堆人使用,每个人或每个群组所需要的 权限并不相同时,在过去,传统的 Linux 三种身份的三种权限是无法达到的, 因为基本 上,传统的 Linux 权限只能针对一个用户、一个群组及非此群组的其他人设置权限而 已,无法针对单一用户或个人来设计权限。 而 ACL 就是为了要改变这个问题.
getfacl
取得某个文件/目录的 ACL 设置项目;
setfacl
设置某个目录/文件的 ACL 规范。利用“ u:使用者:权限 ”的方式来设置
针对单一用户设置:
setfacl -m u:vbird1:rx acl_test1
setfacl -m u::rwx acl_test1 # 设置值中的 u 后面无使用者列表,代表设置该文件拥有者。
针对特定的单一群组设置:
setfacl -m g:mygroup1:rx acl_test1
针对有效权限设置:“ m:权限 ”
mask指使用者或群组所设置的权限必须要存在于 mask 的 权限设置范围内才会生效,此即“有效权限 (effective permission)”。
| 选项 | 功能 |
|---|---|
| -m 参数 | 设定 ACL 权限。如果是给予用户 ACL 权限,参数则使用 "u:用户名:权限" 的格式,例如 setfacl -m u:st:rx /project 表示设定 st 用户对 project 目录具有 rx 权限;如果是给予组 ACL 权限,参数则使用 "g:组名:权限" 格式,例如 setfacl -m g:tgroup:rx /project 表示设定群组 tgroup 对 project 目录具有 rx 权限。 |
| -x 参数 | 删除指定用户(参数使用 u:用户名)或群组(参数使用 g:群组名)的 ACL 权限,例如 setfacl -x u:st /project 表示删除 st 用户对 project 目录的 ACL 权限。 |
| -b | 删除所有的 ACL 权限,例如 setfacl -b /project 表示删除有关 project 目录的所有 ACL 权限。 |
| -d | 设定默认 ACL 权限,命令格式为 "setfacl -m d:u:用户名:权限 文件名"(如果是群组,则使用 d:g:群组名:权限),只对目录生效,指目录中新建立的文件拥有此默认权限,例如 setfacl -m d:u:st:rx /project 表示 st 用户对 project 目录中新建立的文件拥有 rx 权限。默认 ACL 权限只对目录生效。 |
| -R | 递归设定 ACL 权限,指设定的 ACL 权限会对目录下的所有子文件生效,命令格式为 "setfacl -m u:用户名:权限 -R 文件名"(群组使用 g:群组名:权限),例如 setfacl -m u:st:rx -R /project 表示 st 用户对已存在于 project 目录中的子文件和子目录拥有 rx 权限。 |
| -k | 删除默认 ACL 权限。 |
身份切换
su
以“ su - ”直接将身份变成 root 即可,但是这个指令却需要 root 的密码,也就是说, 如果你要以 su 变成 root 的话,你的一般使用者就必须要有 root 的密码才行;
以“ sudo 指令 ”执行 root 的指令串,由于 sudo 需要事先设置妥当,且 sudo 需要输 入使用者自己的密码, 因此多人共管同一部主机时, sudo 要比 su 来的好喔!至少 root 密码不会流出去!
切换root一定要: su -
切换其他用户就是:su -l 用户名
若要完整的切换到新使用者的环境,必须要使用“ su - username ”或“ su -l username”, 才会连同 PATH/USER/MAIL 等变量都转成新使用者的环境;
如果仅想要执行一次 root 的指令,可以利用“ su - -c "指令串" ”的方式来处理;
使用 root 切换成为任何使用者时,并不需要输入新使用者的密码。
sudo
并非 所有人都能够执行 sudo , 而是仅有规范到 /etc/sudoers 内的用户才能够执行 sudo。
sudo 的执行是这样的流程:
-
当使用者执行 sudo 时,系统于 /etc/sudoers 文件中搜寻该使用者是否有执行 sudo 的 权限;
-
若使用者具有可执行 sudo 的权限后,便让使用者“输入使用者自己的密码”来确 认;
-
若密码输入成功,便开始进行 sudo 后续接的指令(但 root 执行 sudo 时,不需要输 入密码);
-
若欲切换的身份与执行者身份相同,那也不需要输入密码。
能否使用 sudo 必须要看 /etc/sudoers 的设置值, 而可使用 sudo 者是通过输入使用者自己的密码来执行后续的指令串。查看/etc/sudoers文件需要使用visudo命令。
用户特殊shell与PAM模块
PAM 可以说是一套应用程序接口 (Application Programming Interface, API),他 提供了一连串的验证机制,只要使用者将验证阶段的需求告知 PAM 后, PAM 就能够回 报使用者验证的结果 (成功或失败)。
我 们同样以 passwd 这个指令的调用 PAM 来说明好了。 当你执行 passwd 后,这支程序调 用 PAM 的流程是:
-
使用者开始执行 /usr/bin/passwd 这支程序,并输入密码;
-
passwd调用PAM模块进行验证;
-
PAM模块会到/etc/pam.d/找寻与程序(passwd)同名的配置文件;
-
依据 /etc/pam.d/passwd 内的设置,引用相关的 PAM 模块逐步进行验证分析;
-
将验证结果(成功、失败以及其他讯息)回传给passwd这支程序;
-
passwd这支程序会根据PAM回传的结果决定下一个动作(重新输入新密码或者通过验证!)
Linux主机上的用户信息传递
如果你想要知道目前已登陆在系统上面的使用者呢?可以通过 w 或 who 来查询。
Centos7批量创建用户
本章重点回顾
- Linux 操作系统上面,关于账号与群组,其实记录的是 UID/GID 的数字而已;
- 使用者的账号/群组与 UID/GID 的对应,参考 /etc/passwd 及 /etc/group 两个文件
- /etc/passwd 文件结构以冒号隔开,共分为七个字段,分别是『账号名称、密码、 UID、 GID、全名、家目录、shell』
- UID 只有 0 与非为 0 两种,非为 0 则为一般账号。一般账号又分为系统账号 (1~999) 及可登入者账号(大于 1000)
- 账号的密码已经移动到 /etc/shadow 文件中,该文件权限为仅有 root 可以更动。该文件分为九个字段,内容为『账号名称、加密密码、密码更动日期、密码最小可变动日期、密码最大需变动日期、密码过期前警告日数、密码失效天数、 账号失效日、保留未使用』
- 使用者可以支持多个群组,其中在新建文件时会影响新文件群组者,为有效群组。而写入 /etc/passwd 的第四个字段者, 称为初始群组。
- 与使用者建立、更改参数、删除有关的指令为: useradd, usermod, userdel 等,密码建立则为 passwd;
- 与群组建立、修改、删除有关的指令为: groupadd, groupmod, groupdel 等;
- 群组的观察与有效群组的切换分别为: groups 及 newgrp 指令;
- useradd 指令作用参考的文件有: /etc/default/useradd, /etc/login.defs, /etc/skel/ 等等
- 观察用户详细的密码参数,可以使用『chage -l 账号 』来处理;
- 用户自行修改参数的指令有: chsh, chfn 等,观察指令则有: id, finger 等
- ACL 的功能需要文件系统有支持, CentOS 7 预设的 XFS 确实有支持 ACL 功能!
- ACL 可进行单一个人或群组的权限管理,但 ACL 的启动需要有文件系统的支持;
- ACL 的设定可使用 setfacl ,查阅则使用 getfacl ;
- 身份切换可使用 su ,亦可使用 sudo ,但使用 sudo 者,必须先以 visudo 设定可使用的指令;
- PAM 模块可进行某些程序的验证程序!与 PAM 模块有关的配置文件位于 /etc/pam.d/* 及 /etc/security/*
- 系统上面账号登入情况的查询,可使用 w, who, last, lastlog 等;
- 在线与使用者交谈可使用 write, wall,脱机状态下可使用 mail 传送邮件!
第十四章 磁盘配额与高级文件系统管理
磁盘配额Quota
磁盘配额的用途
针对网络服务的设计,比较常实用的几个情况是:
- 针对 WWW server ,例如:每个人的网页空间的容量限制!
- 针对 mail server,例如:每个人的邮件空间限制。
- 针对 file server,例如:每个人最大的可用网络硬盘空间 (教学环境中最常见!)
针对 Linux 系统主机上面的设置那么使 用的方向有下面这一些:
- 限制某一群组所能使用的最大磁盘配额 (使用群组限制)
- 限制某一使用者的最大磁盘配额 (使用使用者限制)
- 限制某一目录 (directory, project) 的最大磁盘配额
磁盘配额的使用限制
- 在 EXT 文件系统家族仅能针对整个 filesystem:
- 核心必须支持 quota :
- 只对一般身份使用者有效:例如 root 就不 能设置 quota , 因为整个系统所有的数据几乎都是他的 。
- 若启用 SELinux,不是所有目录均可设置 quota :
Quota 的规范设置项目
- quota 这玩意儿针对 XFS filesystem 的限制项目主要分为下面几个部分:
- 分别针对使用者、群组或个别目录 (user, group & project):
- 容量限制或文件数量限制 (block 或 inode):限制 inode 用量:可以管理使用者可以创建的“文件数量”;限制 block 用量:管理使用者磁盘容量的限制,较常见为这种方式。
- 柔性劝导与硬性规定 (soft/hard):hard:表示使用者的用量绝对不会超过这个限制值,以上面的设置为例, 使用 者所能使用的磁盘容量绝对不会超过 500MBytes ,若超过这个值则系统会锁住 该用户的磁盘使用权;soft:表示使用者在低于 soft 限值时 (此例中为 400MBytes),可以正常使用磁 盘,但若超过 soft 且低于 hard 的限值 (介于 400~500MBytes 之间时),每次使 用者登陆系统时,系统会主动发出磁盘即将爆满的警告讯息, 且会给予一个宽 限时间 (grace time)。不过,若使用者在宽限时间倒数期间就将容量再次降低 于 soft 限值之下, 则宽限时间会停止。
- 会倒数计时的宽限时间 (grace time):
基本上,针对 quota 限制的项目主要有三项,如下所示:
- uquota/usrquota/quota:针对使用者帐号的设置
- gquota/grpquota:针对群组的设置
- pquota/prjquota:针对单一目录的设置,但是不可与 grpquota 同时存在!
主要命令:xfs_quota
软件磁盘战阵列Software Raid
RAID-0 (等量模式, stripe):性能最佳
这种模式的 RAID 会将磁盘先切出等量的区块 (名为chunk,一般可设置 4K~1M 之间), 然后当一 个文件要写入 RAID 时,该文件会依据 chunk 的大小切割好,之后再依序放到各个磁盘 里面去。由于每个磁盘会交错的存放数据, 因此当你的数据要写入 RAID 时,数据会被 等量的放置在各个磁盘上面。越多颗磁盘组成的 RAID-0 性能会越好,因为每颗负责的数据量就更低了!RAID-0 只要有任何一颗磁盘损毁,在 RAID 上面的所有数据都 会遗失而无法读取。
RAID-1 (映射模式, mirror):完整备份
这种模式也是需要相同的磁盘容量的,最好是一模一样的磁盘啦!如果是不同容 量的磁盘组成 RAID-1 时,那么总容量将以最小的那一颗磁盘为主!这种模式主要是“让 同一份数据,完整的保存在两颗磁盘上头”。因此,整体 RAID 的容量几乎少了 50%。虽然 RAID-1 的写入性能不佳,不过读取的性能则还可以啦!
RAID 1+0,RAID 0+1
所谓的 RAID 1+0 就是: (1)先让两颗磁盘组成 RAID 1,并且这样的设置共有两组; (2) 将这两组 RAID 1 再组成一组 RAID 0。这就是 RAID 1+0 啰!反过来说,RAID 0+1 就是 先组成 RAID-0 再组成 RAID-1 的意思。
RAID 5:性能与数据备份的均衡考虑
RAID-5 至少需要三颗以上的磁盘才能够组成这种类型的磁盘阵列。这种磁盘阵 列的数据写入有点类似 RAID-0 , 不过每个循环的写入过程中 (striping),在每颗磁 盘还加入一个同位检查数据 (Parity) ,这个数据会记录其他磁盘的备份数据, 用于当 有磁盘损毁时的救援。RAID 5 的总容量会是整体磁盘数量减一颗。
RAID 6
RAID 6 则使用两颗磁盘的容量作为 parity 的储存,因此整体的 磁盘容量就会少两颗,但是允许出错的磁盘数量就可以达到两颗了! 也就是在 RAID 6 的情况下,同时两颗磁盘损毁时,数据还是可以救回来!

