大语言模型生成内容主要基于语言模型算法。语言模型是一种机器学习算法,它可以根据给定文本来预测下一个词语或字符的出现的概率。语言模型通过大量的文本数据来学习语言的统计特征,进而生成具有相似统计特征的新文本。其核心目标是建立一个统计模型,用来估计文本序列中每个词语或字符出现的概率,从而实现语言生成、语言理解等自然语言处理任务。
对于大语言模型来说,需要使用大量的文本数据来训练,以便学习语言的统计特征。在训练过程中,模型会尝试生成与训练数据相似的新文本。为了生成新的文本,模型会根据已经学到的统计特征来预测下一个词语或字符的概率分布,并从中选择最有可能的选项。
大语言模型可以用来生成各种类型的文本,例如新闻报道、小说、电子邮件等等。一般来说,大语言模型生成的文本还需要经过后期编辑和校对,以确保文本的正确性和可读性。
1.Transformer的诞生



2.Transformer的工作原理



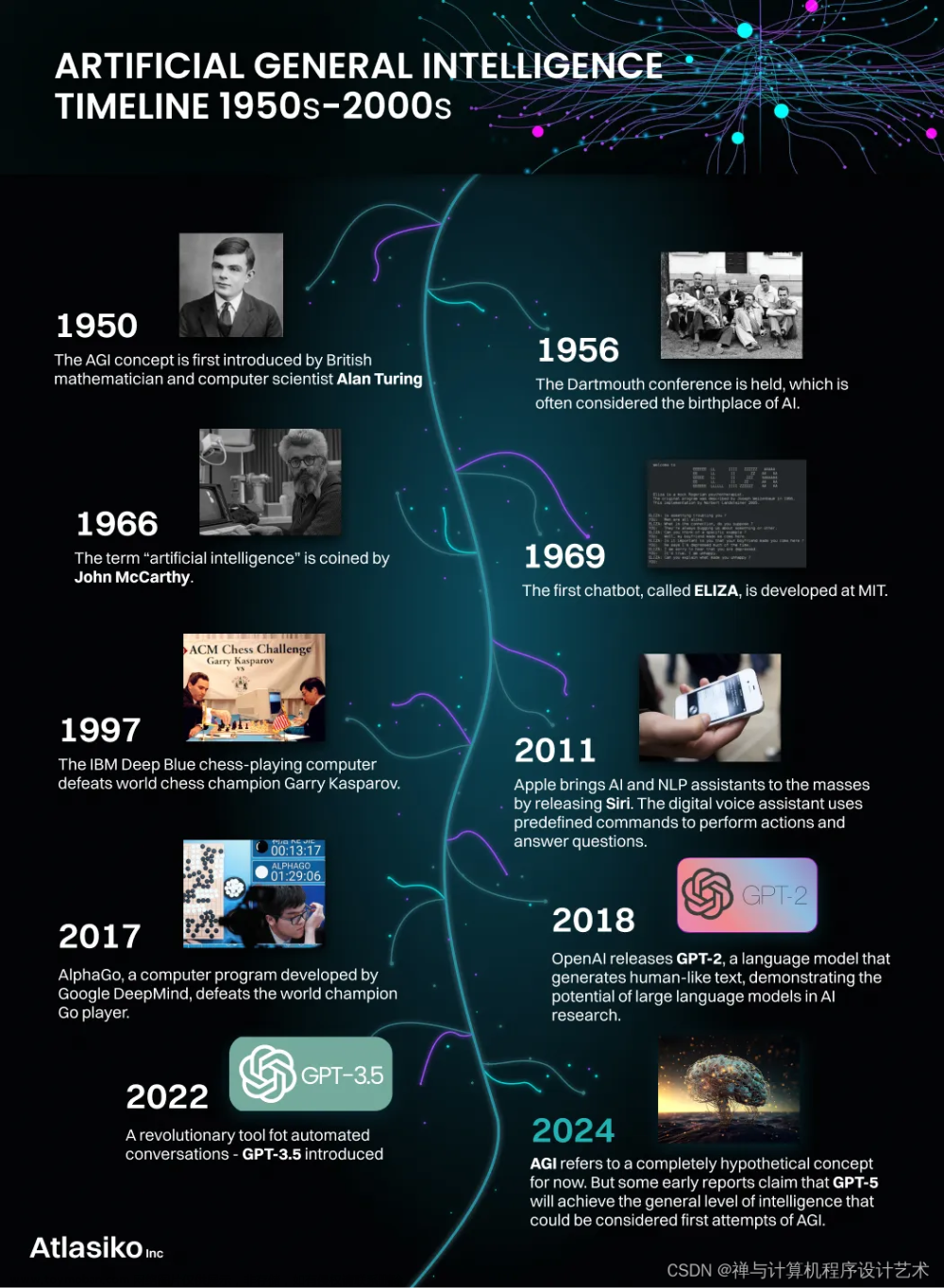
3.大语言模型的生成过程


4.自注意力机制的计算公式



附录:
RNN是循环神经网络(Recurrent Neural Networks)的简称,它是一种对序列数据进行建模的深度模型。RNN在处理序列数据时,引入了隐态(h),该隐态可以对序列数据提取特征,并经过一定的转换作为输出。RNN的神经网络结构在每时刻的输出都跟当前时刻的输入和上一时刻的输出有关。
RNN是一种神经网络模型,它可以处理序列数据,比如文字、语音、视频等。它的特点是每个时间步的输出不仅取决于当前的输入,还取决于之前的输出,这样就可以记住序列中的信息。RNN的基本结构包括输入层、隐藏层和输出层。隐藏层有一个循环连接,就像一个链条一样,每个环节都受到前面环节和当前输入的影响。
RNN之所以称为循环神经网络,是因为它可以在序列的演进方向进行递归(recursion),也就是说它可以反复使用自己的输出作为下一步的输入。这样就实现了一种时间上的记忆功能。
RNN有很多应用领域,比如自然语言处理(NLP)、机器翻译、语音识别、图像描述生成等。它们都需要处理序列数据,并且考虑序列中前后元素之间的关系。文章来源:https://www.toymoban.com/news/detail-732931.html
文章来源地址https://www.toymoban.com/news/detail-732931.html
到了这里,关于大语言模型如何生成内容的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!