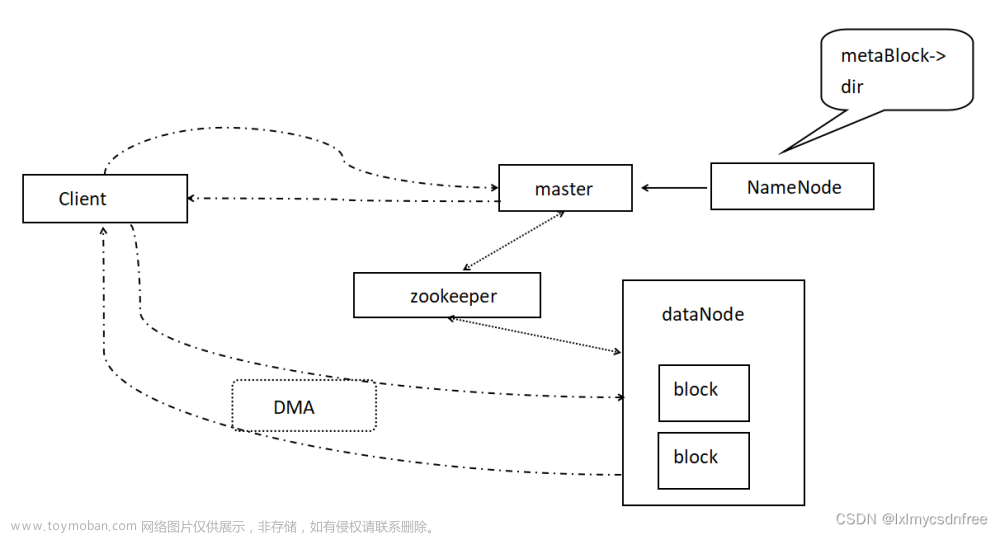
淘宝分布式文件存储系统( 二 ) ->>TFS
目录 :
- 大文件存储结构
- 哈希链表的结构
- 文件映射原理及对应的API
- 文件映射头文件的定义
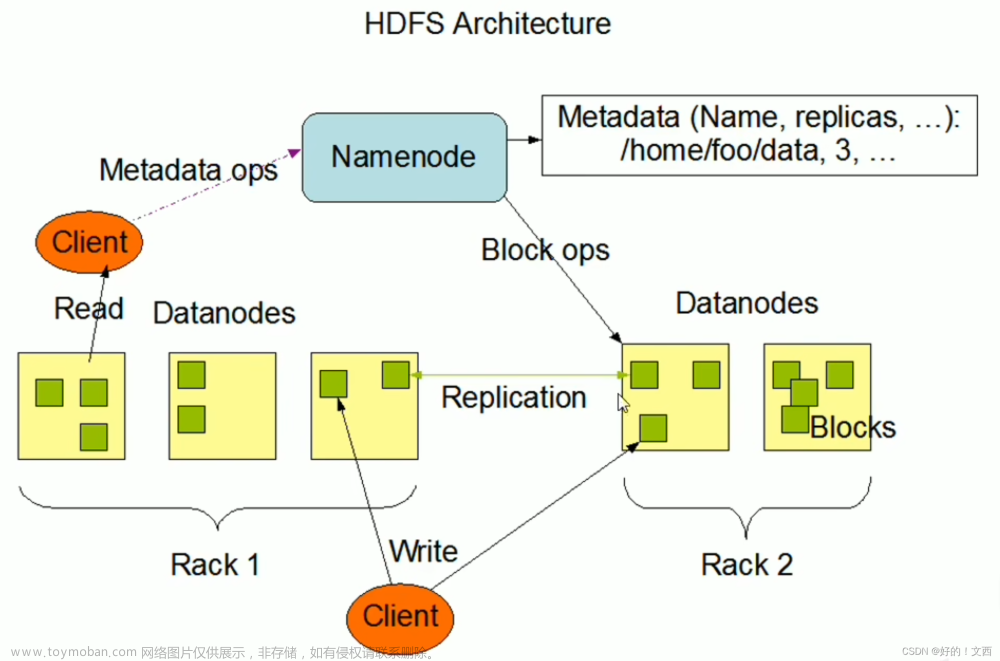
大文件存储结构 :
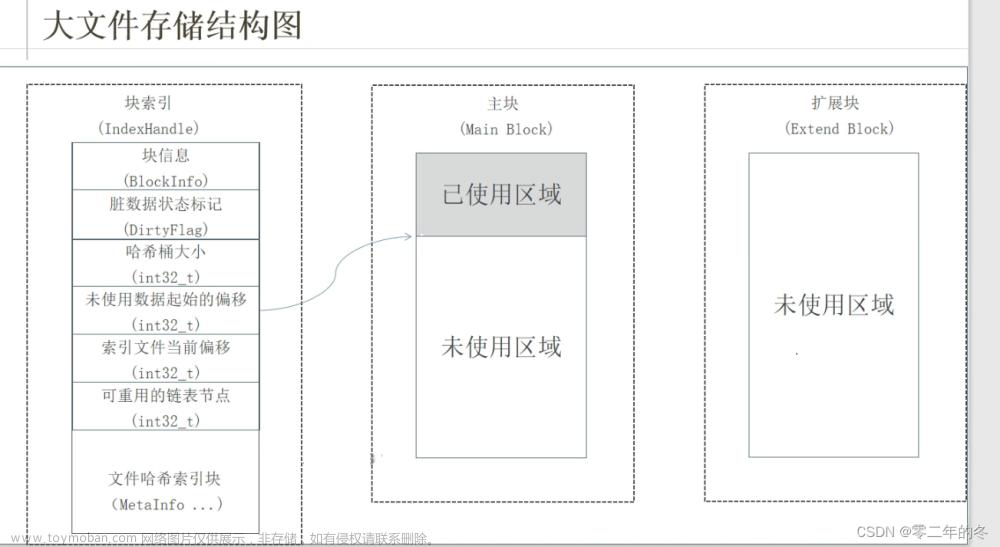
-
- 采用块(block)文件的形式对数据进行存储 , 分成索引块,主块 , 扩展块 。所有的小文件都是存放到主块中的 ,扩展块用来保存溢出的数据,也就是当我们的主快存储不下的时候,数据就会保存到扩展块中。
- 每一个块都有一个唯一的编号 , 块在使用之前所用到的存储空间都会被预先分配和初始化。
- 每个索引文件都存放对应块的信息和小文件的索引信息,所索引文件会在服务器启动时映射(mmap)到内存中,大大提高索引效率。
- 每一个文件都有对应的编号,文件编号从1 开始 依次递增,同时作为哈希表的key来定位小文件在主块和扩展块的偏移量。
-
关键的数据结构 ,1 每一个块的结构
struct BlockInfo //每一个块的结构
{
uint32_t block_id_ ; //块编号1 , 2 ...
int32_t version_ ; //块当前版本号
int32_t file_count_; //当前已保存文件总数
int32_t size_; //当前已保存文件数据的大小
int32_t del_file_count_; //已删除文件的数量
int32_t del_size_ ; // 已删除的文件数据总大小
uint32_t seq_no_; //下一个可分配的文件编号1 , 2 ....