Software, Hardware RAID
硬件磁盘阵列:磁盘阵列卡
软件磁盘阵列: mdadm软件
硬件磁盘阵列在 Linux 下面看起来就是一颗实际的大磁盘,因此硬件磁盘阵列的设备文件名为 /dev/sd[a-p] ,因为使用到 SCSI 的模块之故。至于软件磁盘阵列则是系统仿真的,因此使用的设备文件名是系统的设备文件, 文件名 为 /dev/md0, /dev/md1...,两者的设备文件名并不相同!
逻辑卷管理器Logical Volume Manager
什么是LVM
LVM 的重点在于“可以弹性的调整 filesystem 的容量!
LVM 可以整合多个实体 partition 在一起, 让这些 partitions 看起来就像是一个磁盘一样!而 且,还可以在未来新增或移除其他的实体 partition 到这个 LVM 管理的磁盘当中。
Physical Volume, PV, 实体卷轴
我们实际的 partition (或 Disk) 需要调整系统识别码 (system ID) 成为 8e (LVM 的识别码),然后再经过 pvcreate 的指令将他转成 LVM 最底层的实体卷轴 (PV) ,之后才能够将这些 PV 加以利用! 调整 system ID 的方是就是通过 gdisk 啦!
Volume Group, VG, 卷轴群组
所谓的 LVM 大磁盘就是将许多 PV 整合成这个 VG 的东西就是啦!所以 VG 就是 LVM 组合起来的大磁盘!这么想就好了。 那么这个大磁盘最大可以到多少容 量呢?这与下面要说明的 PE 以及 LVM 的格式版本有关喔~在默认的情况下, 使 用 32位的 Linux 系统时,基本上 LV 最大仅能支持到 65534 个 PE 而已,若使用默 认的 PE 为 4MB 的情况下, 最大容量则仅能达到约 256GB 而已~不过,这个问题 在 64位的 Linux 系统上面已经不存在了!LV 几乎没有啥容量限制了!
Physical Extent, PE, 实体范围区块
LVM 默认使用 4MB 的 PE 区块,而 LVM 的 LV 在 32 位系统上最多仅能含有 65534 个 PE (lvm1 的格式),因此默认的 LVM 的 LV 会有 4M*65534/ (1024M/G)=256G。这个 PE 很有趣喔!他是整个 LVM 最小的储存区块,也就是 说,其实我们的文件数据都是借由写入 PE 来处理的。简单的说,这个 PE 就有点 像文件系统里面的 block 大小啦。 这样说应该就比较好理解了吧?所以调整 PE 会 影响到 LVM 的最大容量喔!不过,在 CentOS 6.x 以后,由于直接使用 lvm2 的各项 格式功能,以及系统转为 64 位,因此这个限制已经不存在了。
Logical Volume, LV, 逻辑卷轴
最终的 VG 还会被切成 LV,这个 LV 就是最后可以被格式化使用的类似分区 的咚咚了!那么 LV 是否可以随意指定大小呢? 当然不可以!既然 PE 是整个 LVM
的最小储存单位,那么LV的大小就与在此LV内的PE总数有关。为了方便使用者 利用 LVM 来管理其系统,因此 LV 的设备文件名通常指定为“ /dev/vgname/lvname ”的样式!
此外,我们刚刚有谈到 LVM 可弹性的变更 filesystem 的容量,那是如何办到 的?其实他就是通过“交换 PE ”来进行数据转换, 将原本 LV 内的 PE 移转到其他设 备中以降低 LV 容量,或将其他设备的 PE 加到此 LV 中以加大容量! VG、LV 与 PE 的关系有点像下图:

