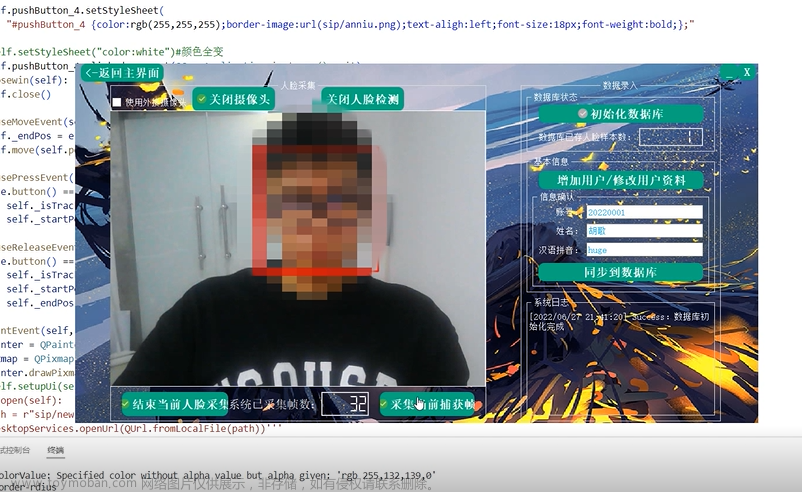
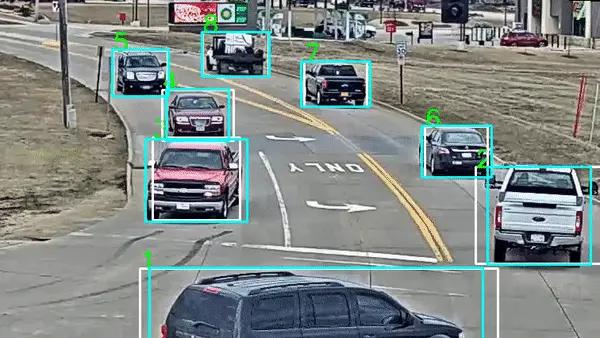
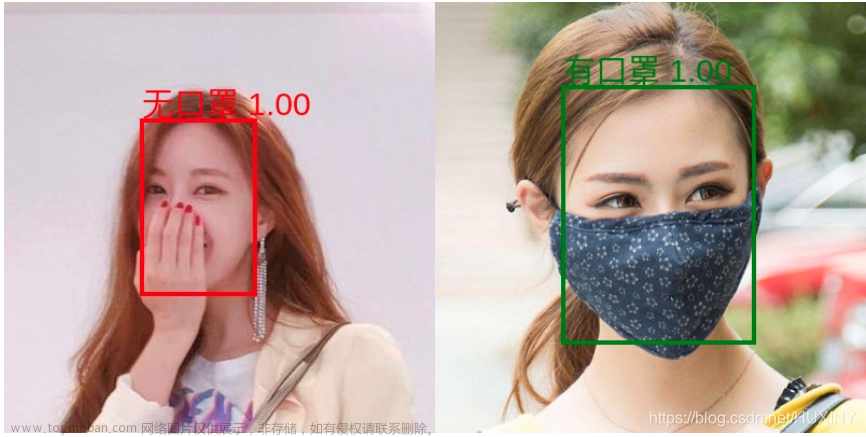
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 机器视觉 opencv 深度学习目标检测
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:文章来源:https://www.toymoban.com/news/detail-732575.html
https://gitee.com/dancheng-senior/postgraduate文章来源地址https://www.toymoban.com/news/detail-732575.html
2 目标检测概念
普通的深度学习监督算法主要是用来做分类,如图1所示,分类的目标是要识别出图中所示是一只猫。
在ILSVRC(ImageNet Large Scale Visual Recognition
Challenge)竞赛以及实际的应用中,还包括目标定位和目标检测等任务。
其中目标定位是不仅仅要识别出来是什么物体(即分类),而且还要预测物体的位置,位置一般用边框(bounding box)标记,如图2所示。
而目标检测实质是多目标的定位,即要在图片中定位多个目标物体,包括分类和定位。
比如对图3进行目标检测,得到的结果是好几只不同动物,他们的位置如图3中不同颜色的框所示。