}
补充: 在整个系统里面,删除文件并不是说当用户点击删除之后,就立刻执行删除,事实上我们的系统会对要删除的文件进行标记,表示已经删除,如果不这样,本来磁盘都会进行频繁的读写,再加上立刻删除文件,它会吃不消的,效率也会大大降低,实际上我们服务器的瓶颈就在磁盘。 当系统中删除的文件达到一定量时,会在夜深人静的时候进行数据删除。
- 小文件的索引信息(数据文件,图片,文字,等等)
struct RawMeta
{
uint64_t fileid_; //文件编号
struct{
int32_t inner_offset_; //文件在快内部的偏移量
int32_t size_; //文件大小
} location_;
}
- 这一个结构体,将我们的所有“小文件”,链在一起。
struct MetaInfo
{
struct RawMeta raw_meta_ ; //文件数据
int32_t next_meta_offset_; //当前哈希链下一个节点在索引文件中的偏移
}
哈希链表
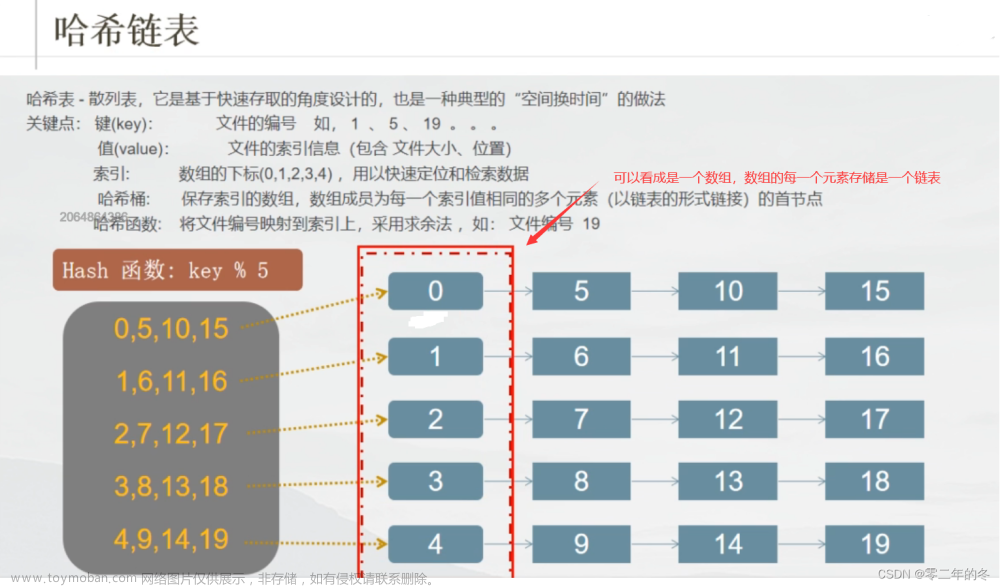
哈希链表结构的定义 :
#define HXSIZE 5 //哈希桶的大小
//定义一个链表结点结构
typedef struct _LinkNode {
void * key; //键值
void* data; //保存的数据, 采用void * 可以提高代码的兼容性(兼容更多的数据类型),和可维护性
struct NodeList* next; //指向下一个结点的指针
}LinkNode;
/**************\
*方便区分,本质上都是一样的
***************/
typedef LinkNode* List;
typedef LinkNode* elment; //表示数据的结点
typedef struct _HxTable {
int size; //桶的大小
List* list; //这里实质上是一个二级指针,(我们可以想象成二维数组)
}HxTable;
文件映射 :
磁盘的速度,和内存的速度比较,相当于是 : 一个走路,一个坐火箭。
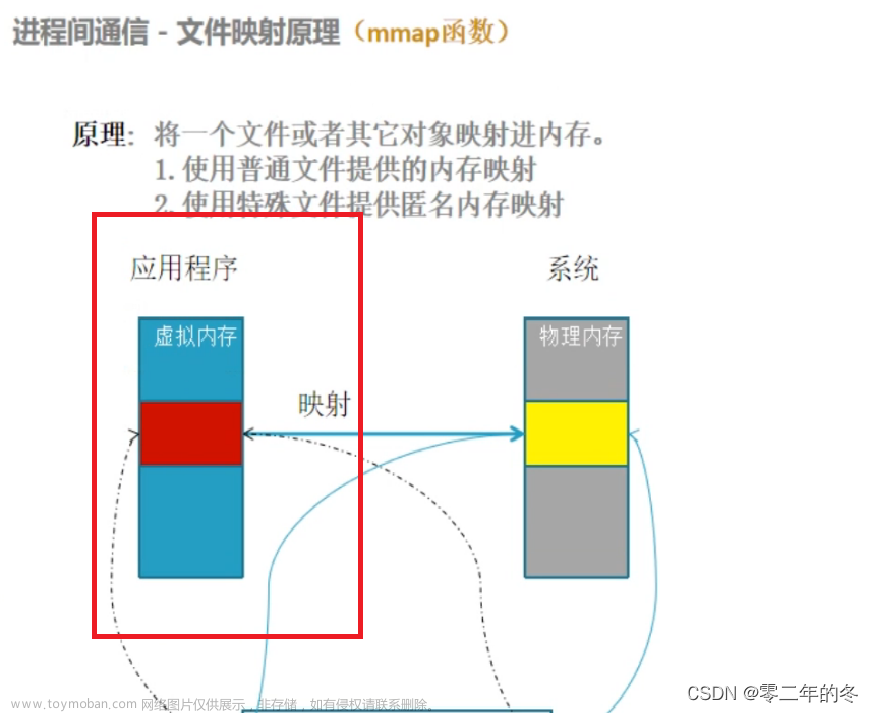
提示: 红色框起的部分,我们可以先不看, 内存映射简单来说就是把磁盘上的文件,映射到内存中.