LVM 实作流程
LVM 必需要核心有支持且需要安装 lvm2 这个软件, CentOS 与其他较新的Linux发行版已经默认将 lvm 的支持与软件都安装妥当了!
PV阶段 -> VG阶段 -> LV阶段
放大LV容量
需要下面这些流程的:
- VG阶段需要有剩余的容量:因为需要放大文件系统,所以需要放大LV,但是若没 有多的 VG 容量, 那么更上层的 LV 与文件系统就无法放大的。因此,你得要用尽 各种方法来产生多的 VG 容量才行。一般来说,如果 VG 容量不足, 最简单的方法 就是再加硬盘!然后将该硬盘使用上面讲过的 pvcreate 及 vgextend 增加到该 VG 内 即可!
- LV阶段产生更多的可用容量:如果VG的剩余容量足够了,此时就可以利用 lvresize 这个指令来将剩余容量加入到所需要增加的 LV 设备内!过程相当简单!
- 文件系统阶段的放大:我们的Linux实际使用的其实不是LV啊!而是LV这个设备 内的文件系统! 所以一切最终还是要以文件系统为依归!目前在 Linux 环境下,鸟 哥测试过可以放大的文件系统有 XFS 以及 EXT 家族! 至于缩小仅有 EXT 家族, 目前 XFS 文件系统并不支持文件系统的容量缩小喔!要注意!要注意!XFS 放大 文件系统通过简单的 xfs_growfs 指令即可!
LVM动态自动调整磁盘使用率
LVM Thin Volume可以实现实际用多少才分配多少容量给LV。
LVM Thin Volume概念是:先创建一个可 以实支实付、用多少容量才分配实际写入多少容量的磁盘容量储存池 (thin pool), 然 后再由这个 thin pool 去产生一个“指定要固定容量大小的 LV 设备”,这个 LV 就有趣了! 虽然你会看到“宣告上,他的容量可能有 10GB ,但实际上, 该设备用到多少容量时, 才会从 thin pool 去实际取得所需要的容量”!
本章重点回顾
- Quota 可公平的分配系统上面的磁盘容量给使用者;分配的资源可以是磁盘容量 (block)或可创建文件数量(inode);
- Quota 的限制可以有 soft/hard/grace time 等重要项目;
- Quota 是针对整个 filesystem 进行限制,XFS 文件系统可以限制目录!
- Quota 的使用必须要核心与文件系统均支持。文件系统的参数必须含有 usrquota, grpquota, prjquota
- Quota 的 xfs_quota 实作的指令有 report, print, limit, timer... 等指令;磁盘阵列 (RAID) 有硬件与软件之分,Linux 操作系统可支持软件磁盘阵列,通 过 mdadm 套件来达成;
- 磁盘阵列创建的考虑依据为“容量”、“性能”、“数据可靠性”等;
- 磁盘阵列所创建的等级常见有的 raid0, raid1, raid1+0, raid5 及 raid6
- 硬件磁盘阵列的设备文件名与 SCSI 相同,至于 software RAID 则为 /dev/md[0-9] 软件磁盘阵列的状态可借由 /proc/mdstat 文件来了解;
- LVM 强调的是“弹性的变化文件系统的容量”;
- 与 LVM 有关的元件有: PV/VG/PE/LV 等元件,可以被格式化者为 LV
- 新的 LVM 拥有 LVM thin volume 的功能,能够动态调整磁盘的使用率!
- LVM 拥有快照功能,快照可以记录 LV 的数据内容,并与原有的 LV 共享未更动的 数据,备份与还原就变的很简单;
- XFS 通过 xfs_growfs 指令,可以弹性的调整文件系统的大小
第十五章 计划任务
计划任务种类
at :at 是个可以处理仅执行一次就结束调度的指令,不过要执行 at 时, 必须要有 atd 这个服务 (第十七章) 的支持才行。在某些新版的 distributions 中,atd 可能默 认并没有启动,那么 at 这个指令就会失效呢!不过我们的 CentOS 默认是启动的!
crontab :crontab 这个指令所设置的工作将会循环的一直进行下去! 可循环的时间 为分钟、小时、每周、每月或每年等。crontab 除了可以使用指令执行外,亦可编 辑 /etc/crontab 来支持。 至于让 crontab 可以生效的服务则是 crond 这个服务喔!
仅执行一次的任务
首先,确保atd启动。
[root@study ~]# systemctl restart atd # 重新启动 atd 这个服务
[root@study ~]# systemctl enable atd # 让这个服务开机就自动启动
[root@study ~]# systemctl status atd # 查阅一下 atd 目前的状态
然后,使用 at 这个指令来产生所要运行的工作,并将这个工作以文本文件的方式写入/var/spool/at/ 目录内,该工作便能等待 atd 这个服务的使用与执行了。
为了安全考虑,at 的工作情况其实是这样的:
- 先找寻 /etc/at.allow 这个文件,写在这个文件中的使用者才能使用 at ,没有在这个 文件中的使用者则不能使用 at (即使没有写在 at.deny 当中);
- 如果 /etc/at.allow 不存在,就寻找 /etc/at.deny 这个文件,若写在这个 at.deny 的使
- 用者则不能使用 at ,而没有在这个 at.deny 文件中的使用者,就可以使用 at 咯; 3. 如果两个文件都不存在,那么只有 root 可以使用 at 这个指令。
at 的执行与终端机环境无关,而所有 standard output/standard error output 都会传送到执行者的 mailbox 去。
循环执行的任务
循环执行的例行性工作调度则是由 cron (crond) 这个系统服务来控制的。
控制计划任务的命令是:crontab
为了安全考虑,crontab的工作情况其实是这样的:
- /etc/cron.allow:将可以使用 crontab 的帐号写入其中,若不在这个文件内的使用者则不可使用 crontab;
- /etc/cron.deny:将不可以使用 crontab 的帐号写入其中,若未记录到这个文件当中的使用者,就可 以使用 crontab 。
当使用者使用 crontab 这个指令来创建工作调度之后,该项工作就会被纪录到 /var/spool/cron/ 里面去了,而且是以帐号来作为判别的喔!举例来说, dmtsai 使用 crontab 后, 他的工作会被纪录到 /var/spool/cron/dmtsai 里头去!但请注意,不要使用 vi 直接编辑该文件, 因为可能由于输入语法错误,会导致无法执行 cron 喔!另外, cron 执行的每一项工作都会被纪录到 /var/log/cron 这个登录文件中,所以啰,如果你的 Linux 不知道有否被植入木马时,也可以搜寻一下 /var/log/cron 这个登录文件呢!
crontab -e 这个 crontab 其实是 /usr/bin/crontab 这个可执行文件。
/etc/crontab 可是一 个“纯文本文件”,我们可以编辑这个文件。
cron 这个服务的最低侦测限制是“分钟”,所以“ cron 会每分钟去读取一 次 /etc/crontab 与 /var/spool/cron 里面的数据内容 ”,因此,只要你编辑完 /etc/crontab 这 个文件,并且将他储存之后,那么 cron 的设置就自动的会来执行了!
总结:
- 个人化的行为使用“ crontab -e ”:如果你是依据个人需求来创建的例行工作调度, 建议直接使用 crontab -e 来创建你的工作调度较佳! 这样也能保障你的指令行为不 会被大家看到 (/etc/crontab 是大家都能读取的权限喔!);
- 系统维护管理使用“ vim /etc/crontab ”:如果你这个例行工作调度是系统的重要工 作,为了让自己管理方便,同时容易追踪,建议直接写入 /etc/crontab 较佳!
- 自己开发软件使用“ vim /etc/cron.d/newfile ”:如果你是想要自己开发软件,那当然 最好就是使用全新的配置文件,并且放置于 /etc/cron.d/ 目录内即可。
- 固定每小时、每日、每周、每天执行的特别工作:如果与系统维护有关,还是建议 放置到 /etc/crontab 中来集中管理较好。 如果想要偷懒,或者是一定要再某个周期 内进行的任务,也可以放置到上面谈到的几个目录中,直接写入指令即可!
可唤醒停机期间的任务
系统关机了,任务没有被执行怎么办?anacron可以解决。
anacron 存在的目的就在于我们上头提到 的,在处理非 24 小时一直启动的 Linux 系统的 crontab 的执行! 以及因为某些原因导致 的超过时间而没有被执行的调度工作。anacron 也是每个小时被 crond 执行一次,然后 anacron 再去检测相关的调度 任务有没有被执行,如果有超过期限的工作在, 就执行该调度任务,执行完毕或无须 执行任何调度时,anacron 就停止了。
最后,我们来总结一下本章谈到的许多配置文件与目录的关系吧!这样我们才能 了解 crond 与 anacron 的关系:
- crond会主动去读取/etc/crontab,/var/spool/cron/*,/etc/cron.d/*等配置文件,并依 据“分、时、日、月、周”的时间设置去各项工作调度;
- 根据 /etc/cron.d/0hourly 的设置,主动去 /etc/cron.hourly/ 目录下,执行所有在该目录 下的可执行文件;
- 因为/etc/cron.hourly/0anacron这个指令档的缘故,主动的每小时执行anacron,并 调用 /etc/anacrontab 的配置文件;
- 根据 /etc/anacrontab 的设置,依据每天、每周、每月去分析 /etc/cron.daily/, /etc/cron.weekly/, /etc/cron.monthly/ 内的可执行文件,以进行固定周期需要执行的指 令。
本章重点回顾
- 系统可以通过 at 这个指令来调度单一工作的任务!“at TIME”为指令下达的方法, 当 at 进入调度后, 系统执行该调度工作时,会到下达时的目录进行任务;
- at 的执行必须要有 atd 服务的支持,且 /etc/at.deny 为控制是否能够执行的使用者帐 号;
- 通过 atq, atrm 可以查询与删除 at 的工作调度;
- batch 与 at 相同,不过 batch 可在 CPU 工作负载小于 0.8 时才进行后续的工作调 度;
- 系统的循环例行性工作调度使用 crond 这个服务,同时利用 crontab -e 及 /etc/crontab 进行调度的安排;
- crontab -e 设置项目分为六栏,“分、时、日、月、周、指令”为其设置依据; /etc/crontab 设置分为七栏,“分、时、日、月、周、执行者、指令”为其设置依据; anacron 配合 /etc/anacrontab 的设置,可以唤醒停机期间系统未进行的 crontab 任 务!
第十六章 进程管理与SELinux
在 Linux 系统当中:“触发任何一个事件时,系统都会将他定义成为一个程 序,并且给予这个程序一个 ID ,称为 PID,同时依据启发这个程序的使用者与相关属 性关系,给予这个 PID 一组有效的权限设置。”
程序与进程
程序 (program):通常为 binary program ,放置在储存媒体中 (如硬盘、光盘、软盘、磁带等), 为实体文件的型态存在;
进程 (process):程序被触发后,执行者的权限与属性、程序的程序码与所需数据等都会被载入内存中, 操作系统并给予这个内存内的单元一个识别码 (PID),可以说,进程就是一个正在运行中的程序。
有的进程有父进程,PPID。
任务管理 job control
进行工作管理的行为中, 其实每个工作都是目前 bash 的子程序,亦即彼此之间是有相关性的。 我们无法以 job control 的方式由 tty1 的环境去管理 tty2 的 bash !
直接将命令丢到后台中“执行”
最简单的方法就是利用“ & ” ,例如:cp file1 file2 &
在这一串指令中,重点在那个 & 的功能,他表示将 file1 这个文件复制为 file2 ,且放置于背景中执行, 也就是说执行这一个命令之后,在这一个终端接口仍然可以做其他的工作!而当这一个指令 (cp file1 file2) 执行完毕之后,系统将会在你的终端接口显示完成的消息!
最大的好处是: 不怕被 [ctrl]+c 中断。
将目前的任务丢到后台中“暂停”
例如:在 vim 的一般模式下,按下 [ctrl] 及 z 这两个按键,屏幕上会出现 [1] ,表示这是第一个任务, 而那个 + 代表最近一个被丢进后台的任务,且目前在后台默认会被使用的那个任务 (与 fg 这个指令有关 )!而那个 Stopped 则代表目前这个工作的状态。在默认的情况下,使用 [ctrl]-z 丢到后台当中的工作都是“暂停”的状态!
查看目前的后台任务状态:jobs
+ 代表最近被放到后台的工作号码, - 代表最近最后第二个被放置到后台中 的工作号码。
将后台任务拿到前台处理:fg
fg %jobnumbner
让任务在后台下的状态编程运行中:bg
bg %jobnumbner
kill
kill -9 或 kill -15
-9 这个信号通常是用在“强制删除一个不正常的工作”时所使 用的, -15 则是以正常步骤结束一项工作(15也是默认值)。
脱机管理
在这样的情况下,如果你是以远端连线 方式连接到你的 Linux 主机,并且将工作以 & 的方式放到背景去, 请问,在工作尚未 结束的情况下你离线了,该工作还会继续进行吗?答案是“否”!不会继续进行,而是会 被中断掉。
可以尝试使用 nohup 这个指 令来处理。
例如: nohup ./sleep500.sh &
进程管理
查看进程
一个是只能查阅 自己 bash 程序的“ ps -l ”
一个则是可以查阅所有系统运行的程序“ ps aux ”
如果你发现在某个程序的 CMD 后面还接上 <defunct> 时,就代表该程序是 僵尸程序。
top动态查看进程的变化

