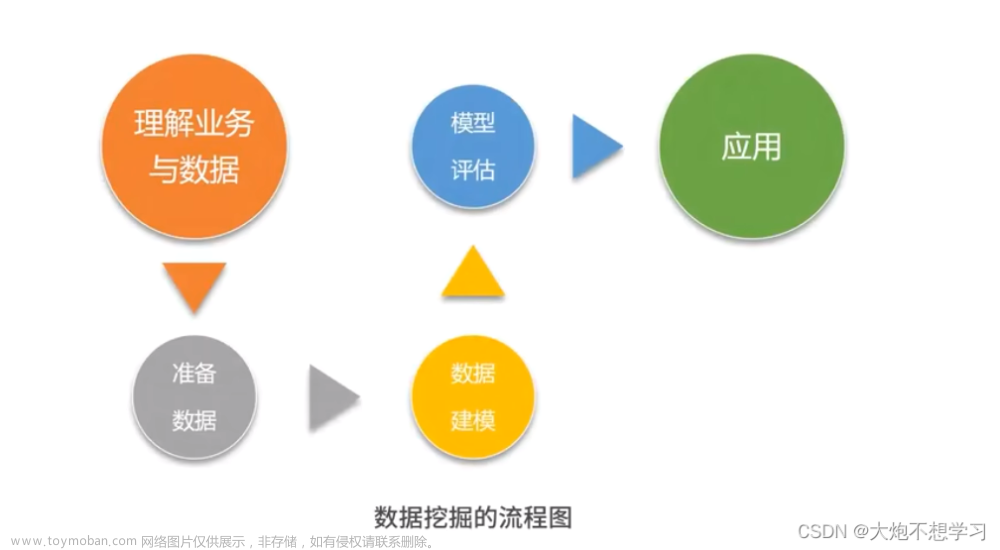
1. 数据探索
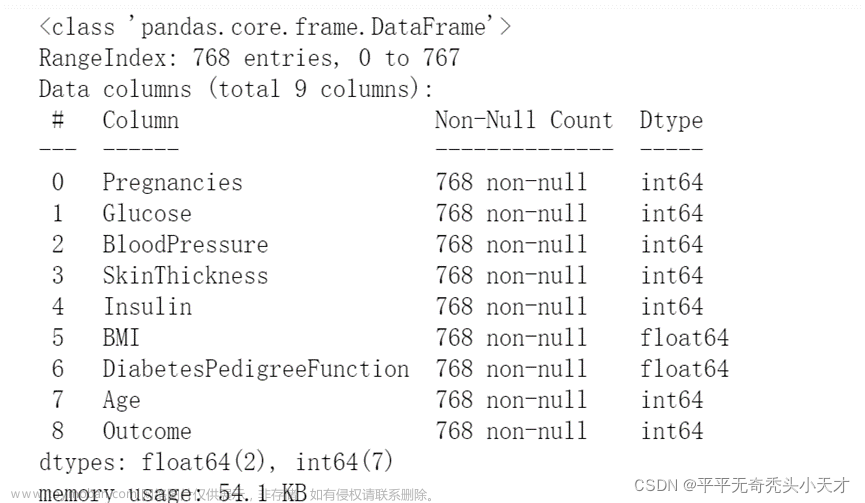
1.1 数据整体情况介绍
panda库中的to_datatime可以将时间戳转换成日常的时间格式
1.2 数据概况
查看数据量大小
查看前五行
查看每列属性含义
1.3 探索性数据分析(EDA)
1.3.1 缺失值可视化
利用 missingno 包
1.3.2 查看变量分布
在scipy模块中有 johnsonsu、norm、lognorm可以将数据分布绘出
2. 数据预处理
2.1 划分测试机何训练集
2.2 处理缺失值
2.3 数据清洗
处理“脏数据”,脏数据是指不符合现实逻辑且会对模型预测效果产生干扰的数据。文章来源:https://www.toymoban.com/news/detail-733086.html
3. 查看特征相关性
3.1 相关性计算
3.2 热力图展示
3.3 查看定类数据相关性
3.4 回归分析
4. 模型建立
4.1 Lasso 回归
4.2 特征重要性分析
绘制了交叉验证条形图文章来源地址https://www.toymoban.com/news/detail-733086.html
到了这里,关于数据挖掘一般框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!