3 目标分类、定位、检测示例
简单来说,分类、定位和检测的区别如下:
-
分类:是什么?
-
定位:在哪里?是什么?(单个目标)
-
检测:在哪里?分别是什么?(多个目标)
目标检测对于人类来说并不困难,通过对图片中不同颜色模块的感知很容易定位并分类出其中目标物体,但对于计算机来说,面对的是RGB像素矩阵,很难从图像中直接得到狗和猫这样的抽象概念并定位其位置,再加上有时候多个物体和杂乱的背景混杂在一起,目标检测更加困难。
但这难不倒科学家们,在传统视觉领域,目标检测就是一个非常热门的研究方向,一些特定目标的检测,比如人脸检测和行人检测已经有非常成熟的技术了。普通的目标检测也有过很多的尝试,但是效果总是差强人意。
4 传统目标检测
传统的目标检测一般使用滑动窗口的框架,主要包括三个步骤:
1 利用不同尺寸的滑动窗口框住图中的某一部分作为候选区域;
2 提取候选区域相关的视觉特征。比如人脸检测常用的Harr特征;行人检测和普通目标检测常用的HOG特征等;
3 利用分类器进行识别,比如常用的SVM模型。
传统的目标检测中,多尺度形变部件模型DPM(Deformable Part Model是出类拔萃的,连续获得VOC(Visual Object
Class)2007到2009的检测冠军,2010年其作者Felzenszwalb
Pedro被VOC授予”终身成就奖”。DPM把物体看成了多个组成的部件(比如人脸的鼻子、嘴巴等),用部件间的关系来描述物体,这个特性非常符合自然界很多物体的非刚体特征。DPM可以看做是HOG+SVM的扩展,很好的继承了两者的优点,在人脸检测、行人检测等任务上取得了不错的效果,但是DPM相对复杂,检测速度也较慢,从而也出现了很多改进的方法。正当大家热火朝天改进DPM性能的时候,基于深度学习的目标检测横空出世,迅速盖过了DPM的风头,很多之前研究传统目标检测算法的研究者也开始转向深度学习。
基于深度学习的目标检测发展起来后,其实效果也一直难以突破。比如文献[6]中的算法在VOC
2007测试集合上的mAP只能30%多一点,文献[7]中的OverFeat在ILSVRC 2013测试集上的mAP只能达到24.3%。2013年R-
CNN诞生了,VOC 2007测试集的mAP被提升至48%,2014年时通过修改网络结构又飙升到了66%,同时ILSVRC
2013测试集的mAP也被提升至31.4%。
R-CNN是Region-based Convolutional Neural
Networks的缩写,中文翻译是基于区域的卷积神经网络,是一种结合区域提名(Region
Proposal)和卷积神经网络(CNN)的目标检测方法。Ross Girshick在2013年的开山之作《Rich Feature Hierarchies
for Accurate Object Detection and Semantic
Segmentation》[1]奠定了这个子领域的基础,这篇论文后续版本发表在CVPR 2014[2],期刊版本发表在PAMI 2015[3]。
其实在R-CNN之前已经有很多研究者尝试用Deep Learning的方法来做目标检测了,包括OverFeat[7],但R-
CNN是第一个真正可以工业级应用的解决方案,这也和深度学习本身的发展类似,神经网络、卷积网络都不是什么新概念,但在本世纪突然真正变得可行,而一旦可行之后再迅猛发展也不足为奇了。
R-CNN这个领域目前研究非常活跃,先后出现了R-CNN[1,2,3,18]、SPP-net[4,19]、Fast R-CNN[14, 20]
、Faster R-CNN[5,21]、R-FCN[16,24]、YOLO[15,22]、SSD[17,23]等研究。Ross
Girshick作为这个领域的开山鼻祖总是神一样的存在,R-CNN、Fast R-CNN、Faster
R-CNN、YOLO都和他有关。这些创新的工作其实很多时候是把一些传统视觉领域的方法和深度学习结合起来了,比如选择性搜索(Selective
Search)和图像金字塔(Pyramid)等。
5 两类目标检测算法
深度学习相关的目标检测方法也可以大致分为两派:
基于区域提名的,如R-CNN、SPP-net、Fast R-CNN、Faster R-CNN、R-FCN;
端到端(End-to-End),无需区域提名的,如YOLO、SSD。
目前来说,基于区域提名的方法依然占据上风,但端到端的方法速度上优势明显,后续的发展拭目以待。