top前几行的解释:
第一行(top...):这一行显示的信息分别为:
目前的时间,亦即是 00:53:59 那个项目; 开机到目前为止所经过的时间,亦即是 up 6:07, 那个项目; 已经登陆系统的使用者人数,亦即是 3 users, 项目;
系统在 1, 5, 15 分钟的平均工作负载。我们在第十五章谈到的 batch 工作方式为 负载小于 0.8 就是这个负载啰!代表的是 1, 5, 15 分钟,系统平均要负责运行 几个程序(工作)的意思。 越小代表系统越闲置,若高于 1 得要注意你的系 统程序是否太过繁复了!
第二行(Tasks...):显示的是目前程序的总量与个别程序在什么状态(running, sleeping, stopped, zombie)。 比较需要注意的是最后的 zombie 那个数值,如果不是 0 !好好看看到底是那个 process 变成僵尸了吧?
第三行(%Cpus...):显示的是 CPU 的整体负载,每个项目可使用 ? 查阅。需要特 别注意的是 wa 项目,那个项目代表的是 I/O wait, 通常你的系统会变慢都是 I/O 产生的问题比较大!因此这里得要注意这个项目耗用 CPU 的资源喔! 另外,如果 是多核心的设备,可以按下数字键“1”来切换成不同 CPU 的负载率。
第四行与第五行:表示目前的实体内存与虚拟内存 (Mem/Swap) 的使用情况。 再次重申,要注意的是 swap 的使用量要尽量的少!如果 swap 被用的很大量,表 示系统的实体内存实在不足!
第六行:这个是当在 top 程序当中输入指令时,显示状态的地方。
pstree
展示进程之间的相关性。
进程的优先级
PRI 值越低代表越优先的意思。不 过这个 PRI 值是由核心动态调整的, 使用者无法直接调整 PRI 值的。
PRI(new) = PRI(old) + nice
当 nice 值为负值时,那么该程序就会降低 PRI 值,亦即会变的较优先被处理。
nice 值可调整的范围为 -20 ~ 19 ;
root 可随意调整自己或他人程序的 Nice 值,且范围为 -20 ~ 19 ;
一般使用者仅可调整自己程序的 Nice 值,且范围仅为 0 ~ 19 (避免一般用户抢占 系统资源);
一般使用者仅可将 nice 值越调越高,例如本来 nice 为 5 ,则未来仅能调整到大于 5;
这也就是说,要调整某个程序的优先执行序,就是“调整该程序的 nice 值”啦!那 么如何给予某个程序 nice 值呢?有两种方式,分别是:
一开始执行程序就立即给予一个特定的 nice 值:用 nice 指令;
调整某个已经存在的 PID 的 nice 值:用 renice 指令。
查看系统资源
free:查看内存,如果swap用量超过20%,最好家物理内存。
uname:查看系统与内核
uptime:查看系统启动时间与任务负载
netstat:追踪网络。例如:netstat -tulnp
dmesg:分析内核产生的信息
vmstat:检测系统资源变化
特殊文件与进程
如何查询整个系统的 SUID/SGID 的文件呢? 应该是还不会忘记吧?使用 find 即可啊!
find / -perm /6000
我们之前提到的所谓的程序都是在内存当中嘛!而内存当中的数据又都是 写入到 /proc/* 这个目录下的。
查询已使用文件或已执行进程使用的文件
fuser:借由文件(或文件系统)找出正在使用该文件的程序
lsof:列出被进程所使用的文件名称
pidof:找出某个正在执行的进程的PID
本章重点回顾
- 程序 (program):通常为 binary program ,放置在储存媒体中 (如硬盘、光盘、 软盘、磁带等),为实体文件的型态存在;
- 进程(process):程序被触发后,执行者的权限与属性、程序的程序码与所需数 据等都会被载入内存中, 操作系统并给予这个内存内的单元一个识别码 (PID), 可以说,程序就是一个正在运行中的程序。 程序彼此之间是有相关性的,故有父程序与子程序之分。而 Linux 系统所有程序的 父程序就是 init 这个 PID 为 1 号的程序。
- 在 Linux 的程序调用通常称为 fork-and-exec 的流程!程序都会借由父程序以复制 (fork) 的方式产生一个一模一样的子程序, 然后被复制出来的子程序再以 exec 的方式来执行实际要进行的程序,最终就成为一个子程序的存在。 常驻在内存当中的程序通常都是负责一些系统所提供的功能以服务使用者各项任 务,因此这些常驻程序就会被我们称为:服务 (daemon)。
- 在工作管理 (job control) 中,可以出现提示字符让你操作的环境就称为前景 (foreground),至于其他工作就可以让你放入背景 (background) 去暂停或运 行。
- 与 job control 有关的按键与关键字有: &, [ctrl]-z, jobs, fg, bg, kill %n 等; 程序管理的观察指令有: ps, top, pstree 等等; 程序之间是可以互相控制的,传递的讯息 (signal) 主要通过 kill 这个指令在处 理;
- 程序是有优先顺序的,该项目为 Priority,但 PRI 是核心动态调整的,使用者只能 使用 nice 值去微调 PRI
- nice 的给予可以有: nice, renice, top 等指令;
- vmstat 为相当好用的系统资源使用情况观察指令;
- SELinux 当初的设计是为了避免使用者资源的误用,而 SELinux 使用的是 MAC 委任 式存取设置;
- SELinux 的运行中,重点在于主体程序 (Subject) 能否存取目标文件资源 (Object) ,这中间牵涉到政策 (Policy) 内的规则, 以及实际的安全性本文类 别 (type);
- 安全性本文的一般设置为:“Identify:role:type”其中又以 type 最重要;
- SELinux 的模式有: enforcing, permissive, disabled 三种,而启动的政策 (Policy) 主要是 targeted
- SELinux 启动与关闭的配置文件在: /etc/selinux/config
- SELinux 的启动与观察: getenforce, sestatus 等指令
- 重设 SELinux 的安全性本文可使用 restorecon 与 chcon
- 在 SELinux 有启动时,必备的服务至少要启动 auditd 这个! 若要管理默认的 SELinux 布林值,可使用 getsebool, setsebool 来管理!
第十七章认识系统服务
什么是daemon
系统为了某些功能必须要提供一些服务 (不论是系统本身还是网络 方面),这个服务就称为 service 。 但是 service 的提供总是需要程序的运行吧!否则如 何执行呢?所以达成这个 service 的程序我们就称呼他为 daemon 啰! 举例来说,达成 循环型例行性工作调度服务 (service) 的程序为 crond 这个 daemon 啦!
daemon 既然是一只程序执行后的程序,那么 daemon 所处的那个原本的程序 通常是如何命名的呢 (daemon 程序的命名方式)。 每一个服务的开发者,当初在开发他们的服务时,都有特别的故事啦!不过,无论如何,这些服务的名称被创建之后,被挂上 Linux 使用时,通常在服务的名称之后会加上一个 d ,例如例行性命令的创建的 at, 与 cron 这两个服务, 他的程序文件名会被取为 atd 与 crond,这个 d 代表的就是 daemon 的意思。
systemctl的限制:
- systemctl 不可自订参数。
- 如果某个服务启动是管理员自己手动执行启动,而不是使用 systemctl 去启动的 (例如你自己手动输入 crond 以启动 crond 服务),那么 systemd 将无法侦测到该服 务,而无法进一步管理。
- systemd 启动过程中,无法与管理员通过 standard input 传入讯息!因此,自行撰写 systemd 的启动设置时,务必要取消互动机制~(连通过启动时传进的标准输入讯 息也要避免!)
systemd 的配置文件放置目录
systemd 将过去所谓的 daemon 执行脚本通通称为一个服务单位 (unit),而每种服务单位依据功能来区分时,就分类为不同的类型 (type)。 基本的 类型有包括系统服务、数据监听与交换的插槽档服务 (socket)、储存系统状态的快照 类型、提供不同类似执行等级分类的操作环境 (target) 等等。 哇!这么多类型,那设 置时会不会很麻烦呢?其实还好,因为配置文件都放置在下面的目录中:
- /usr/lib/systemd/system/:每个服务最主要的启动脚本设置,有点类似以前的 /etc/init.d 下面的文件;
- /run/systemd/system/:系统执行过程中所产生的服务脚本,这些脚本的优先序要比 /usr/lib/systemd/system/ 高!
- /etc/systemd/system/:管理员依据主机系统的需求所创建的执行脚本,其实这个目录 有点像以前 /etc/rc.d/rc5.d/Sxx 之类的功能!执行优先序又比 /run/systemd/system/ 高 喔!
到底系统开机会不会执行某些服务其实是看 /etc/systemd/system/ 下面 的设置,所以该目录下面就是一大堆链接文件。而实际执行的 systemd 启动脚本配置文 件, 其实都是放置在 /usr/lib/systemd/system/ 下面的喔!因此如果你想要修改某个服务 启动的设置,应该要去 /usr/lib/systemd/system/ 下面修改才对! /etc/systemd/system/ 仅是 链接到正确的执行脚本配置文件而已。所以想要看执行脚本设置,应该就得要到 /usr/lib/systemd/system/ 下面去查阅才对!
systemd的unit类型分类说明
/usr/lib/systemd/system/ 以下的数据如何区分上述所谓的不同的类型 (type) 呢?很简单!看扩展名!

