文章来源:https://www.toymoban.com/news/detail-732472.html
文章来源:https://www.toymoban.com/news/detail-732472.html
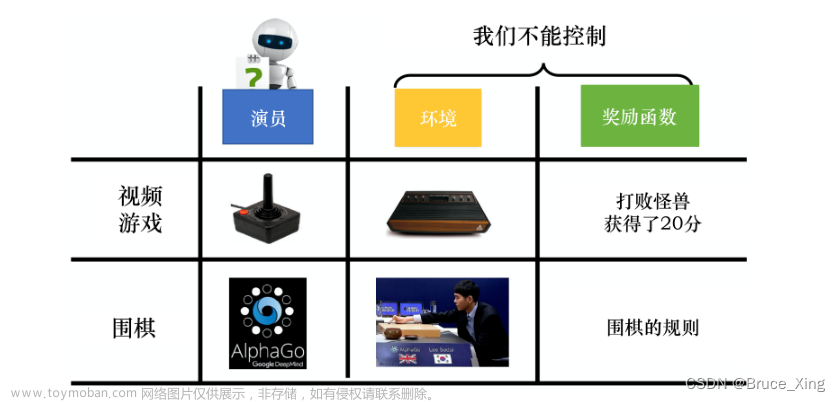
一、说明
什么是梯度惩罚?为什么它比渐变裁剪更好?如何实施梯度惩罚?在提起GAN对抗网络中,就不能避免Wasserstein距离的概念,本篇为系列读物,目的是揭示围绕Wasserstein-GAN建模的一些重要概念进行探讨。文章来源地址https://www.toymoban.com/news/detail-732472.html
到了这里,关于揭秘:Wasserstein GAN与梯度惩罚(WGAN-GP)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![generative-model [ From GAN to WGAN ]](https://imgs.yssmx.com/Uploads/2024/02/686917-1.png)