5.1 相关研究
5.1.1 选择性搜索
目标检测的第一步是要做区域提名(Region Proposal),也就是找出可能的感兴趣区域(Region Of Interest,
ROI)。区域提名类似于光学字符识别(OCR)领域的切分,OCR切分常用过切分方法,简单说就是尽量切碎到小的连通域(比如小的笔画之类),然后再根据相邻块的一些形态学特征进行合并。但目标检测的对象相比OCR领域千差万别,而且图形不规则,大小不一,所以一定程度上可以说区域提名是比OCR切分更难的一个问题。
区域提名可能的方法有:
一、滑动窗口。滑动窗口本质上就是穷举法,利用不同的尺度和长宽比把所有可能的大大小小的块都穷举出来,然后送去识别,识别出来概率大的就留下来。很明显,这样的方法复杂度太高,产生了很多的冗余候选区域,在现实当中不可行。
二、规则块。在穷举法的基础上进行了一些剪枝,只选用固定的大小和长宽比。这在一些特定的应用场景是很有效的,比如拍照搜题APP小猿搜题中的汉字检测,因为汉字方方正正,长宽比大多比较一致,因此用规则块做区域提名是一种比较合适的选择。但是对于普通的目标检测来说,规则块依然需要访问很多的位置,复杂度高。
三、选择性搜索。从机器学习的角度来说,前面的方法召回是不错了,但是精度差强人意,所以问题的核心在于如何有效地去除冗余候选区域。其实冗余候选区域大多是发生了重叠,选择性搜索利用这一点,自底向上合并相邻的重叠区域,从而减少冗余。
区域提名并不只有以上所说的三种方法,实际上这块是非常灵活的,因此变种也很多,有兴趣的读者不妨参考一下文献[12]。
选择性搜索的具体算法细节[8]如算法1所示。总体上选择性搜索是自底向上不断合并候选区域的迭代过程。
输入: 一张图片
输出:候选的目标位置集合L
算法:
1: 利用过切分方法得到候选的区域集合R = {r1,r2,…,rn}
2: 初始化相似集合S = ϕ
3: foreach 邻居区域对(ri,rj) do
4: 计算相似度s(ri,rj)
5: S = S ∪ s(ri,rj)
6: while S not=ϕ do
7: 得到最大的相似度s(ri,rj)=max(S)
8: 合并对应的区域rt = ri ∪ rj
9: 移除ri对应的所有相似度:S = S\s(ri,r*)
10: 移除rj对应的所有相似度:S = S\s(r*,rj)
11: 计算rt对应的相似度集合St
12: S = S ∪ St
13: R = R ∪ rt
14: L = R中所有区域对应的边框
算法1 选择性搜索算法
从算法不难看出,R中的区域都是合并后的,因此减少了不少冗余,相当于准确率提升了,但是别忘了我们还需要继续保证召回率,因此算法1中的相似度计算策略就显得非常关键了。如果简单采用一种策略很容易错误合并不相似的区域,比如只考虑轮廓时,不同颜色的区域很容易被误合并。选择性搜索采用多样性策略来增加候选区域以保证召回,比如颜色空间考虑RGB、灰度、HSV及其变种等,相似度计算时既考虑颜色相似度,又考虑纹理、大小、重叠情况等。
总体上,选择性搜索是一种比较朴素的区域提名方法,被早期的基于深度学习的目标检测方法(包括Overfeat和R-CNN等)广泛利用,但被当前的新方法弃用了。
5.1.2 OverFeat
OverFeat是用CNN统一来做分类、定位和检测的经典之作,作者是深度学习大神之一Yann Lecun在纽约大学的团队。OverFeat也是ILSVRC
2013任务3(分类+定位)的冠军得主。
OverFeat的核心思想有三点:
1 区域提名:结合滑动窗口和规则块,即多尺度(multi-scale)的滑动窗口;
2
分类和定位:统一用CNN来做分类和预测边框位置,模型与AlexNet[12]类似,其中1-5层为特征抽取层,即将图片转换为固定维度的特征向量,6-9层为分类层(分类任务专用),不同的任务(分类、定位、检测)公用特征抽取层(1-5层),只替换6-9层;
3
累积:因为用了滑动窗口,同一个目标对象会有多个位置,也就是多个视角;因为用了多尺度,同一个目标对象又会有多个大小不一的块。这些不同位置和不同大小块上的分类置信度会进行累加,从而使得判定更为准确。
OverFeat的关键步骤有四步:
1
利用滑动窗口进行不同尺度的区域提名,然后使用CNN模型对每个区域进行分类,得到类别和置信度。从图中可以看出,不同缩放比例时,检测出来的目标对象数量和种类存在较大差异;