单一服务的启动/开机启动与查看状态


除了 running 跟 dead 之外,还有其他几种状态:
- active (running):正有一只或多只程序正在系统中执行的意思,举例来说,正在 执行中的 vsftpd 就是这种模式。
- active (exited):仅执行一次就正常结束的服务,目前并没有任何程序在系统中执 行。 举例来说,开机或者是挂载时才会进行一次的 quotaon 功能,就是这种模式! quotaon 不须一直执行~只须执行一次之后,就交给文件系统去自行处理啰!通常 用 bash shell 写的小型服务,大多是属于这种类型 (无须常驻内存)。
- active (waiting):正在执行当中,不过还再等待其他的事件才能继续处理。举例 来说,打印的伫列相关服务就是这种状态! 虽然正在启动中,不过,也需要真的 有伫列进来 (打印工作) 这样他才会继续唤醒打印机服务来进行下一步打印的功 能。
- inactive:这个服务目前没有运行的意思。
daemon的默认状态有如下几种:
- enabled:这个 daemon 将在开机时被执行
- disabled:这个 daemon 在开机时不会被执行
- static:这个 daemon 不可以自己启动 (enable 不可),不过可能会被其他的 enabled 的服务来唤醒 (相依属性的服务)
- mask:这个 daemon 无论如何都无法被启动!因为已经被强制注销 (非删除)。可通过 systemctl unmask 方式改回原本状态
systemctl 查看系统上所有的服务
直接执行:systemctl
systemctl 管理不同的操作环境
graphical.target:就是文字加上图形界面,这个项目已经包含了下面的 multi- user.target 项目!
multi-user.target:纯文本模式!
基本上,我们最常使用的当然就是 multi-user 以及 graphical。
查看当前模式:systemctl get-default
切换模式:systemctl isolate multi-user.target
什么是暂停与休眠模式
suspend:挂起、暂停模式会将系统的状态数据保存到内存中,然后关闭掉大部分的系统硬 件,当然,并没有实际关机喔! 当使用者按下唤醒机器的按钮,系统数据会重内 存中回复,然后重新驱动被大部分关闭的硬件,就开始正常运行!唤醒的速度较 快。
hibernate:休眠模式则是将系统状态保存到硬盘当中,保存完毕后,将计算机关 机。当使用者尝试唤醒系统时,系统会开始正常运行, 然后将保存在硬盘中的系 统状态恢复回来。因为数据是由硬盘读出,因此唤醒的性能与你的硬盘速度有关。
systemctl 针对 service 类型的配置文件
systemd 的配置文件大部分放置于 /usr/lib/systemd/system/ 目录内。该目录的文件主要是原本 软件所提供的设置,建议不要修改!而要修改的位置应该放置于 /etc/systemd/system/ 目录内。举例来说,如果你想要额外修改 vsftpd.service 的话, 他们建议要放置到哪些地方呢?
- /usr/lib/systemd/system/vsftpd.service:官方释出的默认配置文件;
- /etc/systemd/system/vsftpd.service.d/custom.conf:在 /etc/systemd/system 下面创建与配 置文件相同文件名的目录,但是要加上 .d 的扩展名。然后在该目录下创建配置文 件即可。另外,配置文件最好附文件名取名为 .conf 较佳! 在这个目录下的文件 会“累加其他设置”进入 /usr/lib/systemd/system/vsftpd.service 内喔!
- /etc/systemd/system/vsftpd.service.wants/*:此目录内的文件为链接文件,设置相依服 务的链接。意思是启动了 vsftpd.service 之后,最好再加上这目录下面建议的服务。
- /etc/systemd/system/vsftpd.service.requires/*:此目录内的文件为链接文件,设置相依 服务的链接。意思是在启动 vsftpd.service 之前,需要事先启动哪些服务的意思。
重新加载配置文件
systemctl daemon-reload
timer
想要使用 systemd 的 timer 功能,你必须要有几个要件:
- 系统的 timer.target 一定要启动
- 要有个 sname.service 的服务存在 (sname 是你自己指定的名称)
- 要有个 sname.timer 的时间启动服务存在
Centos7.x默认启动的服务概要
例如:
firewalld:(系统/网络)就是防火墙!以前有 iptables 与 ip6tables 等防 火墙机制,新的 firewalld 搭配 firewall-cmd 指令,可以快速的 创建好你的防火墙系统喔!因此,从 CentOS 7.1 以后, iptables 服务的启动脚本已经被忽略了! 请使用 firewalld 来取 代 iptables 服务喔!
ModemManager network Net workManager*:(系统/网络)主要就是调制解调器、网络设置等服务!进入 CentOS 7 之后,系统似乎不太希望我们使用 network 服务了, 比较建议的是使用 NetworkManager 搭配 nmcli 指令来处理网 络设置~所以,反而是 NetworkManager 要开,而 network 不 用开哩!
rc-local:(系统)相容于 /etc/rc.d/rc.local 的调用方式!只是,你必须 要让 /etc/rc.d/rc.local 具有 x 的权限后, 这个服务才能真的运 行!否则,你写入 /etc/rc.d/rc.local 的脚本还是不会运行的 喔!
本章重点回顾
- 早期的服务管理使用 systemV 的机制,通过 /etc/init.d/*, service, chkconfig, setup 等指 令来管理服务的启动/关闭/默认启动;
- 从 CentOS 7.x 开始,采用 systemd 的机制,此机制最大功能为平行处理,并采单一 指令管理 (systemctl),开机速度加快!
- systemd 将各服务定义为 unit,而 unit 又分类为 service, socket, target, path, timer 等不 同的类别,方便管理与维护
- 启动/关闭/重新启动的方式为: systemctl [start|stop|restart] unit.service 设置默认启动/默认不启动的方式为: systemctl [enable|disable] unit.service 查询系统所有启动的服务用 systemctl list-units --type=service 而查询所有的服务 (含 不启动) 使用 systemctl list-unit-files --type=service
- systemd 取消了以前的 runlevel 概念 (虽然还是有相容的 target),转而使用不同的 target 操作环境。常见操作环境为 multi-user.targer 与 graphical.target。 不重新开机而 转不同的操作环境使用 systemctl isolate unit.target,而设置默认环境则使用 systemctl set-default unit.target
- systemctl 系统默认的配置文件主要放在 /usr/lib/systemd/system,管理员若要修改或 自行设计时,则建议放在 /etc/systemd/system/ 目录下。
- 管理员应使用 man systemd.unit, man systemd.service, man systemd.timer 查询 /etc/systemd/system/ 下面配置文件的语法, 并使用 systemctl daemon-reload 载入后, 才能自行撰写服务与管理服务喔!
- 除了 atd 与 crond 之外,可以 通过 systemd.timer 亦即 timers.target 的功能,来使用 systemd 的时间管理功能。
- 一些不需要的服务可以关闭喔!
第十八章 日志文件
日志所需服务与程序
CentOS 提供 rsyslog.service 这个服务来统一管理登录文件。
logrotate (日志文件轮询) 来自动化处理登录文件容量与更新的问题。logrotate 基本上,就是将旧的登录文件更改名称,然后创建一个空的登录 文件。
针对日志文件所需的功能,我们需要的服务与程序有:
- systemd-journald.service:最主要的讯息收受者,由 systemd 提供的;
- rsyslog.service : 主 要 登 录 系 统 与 网 络 等 服 务 的 讯 息 ;
- logrotate:主要在进行登录文件的轮替功能。
CentOS 7.x 使用 systemd 提供的 journalctl 日志管理。
日志文件格式
- 事件发生的日期与时间;
- 发生此事件的主机名称;
- 启动此事件的服务名称 (如 systemd, CROND 等) 或指令与函数名称 (如 su, login..);
- 该讯息的实际数据内容。
rsyslog.service
配置文件:/etc/rsyslog.conf
文件规定了“(1)什么服务 (2)的什么等级信息 (3)需要被 记录在哪里(设备或文件)” 这三个东西。
日志文件安全
我们要使用的是 a 这个属性! 你的登录文件如果设置了这个属性的话,那么 他将只能被增加,而不能被删除!
chattr +a /var/log/admin.log
日志服务器的设置

