前言
随着业务的增长,数据表可能要占用很大的物理存储空间,为了解决该问题,后期使用数据库分片技术。将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该使用分布式ID生成策略来生成ID。
提示:以下是本篇文章正文内容文章来源:https://www.toymoban.com/news/detail-732854.html
一、分布式id技术选型
- redis,优势是(INCR)生成一个全局连续递增的数字类型主键,劣势是增加了一个外部组件的依赖,redis不可用,则整个数据库将无法插入
- UUID,优势是全局唯一,mysql也有UUID实现,劣势是36个字符组成,占用空间大
- snowflake(雪花)算法,优势是全局唯一,数字类型,存储成本低,机器规模大于1024台无法支持。
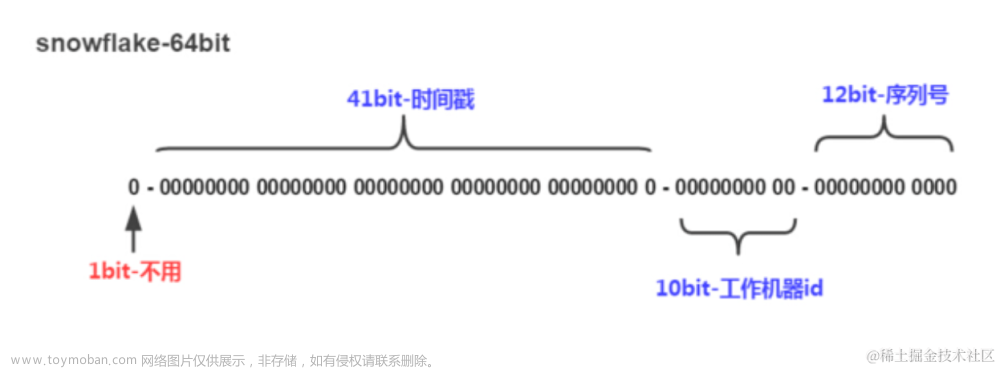
二、雪花算法
- snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。

三、在项目中集成雪花算法
mybatis-plus已经集成了雪花算法,完成以下两步即可在项目中集成雪花算法:文章来源地址https://www.toymoban.com/news/detail-732854.html
- 在实体类中的id上加入如下配置,指定类型为id_worker
@TableId(value = "id",type = IdType.ID_WORKER)
private Long id;
- 在application.yml文件中配置数据中心id和机器id
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
type-aliases-package: com.model.pojos
global-config:
datacenter-id: 1
workerId: 1
到了这里,关于分布式id的概述与实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!