2 利用多尺度滑动窗口来增加检测数量,提升分类效果,如图3所示;

3 用回归模型预测每个对象的位置,从图4中来看,放大比例较大的图片,边框数量也较多;

4 边框合并。

Overfeat是CNN用来做目标检测的早期工作,主要思想是采用了多尺度滑动窗口来做分类、定位和检测,虽然是多个任务但重用了模型前面几层,这种模型重用的思路也是后来R-
CNN系列不断沿用和改进的经典做法。
当然Overfeat也是有不少缺点的,至少速度和效果都有很大改进空间,后面的R-CNN系列在这两方面做了很多提升。
5.2 基于区域提名的方法
主要介绍基于区域提名的方法,包括R-CNN、SPP-net、Fast R-CNN、Faster R-CNN、R-FCN。
5.2.1 R-CNN
如前面所述,早期的目标检测,大都使用滑动窗口的方式进行窗口提名,这种方式本质是穷举法,R-CNN采用的是Selective Search。
以下是R-CNN的主要步骤:
区域提名:通过Selective Search从原始图片提取2000个左右区域候选框;
区域大小归一化:把所有侯选框缩放成固定大小(原文采用227×227);
特征提取:通过CNN网络,提取特征;
分类与回归:在特征层的基础上添加两个全连接层,再用SVM分类来做识别,用线性回归来微调边框位置与大小,其中每个类别单独训练一个边框回归器。
其中目标检测系统的结构如图6所示,注意,图中的第2步对应步骤中的1、2步,即包括区域提名和区域大小归一化。

Overfeat可以看做是R-CNN的一个特殊情况,只需要把Selective
Search换成多尺度的滑动窗口,每个类别的边框回归器换成统一的边框回归器,SVM换为多层网络即可。但是Overfeat实际比R-
CNN快9倍,这主要得益于卷积相关的共享计算。
事实上,R-CNN有很多缺点:
重复计算:R-CNN虽然不再是穷举,但依然有两千个左右的候选框,这些候选框都需要进行CNN操作,计算量依然很大,其中有不少其实是重复计算;
SVM模型:而且还是线性模型,在标注数据不缺的时候显然不是最好的选择;
训练测试分为多步:区域提名、特征提取、分类、回归都是断开的训练的过程,中间数据还需要单独保存;
训练的空间和时间代价很高:卷积出来的特征需要先存在硬盘上,这些特征需要几百G的存储空间;
慢:前面的缺点最终导致R-CNN出奇的慢,GPU上处理一张图片需要13秒,CPU上则需要53秒[2]。
当然,R-CNN这次是冲着效果来的,其中ILSVRC 2013数据集上的mAP由Overfeat的24.3%提升到了31.4%,第一次有了质的改变。
5.2.2 SPP-net
SPP-net是MSRA何恺明等人提出的,其主要思想是去掉了原始图像上的crop/warp等操作,换成了在卷积特征上的空间金字塔池化层(Spatial
Pyramid Pooling,SPP),如图7所示。为何要引入SPP层
,主要原因是CNN的全连接层要求输入图片是大小一致的,而实际中的输入图片往往大小不一,如果直接缩放到同一尺寸,很可能有的物体会充满整个图片,而有的物体可能只能占到图片的一角。传统的解决方案是进行不同位置的裁剪,但是这些裁剪技术都可能会导致一些问题出现,比如图7中的crop会导致物体不全,warp导致物体被拉伸后形变严重,SPP就是为了解决这种问题的。SPP对整图提取固定维度的特征,再把图片均分成4份,每份提取相同维度的特征,再把图片均分为16份,以此类推。可以看出,无论图片大小如何,提取出来的维度数据都是一致的,这样就可以统一送至全连接层了。SPP思想在后来的R-
CNN模型中也被广泛用到。