日志文件轮循logrotate
配置文件

分析日志
logwatch
本章重点回顾
- 登录文件可以记录一个事件的何时、何地、何人、何事等四大信息,故系统有问题 时务必查询登录文件;
- 系统的登录文件默认都集中放置到 /var/log/ 目录内,其中又以 messages 记录的信息 最多!
- 登录文件记录的主要服务与程序为: systemd-journald.service, rsyslog.service, rsyslogd
- rsyslogd 的配置文件在 /etc/rsyslog.conf ,内容语法为:“ 服务名称.等级 记载设备或 文件”
- 通过 linux 的 syslog 函数查询,了解上述服务名称有 kernel, user, mail...从 0 到 23 的 服务序号
- 承上,等级从不严重到严重依序有 info, notice, warning, error, critical, alert, emergency等
- rsyslogd 本身有提供登录文件服务器的功能,通过修改 /etc/rsyslog.conf 内容即可达 成;
- logrotate 程序利用 crontab 来进行登录文件的轮替功能;
- logrotate 的配置文件为 /etc/logrotate.conf ,而额外的设置则可写入 /etc/logrotate.d/* 内;
- 新的 CentOS 7 由于内置 systemd-journald.service 的功能,可以使用 journalctl 直接从 内存读出登录文件,查询性能较佳
- logwatch 为 CentOS 7 默认提供的一个登录文件分析软件。
第十九章 启动流程、模块管理与Load
目前各大主流LInux发行版的启动引导程序都是grub2。
简单来说,系统开机的经过可以汇整成下面的流程的:
- 载入 BIOS 的硬件信息与进行自我检测,并依据设置取得第一个可启动的设备;
- 读取并执行第一个启动设备内 MBR 的启动引导程序 (亦即是 grub2, spfdisk 等程序);
- 依据启动引导程序的设置载入 Kernel ,Kernel 会开始侦测硬件与载入驱动程序;
- 在硬件驱动成功后,Kernel 会主动调用 systemd 程序,并以 default.target 流程开机;
- systemd 执行 sysinit.target 初始化系统及 basic.target 准备操作系统; systemd 启动 multi-user.target 下的本机与服务器服务;
- systemd 执行 multi-user.target 下的 /etc/rc.d/rc.local 文件;
- systemd 执行 multi-user.target 下的 getty.target 及登陆服务;
- systemd 执行 graphical 需要的服务
boot loader
boot loader就是启动引导程序。它就在开机设备的第一个扇区 (sector) 内,也就是我们一直谈到的 MBR (Master Boot Record, 主要开机记录区)。它的功能如下:
- 提供选项:使用者可以选择不同的开机项目,这也是多重开机的重要功能!
- 载入核心文件:直接指向可开机的程序区段来开始操作系统;
- 转交其他 loader:将开机管理功能转交给其他 loader 负责。
systemd
它是第一个程序。
CentOS 7.x 的 systemd 开机流程大约是这样:
- local-fs.target+swap.target:这两个target主要在挂载本机/etc/fstab里面所规范的文 件系统与相关的内存交换空间。
- sysinit.target:这个target主要在侦测硬件,载入所需要的核心模块等动作。
- basic.target:载入主要的周边硬件驱动程序与防火墙相关任务
- multi-user.target下面的其它一般系统或网络服务的载入
- 图形界面相关服务如 gdm.service 等其他服务的载入
如果希望系统额外执行某些程序,可将程序命令或脚本绝对路径写入/etc/rc.d/rc.local文件。
Boot Loader:Grub2
忘记root密码
本章重点回顾
- Linux 不可随意关机,否则容易造成文件系统错乱或者是其他无法开机的问题; 开机流程主要是:BIOS、MBR、Loader、kernel+initramfs、systemd 等流程 Loader 具有提供菜单、载入核心文件、转交控制权给其他 loader 等功能。
- boot loader 可以安装在 MBR 或者是每个分区的 boot sector 区域中
- initramfs 可以提供核心在开机过程中所需要的最重要的模块,通常与磁盘及文件系 统有关的模块;
- systemd 的配置文件为主要来自 /etc/systemd/system/default.target 项目; 额外的设备与模块对应,可写入 /etc/modprobe.d/*.conf 中; 核心模块的管理可使用 lsmod, modinfo, rmmod, insmod, modprobe 等指令; modprobe 主要参考 /lib/modules/$(uanem -r)/modules.dep 的设置来载入与卸载核 心模块;
- grub2 的配置文件与相关文件系统定义文件大多放置于 /boot/grub2 目录中,配置文 件名为 grub.cfg
- grub2 对磁盘的代号设置与 Linux 不同,主要通过侦测的顺序来给予设置。如 (hd0) 及 (hd0,1) 等。
- grub.cfg 内每个菜单与 menuentry 有关,而直接指定核心开机时,至少需要 linux16 及 initrd16 两个项目
- grub.cfg 内设置 loader 控制权移交时,最重要者为 chainloader +1 这个项目。 若想要重建 initramfs ,可使用 dracut 或 mkinitrd 处理
- 重新安装 grub2 到 MBR 或 boot sector 时,可以利用 grub2-install 来处理。 若想要进入救援模式,可于开机菜单过程中,在 linux16 的项目后面加入“ rd.break ”或“ init=/bin/bash ”等方式来进入救援模式。
- 我们可以对 grub2 的个别菜单给予不同的密码。
第二十章 基础系统设置与备份策略
网络设置
CentOS 7 开始对于网卡的编号则有另一套规则:
- eno1 :代表由主板 BIOS 内置的网卡
- ens1 :代表由主板 BIOS 内置的 PCI-E 接口的网卡
- enp2s0 :代表 PCI-E 接口的独立网卡,可能有多个插孔,因此会有 s0, s1... 的编号 。
- eth0 :如果上述的名称都不适用,就回到原本的默认网卡编号
想要知道你有多少网卡,直接下达“ ifconfig -a ”全部 列出来即可!
CentOS 7 也希望我们不要手动修改配置文件, 直接使用所谓的 nmcli 这个指令来设置网络参数。
修改主机名:hostnamectl set-hostname www.centos.vbird
日期时间设置
命令:timedatectl
语系设置
命令:localectl
硬件数据的收集
查看硬件设备
dmidecode
硬件资源收集
Linux 有提供几个简单的指 令来将核心所侦测到的硬件叫出来的~ 常见的指令有下面这些:
- gdisk:第七章曾经谈过,可以使用 gdisk -l 将分区表列出;
- dmesg:第十六章谈过, 观察核心运行过程当中所显示的各项讯息记录;
- vmstat:第十六章谈过,可分析系统 (CPU/RAM/IO) 目前的状态;
- lspci:列出整个 PC 系统的 PCI 接口设备!很有用的指令;
- lsusb:列出目前系统上面各个 USB 端口的状态,与连接的 USB 设备;
- iostat:与 vmstat 类似,可实时列出整个 CPU 与周边设备的 Input/Output 状态。
了解磁盘健康状态
smartctl
备份
哪些数据有备份意义
具有备份意义的文件通常可以粗分为两大类,一类是系统基本设置信息、一类则是类似网络 服务的内容数据。
操作系统本身需要备份的文件:
- /etc/ 整个目录
- /home/ 整个目录
- /var/spool/mail/
- /var/spoll/{at|cron}/
- /boot/
- /root/
- 如果你自行安装过其他的软件,那么 /usr/local/ 或 /opt 也最好备份一下!
网络服务的数据库方面:
- 软件本身的设置文件,例如:/etc/ 整个目录,/usr/local/ 整个目录
- 软件服务提供的数据,以 WWW 及 Mariadb 为例:WWW 数据:/var/www 整个目录或 /srv/www 整个目录,及系统的使用者主文件夹 Mariadb : /var/lib/mysql 整个目录
- 其他在 Linux 主机上面提供的服务之数据库文件!
最终推荐备份的目录:
- /etc
- /home
- /root
- /var/spool/mail/, /var/spool/cron/, /var/spool/at/
- /var/lib/
不需要备份的目录:
- /dev :这个随便你要不要备份
- /proc, /sys, /run:这个真的不需要备份啦!
- /mnt, /media:如果你没有在这个目录内放置你自己系统的东西,也不需要备份
- /tmp :干嘛存暂存盘!不需要备份!
备份工具
完整备份常用的工具有 dd, cpio, xfsdump/xfsrestore 等等。
dd 可以直接读取磁盘的扇区 (sector) 而不理会文件系统,是相 当良好的备份工具!不过缺点就是慢很多! cpio 是能够备份所有文件名,不过,得要 配合 find 或其他找文件名的指令才能够处理妥当。以上两个都能够进行完整备份, 但 累积备份就得要额外使用脚本程序来处理。可以直接进行累积备份的就是 xfsdump 这个 指令。
tar 的 -N 选项也可以做差异备份。

