参考:https://www.youtube.com/watch?v=mlk0rddP3L4&list=PLuhqtP7jdD8CftMk831qdE8BlIteSaNzD
视频1: 简单介绍神经网络的基本概念,以及一个训练好的神经网络是怎么使用的
分类算法中,神经网络在训练过程中会学习输入的 pattern,这个 pattern 会被用来区分以后的新输入
神经网络分为如图三层
输入层的神经元数量等于输入的特征数量
以图像识别为例,下图所需的神经元数量是 2352

如下图是输出层,我们的图中输出层只有一个神经元,所以只能做二元分类

隐藏层通常用于保存 “pattern”
通常来说,隐藏层越多,就能用于识别越复杂的图像,做更复杂更精细的分类。但是同样的,隐藏层越多、神经元越多,也会带来更大的存储开销和计算开销。
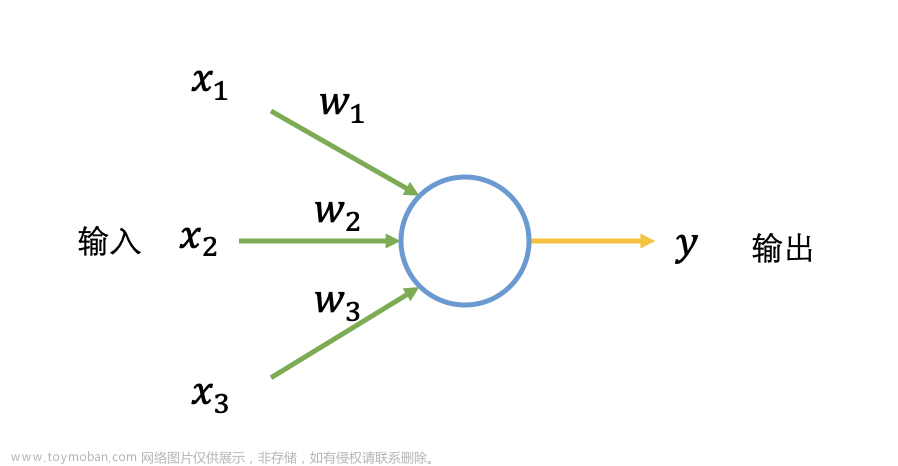
相邻两层的神经元之间有两两相连的 “边(连接)”。每条边都有权重,这个权重是被我们训练出来的。
权重的用法是:用来做 “加权乘法和(权重和)”,也可以直观的解释下,就说是给每个特征一些权重,如下图

如上图,通常还会有个 bias
下一个概念:激活函数。通常,一个神经元的输出是激活函数的输出,而这个激活函数的 输入/参数 就是刚刚计算的权重和
需要注意的是 a21 神经元,以及和它同一层的神经元接下来也会做 权重和,然后继续对 a3? 等等神经元做同样的事情,这样一层一层传递下去,直到最后计算出 output layer
那么接下来的问题是:这些“边”的权重是怎么被计算的?

如上图,首先给这些边分配随机值,接着进行训练,训练过程会改变权重的值。
关于具体的训练过程,看下个视频。
视频2:大致介绍一些训练神经网络的框架、轮廓,没有深入细节
(谷歌浏览器无障碍字幕挺好用的)
视频里先介绍了计算、讨论神经网络时一些符号的意义

如上图,说明了,下一层神经元的值,和上一层神经元的值之间的关系,其实可以用一个矩阵计算的公式来表示
这里有一个前提,就是所有神经元(至少同一层)的激活函数都是一样的,那么我们才可以用同一个 f 来计算神经元的值
不同的输入,会激活不同的神经元
使用神经网络的过程中,我们会看到输入层计算权重和传到隐藏层,隐藏层不同的神经元被激活,再计算权重和传到下一个隐藏层… 这个过程就叫做 向前传播
Forward Propagation
向前传播算法如下图

那么,我们如何训练神经网络,来找到适合的权重矩阵和 bias 呢?
如下图,是 cost 函数,它的意思就是:模型的输出和实际值之间的差。
“改变 权重矩阵 和 bias,让 cost 函数的输出最小化” 这个就是训练模型的过程
如下图,如果我们可以绘制 cost 和 weight 的关系如下图,这是一个有全局最优的图,那么我们就可以用梯度下降法来优化权重矩阵
alpha 是学习速率,它旁边那个东西是曲线的斜率
当然了,神经网络中的参数有很多,每两层神经元之间都有一对 权重矩阵 和 bias,所以训练过程如下,我们会计算 cost 函数和不同参数的斜率、求导,随后进行梯度下降法进行优化

如上图,在我们优化参数的时候,我们在最小化 cost,cost 取决于 a2,a2取决于 W2 和 a1,a1 取决于 W1 和 a0。这个向后的过程我们就叫做向后传播算法, back propagation
一个整体的训练模型过程如下文章来源:https://www.toymoban.com/news/detail-732864.html
 文章来源地址https://www.toymoban.com/news/detail-732864.html
文章来源地址https://www.toymoban.com/news/detail-732864.html
到了这里,关于什么是神经网络,它的原理是啥?(1)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[深度学习入门]什么是神经网络?[神经网络的架构、工作、激活函数]](https://imgs.yssmx.com/Uploads/2024/02/584734-1.png)