-
应用场景:
-
1. 实现进程之间共享信息 2. 实现数据从磁盘到内存的映射,提高应用程序访问文件的速度. -
对应的API接口 , 参数很多,但是不用担心,很多都用不上,都是默认的
#include<sys/mmanp> //包含的头文件
//两者配套使用
void *mmap(void *addr , size_t length , int prot , int flags , int fd , size_t offset ); //建立映射
int munmap(void *addr ,size_t length); //解除映射
参数addr : 指向欲映射内存的起始地址 , 一般情况设置为 NULL ,让系统自动选定
参数lenght : 代表文件中多大的部分映射到内存(注意: 大小一般是4kb的整数倍)
参数prot : 映射区域的保护方法
{
PROT_EXEC 执行
PROT_READ 读取
PROT_WRITE 写入
PROT_NONE 不能存取
}
参数flags : 影响映射区域的各种特征,必须指定为 MAP_SHARED / MAP_PRIVATE(修改不同步文件)
参数fd : 要映射到内存中文件的描述符
参数offset : 文件映射映射的偏移量,通常设置为0,代表从文件的开始位置开始对应
进程之间的通信 mmap 之 msync
实现磁盘文件与共享内存区的内容一致(同步操作,共享区域文件的内容发生改变,磁盘上的文件内容也会发生改变)
函数原型 : int msync (void *addr , size_t len , int flags ) ; 成功返回0 ,失败返回-1
参数 addr : 调用mmap(… )返回的地文章来源:https://www.toymoban.com/news/detail-732474.html
参数flags : 刷新的参数设置文章来源地址https://www.toymoban.com/news/detail-732474.html
- MS_ASYNC (异步),调用会立即返回,不等到更新的完成
- MS_SYNC (同步)
映射 mmap_file.h 头文件的实现
#ifndef _MMAP_FILE_H_
#define _MMAP_FILE_H_
#include<unistd.h> //包含很多常规的接口(作为标准库的存在)
//这里我们定义一个命名空间 , 里面的数据我们可以 qiniu::... 这样访问
namespace qiniu {
struct MMapOption { //设置初始映射大小,后序可以增加
int32_t max_mmap_size_; //最大的映射大小
int32_t frist_mmap_size_; //第一次分配的大小
int32_t pri_mmap_size_; //每次追加的大小
};
namespace largefile {
class MMapFile {
public:
MMapFile(); //无参构造
explicit MMapFile(const int fd); //fd文件句柄
MMapFile(const MMapOption& mmp_option, const int fd);
~MMapFile(); //析构函数
bool sync_file(); //同步文件
bool map_file(const bool write = false); //将文件映射到内存,同时设置保护方法
void* get_data()const; //获取映射到内存的数据的首地址
int32_t get_size()const; //返回映射区域的大小
bool munmap_file(); //解除映射
bool remap_file(); //重新映射
private:
bool ensure_flie_size(const int32_t size); //调整大小,仅供内部调用
private:
int32_t size_; //映射的大小
int fd_; //映射文件的句柄
void* data_; //映设到内存数据的起始地址
struct MMapOption mmap_file_option_;
};
}
}
#endif
到了这里,关于淘宝分布式文件存储系统( 二 ) -TFS的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!