也可以通过 rsync 来进行镜像备份喔! 这个 rsync 可以对两个目录进行 镜像 (mirror) ,算是一个非常快速的备份工具。

鸟哥的备份策略
我的备份策略是这样的:
1. 主机硬件:使用一个独立的filesystem来储存备份数据,此filesystem挂载到 /backup 当中;
2. 每日进行:目前仅备份MySQL数据库;
3. 每周进行:包括 /home, /var, /etc, /boot, /usr/local 等目录与特殊服务的目录;
4. 自动处理:这方面利用 /etc/crontab 来自动提供备份的进行;
5. 异地备援:每月定期的将数据分别(a)烧录到光盘上面(b)使用网络传输到另一部机器上面。
每周备份的脚本

每日备份的脚本

crontab配置

远程备份

本章重点回顾
- 网际网络 (Internet) 就是 TCP/IP ,而 IP 的取得需与 ISP 要求。一般常见的取得 IP 的方法有:(1)手动直接设置 (2)自动取得 (dhcp) (3)拨接取得 (4)cable 宽带 等方式。
- 主机的网络设置要成功,必须要有下面的数据:(1)IP (2)Netmask (3) gateway (4)DNS 服务器 等项目;
- 本章新增硬件信息的收集指令有: lspci, lsusb, iostat 等; 备份是系统损毁时等待救援的救星,但造成系统损毁的因素可能有硬件与软件等原 因。
- 由于主机的任务不同,备份的数据与频率等考虑参数也不相同。 常见的备份考虑因素有:关键文件、储存媒体、备份方式(完整/关键)、备份频 率、使用的备份工具等。
- 常见的关键数据有:/etc, /home, /var/spool/mail, /boot, /root 等等 储存媒体的选择方式,需要考虑的地方有:备份速度、媒体的容量、经费与媒体的 可靠性等。
- 与完整备份有关的备份策略主要有:累积备份与差异备份。 累积备份可具有较小的储存数据量、备份速度快速等。但是在还原方面则比差异备 份的还原慢。
- 完整备份的策略中,常用的工具有 dd, cpio, tar, xfsdump 等等。
第二十一章 软件安装
开放源码的软件安装与升级
什么是make与configure
当执行 make 时,make 会在当时的目录下搜寻 Makefile (or makefile) 这个文本 文件,而 Makefile 里面则记录了源代码如何编译的详细信息! make 会自动的判别源代 码是否经过变动了,而自动更新可执行文件,是软件工程师相当好用的一个辅助工具 呢!
make 是一支程序,会去找 Makefile ,那 Makefile 怎么写? 通常软件开发商 都会写一支侦测程序来侦测使用者的作业环境, 以及该作业环境是否有软件开发商所 需要的其他功能,该侦测程序侦测完毕后,就会主动的创建这个 Makefile 的规则文件 啦!通常这支侦测程序的文件名为 configure 或者是 config 。
make 与 configure 运行流程的相关性,要进行的任务其实只有两个,一个是执行 configure 来创建 Makefile , 这个步骤一定要成功!成功之后再以 make 来调用所需要的数据来编译即可!
什么是Tarball的软件
所谓的 Tarball 文件,其实就是将软件的所有源代码文件先以 tar 打包,然后再以 压缩技术来压缩,通常最常见的就是以 gzip 来压缩了。因为利用了 tar 与 gzip 的功能, 所以 tarball 文件一般的扩展名就会写成 *.tar.gz 或者是简写为 *.tgz 啰!不过,近来由于 bzip2 与 xz 的压缩率较佳,所以 Tarball 渐渐的以 bzip2 及 xz 的压缩技术来取代 gzip 啰!因此文件名也会变成 *.tar.bz2, *.tar.xz 之类的哩。所以说, Tarball 是一个软件包, 你将他解压缩之后,里面的文件通常就会有:
- 原始程序码文件;
- 侦测程序文件 (可能是 configure 或 config 等文件名);
- 本软件的简易说明与安装说明 (INSTALL 或 README)。
Tarball包安装
- 将 Tarball 由厂商的网页下载下来;
- 将 Tarball 解开,产生很多的源代码文件;
- 开始以 gcc 进行源代码的编译 (会产生目标文件 object files);
- 然后以 gcc 进行函数库、主、副程序的链接,以形成主要的 binary file;
- 将上述的 binary file 以及相关的配置文件安装至自己的主机上面。
gcc

