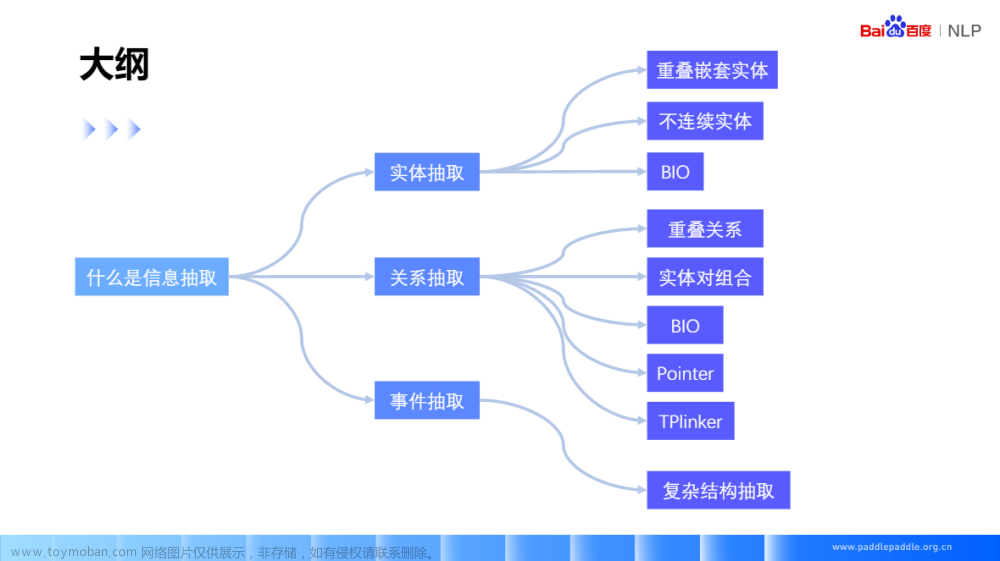
本文深入探讨了信息抽取的关键组成部分:命名实体识别、关系抽取和事件抽取,并提供了基于PyTorch的实现代码。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。文章来源地址https://www.toymoban.com/news/detail-733095.html

引言
背景和信息抽取的重要性
随着互联网和社交媒体的飞速发展,我们每天都会接触到大量的非结构化数据,如文本、图片和音频等。这些数据包含了丰富的信息,但也提出了一个重要问题:如何从这些海量数据中提取有用的信息和知识?这就是信息抽取(Information Extraction, IE) 的任务。
信息抽取不仅是自然语言处理(NLP)的一个核心组成部分,也是许多实际应用的关键技术。例如:
- 在医疗领域,信息抽取技术可以用于从临床文档中提取病人的重要信息,以便医生作出更准确的诊断。
- 在金融领域,通过抽取新闻或社交媒体中的关键信息,机器可以更准确地预测股票价格的走势。
- 在法律领域,信息抽取可以帮助律师从大量文档中找出关键证据,从而更有效地构建或驳斥案件。
文章的目标和结构
本文的目标是提供一个全面而深入的指南,介绍信息抽取以及其三个主要子任务:命名实体识别(NER)、关系抽取和事件抽取。
- 信息抽取概述 部分将为你提供这一领域的基础知识,包括其定义、应用场景和主要挑战。
- 命名实体识别(NER) 部分将详细解释如何识别和分类文本中的命名实体(如人名、地点和组织)。
- 关系抽取 部分将探讨如何识别文本中两个或多个命名实体之间的关系。
- 事件抽取 部分将解释如何从文本中识别特定的事件,以及这些事件与命名实体的关联。

每个部分都会包括相关的技术框架与方法,以及使用Python和PyTorch实现的实战代码。
我们希望这篇文章能成为这一领域的终极指南,不论你是一个AI新手还是有经验的研究者,都能从中获得有用的洞见和知识。
信息抽取概述