SPP-net的网络结构如图8所示,实质是最后一层卷积层后加了一个SPP层,将维度不一的卷积特征转换为维度一致的全连接输入。

SPP-net做目标检测的主要步骤为:
1 区域提名:用Selective Search从原图中生成2000个左右的候选窗口;
2 区域大小缩放:SPP-net不再做区域大小归一化,而是缩放到min(w,
h)=s,即统一长宽的最短边长度,s选自{480,576,688,864,1200}中的一个,选择的标准是使得缩放后的候选框大小与224×224最接近;
3 特征提取:利用SPP-net网络结构提取特征;
4 分类与回归:类似R-CNN,利用SVM基于上面的特征训练分类器模型,用边框回归来微调候选框的位置。
SPP-net解决了R-CNN区域提名时crop/warp带来的偏差问题,提出了SPP层,使得输入的候选框可大可小,但其他方面依然和R-
CNN一样,因而依然存在不少问题,这就有了后面的Fast R-CNN。
5.2.3 Fast R-CNN
Fast R-CNN是要解决R-CNN和SPP-net两千个左右候选框带来的重复计算问题,其主要思想为:
1 使用一个简化的SPP层 —— RoI(Region of Interesting) Pooling层,操作与SPP类似;
2 训练和测试是不再分多步:不再需要额外的硬盘来存储中间层的特征,梯度能够通过RoI Pooling层直接传播;此外,分类和回归用Multi-
task的方式一起进行;
3 SVD:使用SVD分解全连接层的参数矩阵,压缩为两个规模小很多的全连接层。
Fast R-CNN的主要步骤如下:
1 特征提取:以整张图片为输入利用CNN得到图片的特征层;
2 区域提名:通过Selective Search等方法从原始图片提取区域候选框,并把这些候选框一一投影到最后的特征层;
3 区域归一化:针对特征层上的每个区域候选框进行RoI Pooling操作,得到固定大小的特征表示;
4 分类与回归:然后再通过两个全连接层,分别用softmax多分类做目标识别,用回归模型进行边框位置与大小微调。

Fast R-CNN比R-CNN的训练速度(大模型L)快8.8倍,测试时间快213倍,比SPP-net训练速度快2.6倍,测试速度快10倍左右。

5.3 端到端的方法
介绍端到端(End-to-End)的目标检测方法,这些方法无需区域提名,包括YOLO和SSD。
YOLO
YOLO的全拼是You Only Look Once,顾名思义就是只看一次,进一步把目标判定和目标识别合二为一,所以识
网络的整体结构如图所示,针对一张图片,YOLO的处理步骤为:
把输入图片缩放到448×448大小;
运行卷积网络;
对模型置信度卡阈值,得到目标位置与类别。

网络的模型如图15所示,将448×448大小的图切成S×S的网格,目标中心点所在的格子负责该目标的相关检测,每个网格预测B个边框及其置信度,以及C种类别的概率。YOLO中S=7,B=2,C取决于数据集中物体类别数量,比如VOC数据集就是C=20。对VOC数据集来说,YOLO就是把图片统一缩放到448×448,然后每张图平均划分为7×7=49个小格子,每个格子预测2个矩形框及其置信度,以及20种类别的概率。

YOLO简化了整个目标检测流程,速度的提升也很大,但是YOLO还是有不少可以改进的地方,比如S×S的网格就是一个比较启发式的策略,如果两个小目标同时落入一个格子中,模型也只能预测一个;另一个问题是Loss函数对不同大小的bbox未做区分。
SSD
SSD[17,23]的全拼是Single Shot MultiBox
Detector,冲着YOLO的缺点来的。SSD的框架如图16所示,图16(a)表示带有两个Ground
Truth边框的输入图片,图16(b)和©分别表示8×8网格和4×4网格,显然前者适合检测小的目标,比如图片中的猫,后者适合检测大的目标,比如图片中的狗。在每个格子上有一系列固定大小的Box(有点类似前面提到的Anchor
Box),这些在SSD称为Default Box,用来框定目标物体的位置,在训练的时候Ground
Truth会赋予给某个固定的Box,比如图16(b)中的蓝框和图16©中的红框

SSD的网络分为两部分,前面的是用于图像分类的标准网络(去掉了分类相关的层),后面的网络是用于检测的多尺度特征映射层,从而达到检测不同大小的目标。SSD和YOLO的网络结构对比如图17所示。

SSD在保持YOLO高速的同时效果也提升很多,主要是借鉴了Faster
R-CNN中的Anchor机制,同时使用了多尺度。但是从原理依然可以看出,Default
Box的形状以及网格大小是事先固定的,那么对特定的图片小目标的提取会不够好。
6 人体检测结果


7 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
到了这里,关于计算机竞赛 机器视觉目标检测 - opencv 深度学习的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!