make宏编译
为什么用make
- 简化编译时所需要下达的指令;
- 若在编译完成之后,修改了某个源代码文件,则 make 仅会针对被修改了的文件进 行编译,其他的 object file 不会被更动;
- 最后可以依照相依性来更新 (update) 可执行文件。
makefile的语法与变量
makefile 里面就具有至少两个标的,分别是 main 与 clean ,如 果我们想要创建 main 的话,输入“make main”,如果想要清除有的没的,输入“make clean”即可啊!而如果想要先清除目标文件再编译 main 这个程序的话,就可以这样输 入:“make clean main”。
Tarball管理
Tarball安装的基础操作
- 取得原始文件:将 tarball 文件在 /usr/local/src 目录下解压缩;
- 取得步骤流程:进入新创建的目录下面,去查阅INSTALL与README等相关文件内容 (很重要的步骤!);
- 相依属性软件安装:根据 INSTALL/README 的内容察看并安装好一些相依的软件(非必要);
- 创建makefile:以自动侦测程序(configure或config)侦测作业环境,并创建Makefile 这个文件;
- 编译:以 make 这个程序并使用该目录下的 Makefile 做为他的参数配置文件,来进行 make (编译或其他) 的动作;
- 安装:以 make 这个程序,并以 Makefile 这个参数配置文件,依据 install 这个标的(target) 的指定来安装到正确的路径!
Tarball安装命令
1. ./configure
这个步骤就是在创建 Makefile 这个文件啰!通常程序开发者会写一支 scripts 来检 查你的 Linux 系统、相关的软件属性等等,这个步骤相当的重要, 因为未来你的安
装信息都是这一步骤内完成的!另外,这个步骤的相关信息应该要参考一下该目录 下的 README 或 INSTALL 相关的文件!
2. make clean
make 会读取 Makefile 中关于 clean 的工作。这个步骤不一定会有,但是希望执行一 下,因为他可以去除目标文件!因为谁也不确定源代码里面到底有没有包含上次编 译过的目标文件 (*.o) 存在,所以当然还是清除一下比较妥当的。 至少等一下新 编译出来的可执行文件我们可以确定是使用自己的机器所编译完成的嘛!
3. make
make 会依据 Makefile 当中的默认工作进行编译的行为!编译的工作主要是进行 gcc 来将源代码编译成为可以被执行的 object files ,但是这些 object files 通常还需要一 些函数库之类的 link 后,才能产生一个完整的可执行文件!使用 make 就是要将源 代码编译成为可以被执行的可可执行文件,而这个可可执行文件会放置在目前所在 的目录之下, 尚未被安装到预定安装的目录中;
4. make install
通常这就是最后的安装步骤了,make 会依据 Makefile 这个文件里面关于 install 的 项目,将上一个步骤所编译完成的数据给他安装到预定的目录中,就完成安装啦!
Tarball安装建议
1. 最好将 tarball 的原始数据解压缩到 /usr/local/src 当中;
2. 安装时,最好安装到 /usr/local 这个默认路径下;
3. 考虑未来的反安装步骤,最好可以将每个软件单独的安装在 /usr/local 下面;
4. 为安装到单独目录的软件之 man page 加入 man path 搜寻:
函数库管理
本章重点回顾
- 源代码其实大多是纯文本文件,需要通过编译器的编译动作后,才能够制作出 Linux 系统能够认识的可执行的 binary file ;
- 开放源代码可以加速软件的更新速度,让软件性能更快、漏洞修补更实时;
- 在 Linux 系统当中,最标准的 C 语言编译器为 gcc ;
- 在编译的过程当中,可以借由其他软件提供的函数库来使用该软件的相关机制与功 能;
- 为了简化编译过程当中的复杂的指令输入,可以借由 make 与 makefile 规则定义, 来简化程序的更新、编译与链接等动作;
- Tarball 为使用 tar 与 gzip/bzip2/xz 压缩功能所打包与压缩的,具有源代码的文件;
- 一般而言,要使用 Tarball 管理 Linux 系统上的软件,最好需要 gcc, make, autoconfig, kernel source, kernel header 等前驱软件才行,所以在安装 Linux 之初,最好就能够选 择 Software development 以及 kernel development 之类的群组;
- 函数库有动态函数库与静态函数库,动态函数库在升级上具有较佳的优势。动态函 数库的扩展名为 *.so 而静态则是 *.a ;
- patch 的主要功能在更新源代码,所以更新源代码之后,还需要进行重新编译的动 作才行;
- 可以利用 ldconfig 与 /etc/ld.so.conf /etc/ld.so.conf.d/*.conf 来制作动态函数库的链接 与高速缓存!
- 通过 MD5/SHA1/SHA256 的编码可以判断下载的文件是否为原本厂商所释出的文 件。
第二十二章 RPM、SRPM、YUM
目前在 Linux 界软件安装方式最常见的有两种,分别是:
dpkg:
这个机制最早是由 Debian Linux 社群所开发出来的,通过 dpkg 的机制, Debian 提 供的软件就能够简单的安装起来,同时还能提供安装后的软件信息,实在非常不 错。 只要是衍生于 Debian 的其他 Linux distributions 大多使用 dpkg 这个机制来管理 软件的, 包括 B2D, Ubuntu 等等。
RPM:
这个机制最早是由 Red Hat 这家公司开发出来的,后来实在很好用,因此很多 distributions 就使用这个机制来作为软件安装的管理方式。包括 Fedora, CentOS, SuSE 等等知名的开发商都是用这咚咚。

什么是 RPM 与 SRPM
rpm优点:
- 由于已经编译完成并且打包完毕,所以软件传输与安装上很方便(不需要再重新 编译);
- 由于软件的信息都已经记录在Linux主机的数据库上,很方便查询、升级与反安装
通常不同的 LInux发行版 所释出的 RPM 文件,并不能用在其他的 LInux发行版 上。例如 CentOS 6.x 的 RPM 文件就无法直接套用在 CentOS 7.x !因此,这样可以发现这些软件管理机制的问 题是:
- 软件文件安装的环境必须与打包时的环境需求一致或相当;
- 需要满足软件的相依属性需求;
- 反安装时需要特别小心,最底层的软件不可先移除,否则可能造成整个系统的问题!
解决这个问题需要SRPM。SRPM 是什么呢?顾名思义,他是 Source RPM 的意思,也就是这个 RPM 文件里面含有源代码哩!特别注意的是,这个 SRPM 所 提供的软件内容“并没有经过编译”, 它提供的是源代码喔!SRPM 的扩展名是以 ***.src.rpm 这种格式来命名的。

rp-pppoe-3.11-5.el7.x86_64.rpm 这的文件的意义为:

RPM
基本上 rpm 这个指令真的就只剩下查询与检验的功能啰! 所以,查询与检验还是要学的,至于安装,通过 yum 就好了!
rpm安装
rpm的安装命令,鸟哥建议直接加-ivh即可。例如:
rpm -ivh /mnt/Packages/rp-pppoe-3.11-5.el7.x86_64.rpm
rpm升级
以 -Uvh 或 -Fvh 来升级即可。
rpm查询

YUM在线升级
yum查询
yum [list|info|search|provides|whatprovides] 参数
yum安装
yum [install|update] 软件
yum删除
yum [remove] 软件
yum配置文件
vim /etc/yum.repos.d/CentOS-Base.repo
文件说明:
- [base]:代表软件库的名字!中括号一定要存在,里面的名称则可以随意取。但是 不能有两个相同的软件库名称, 否则 yum 会不晓得该到哪里去找软件库相关软件 清单文件。
- name:只是说明一下这个软件库的意义而已,重要性不高!
- mirrorlist=:列出这个软件库可以使用的映射站台,如果不想使用,可以注解到这行;
- baseurl=:这个最重要,因为后面接的就是软件库的实际网址! mirrorlist 是由 yum 程序自行去捉映射站台, baseurl 则是指定固定的一个软件库网址!我们刚刚找到 的网址放到这里来啦!
- enable=1:就是让这个软件库被启动。如果不想启动可以使用 enable=0 喔!
- gpgcheck=1:还记得 RPM 的数码签章吗?这就是指定是否需要查阅 RPM 文件内的数字签名!
- gpgkey=:就是数码签章的公钥档所在位置!使用默认值即可
yum清理旧数据

本章重点回顾
- 为了避免使用者自行编译的困扰,开发商自行在特定的硬件与操作系统平台上面预 先编译好软件, 并将软件以特殊格式封包成文件,提供终端用户直接安装到固定 的操作系统上,并提供简单的查询/安装/移除等流程。 此称为软件管理员。常见的 软件管理员有 RPM 与 DPKG 两大主流。
- RPM 的全名是 RedHat Package Manager,原本是由 Red Hat 公司所发展的,流传甚 广;
- RPM 类型的软件中,所含有的软件是经过编译后的 binary program ,所以可以直接 安装在使用者端的系统上, 不过,也由于如此,所以 RPM 对于安装者的环境要求 相当严格;
- RPM 除了将软件安装至使用者的系统上之外,还会将该软件的版本、名称、文件 与目录配置、系统需求等等均记录于数据库 (/var/lib/rpm) 当中,方便未来的查 询与升级、移除;
- RPM 可针对不同的硬件等级来加以编译,制作出来的文件可于扩展名 (i386, i586, i686, x86_64, noarch) 来分辨;
- RPM 最大的问题为软件之间的相依性问题;
- SRPM 为 Source RPM ,内含的文件为 Source code 而非为 binary file ,所以安装 SRPM 时还需要经过 compile ,不过,SRPM 最大的优点就是可以让使用者自行修 改设置参数 (makefile/configure 的参数) ,以符合使用者自己的 Linux 环境;
- RPM 软件的属性相依问题,已经可以借由 yum 或者是 APT 等方式加以克服。 CentOS 使用的就是 yum 机制。
- yum 服务器提供多个不同的软件库放置个别的软件,以提供用户端分别管理软件类别。
第二十三章 x window设置介绍
略。文章来源地址https://www.toymoban.com/news/detail-732323.html
第二十四章 Linux内核编译与管理文章来源:https://www.toymoban.com/news/detail-732323.html
略。
到了这里,关于鸟哥的LInux私房菜 基础学习篇 第四版 学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!