什么是信息抽取
信息抽取(Information Extraction, IE)是自然语言处理(NLP)中的一个关键任务,目标是从非结构化或半结构化数据(通常为文本)中识别和提取特定类型的信息。换句话说,信息抽取旨在将散在文本中的信息转化为结构化数据,如数据库、表格或特定格式的XML文件。
信息抽取的应用场景
信息抽取技术被广泛应用于多个领域,这里列举几个典型的应用场景:
- 搜索引擎:通过信息抽取,搜索引擎能更精准地理解网页内容,从而提供更相关的搜索结果。
- 情感分析:企业和品牌经常使用信息抽取来识别客户评价中的关键观点或情感。
- 知识图谱构建:通过信息抽取,我们可以从大量文本中识别实体和它们之间的关系,进而构建知识图谱。
- 舆情监控和危机管理:政府和非营利组织使用信息抽取来快速识别可能的社会或环境问题。
信息抽取的主要挑战
虽然信息抽取有着广泛的应用,但也面临几个主要的挑战:
- 多样性和模糊性:文本数据经常含有模糊或双关的表述,这给准确抽取信息带来挑战。
- 规模和复杂性:由于需要处理大量数据,计算资源和算法效率成为瓶颈。
- 实时性和动态性:许多应用场景(如舆情监控)要求实时抽取信息,这需要高度优化的算法和架构。
- 领域依赖性:不同的应用场景(如医疗、法律或金融)可能需要特定领域的先验知识。
以上内容旨在为你提供信息抽取领域的一个全面而深入的入口,接下来我们将逐一探讨其主要子任务:命名实体识别、关系抽取和事件抽取。
实体识别
什么是实体识别
实体识别(Entity Recognition)是自然语言处理中的一项基础任务,它的目标是从非结构化文本中识别出具有特定意义的实体项,如术语、产品、组织、人名、时间、数量等。
实体识别的应用场景
- 搜索引擎优化:改进搜索结果,使之更加相关。
- 知识图谱构建:从大量文本中提取信息,建立实体间的关联。
- 客户服务:自动识别客户查询中的关键实体,以便进行更精准的服务。
PyTorch实现代码
以下代码使用PyTorch构建了一个简单的实体识别模型:
import torch
import torch.nn as nn
import torch.optim as optim
# 简单的BiLSTM模型
class EntityRecognitionModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, tagset_size):
super(EntityRecognitionModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_dim * 2, tagset_size)
def forward(self, sentence):
embeds = self.embedding(sentence)
lstm_out, _ = self.lstm(embeds.view(len(sentence), 1, -1))
tag_space = self.hidden2tag(lstm_out.view(len(sentence), -1))
tag_scores = torch.log_softmax(tag_space, dim=1)
return tag_scores
# 参数
VOCAB_SIZE = 10000
EMBEDDING_DIM = 100
HIDDEN_DIM = 50
TAGSET_SIZE = 7 # 比如: 'O', 'TERM', 'PROD', 'ORG', 'PER', 'TIME', 'QUAN'
# 初始化模型、损失函数和优化器
model = EntityRecognitionModel(VOCAB_SIZE, EMBEDDING_DIM, HIDDEN_DIM, TAGSET_SIZE)
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 示例输入数据
sentence = torch.tensor([1, 2, 3, 4, 5], dtype=torch.long)
tags = torch.tensor([0, 1, 2, 2, 3], dtype=torch.long)
# 训练模型
for epoch in range(300):
model.zero_grad()
tag_scores = model(sentence)
loss = loss_function(tag_scores, tags)
loss.backward()
optimizer.step()
# 测试
with torch.no_grad():
test_sentence = torch.tensor([1, 2, 3], dtype=torch.long)
tag_scores = model(test_sentence)
predicted_tags = torch.argmax(tag_scores, dim=1)
print(predicted_tags) # 输出应为最可能的标签序列
输入、输出与处理过程
-
输入:一个由词汇表索引组成的句子(
sentence),以及每个词对应的实体标签(tags)。 - 输出:模型预测出的每个词可能对应的实体标签。
-
处理过程:
- 句子通过词嵌入层转换为嵌入向量。
- BiLSTM处理嵌入向量,并生成隐藏状态。
- 最后通过全连接层输出预测的标签概率。
该代码提供了一个完整但简单的实体识别模型。这不仅有助于新手快速入门,还为经验丰富的开发者提供了进一步的扩展可能性。
关系抽取
什么是关系抽取
关系抽取(Relation Extraction)是自然语言处理(NLP)中的一项重要任务,用于从非结构化文本中识别和分类实体之间的特定关系。
关系抽取的应用场景
- 知识图谱构建:识别实体之间的关系,用于知识图谱的自动填充。
- 信息检索:用于复杂的查询和数据分析。
- 文本摘要:自动生成文本的精炼信息。
PyTorch实现代码
以下是一个使用PyTorch构建的简单关系抽取模型:
import torch
import torch.nn as nn
import torch.optim as optim
# BiLSTM+Attention模型
class RelationExtractionModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, relation_size):
super(RelationExtractionModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, bidirectional=True)
self.attention = nn.Linear(hidden_dim * 2, 1)
self.relation_fc = nn.Linear(hidden_dim * 2, relation_size)
def forward(self, sentence):
embeds = self.embedding(sentence)
lstm_out, _ = self.lstm(embeds.view(len(sentence), 1, -1))
attention_weights = torch.tanh(self.attention(lstm_out))
attention_weights = torch.softmax(attention_weights, dim=0)
context = lstm_out * attention_weights
context = context.sum(dim=0)
relation_scores = self.relation_fc(context)
return torch.log_softmax(relation_scores, dim=1)
# 参数
VOCAB_SIZE = 10000
EMBEDDING_DIM = 100
HIDDEN_DIM = 50
RELATION_SIZE = 5 # 如 'is-a', 'part-of', 'same-as', 'has-a', 'none'
# 初始化模型、损失函数和优化器
model = RelationExtractionModel(VOCAB_SIZE, EMBEDDING_DIM, HIDDEN_DIM, RELATION_SIZE)
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 示例输入数据
sentence = torch.tensor([1, 2, 3, 4, 5], dtype=torch.long)
relation_label = torch.tensor([0], dtype=torch.long)
# 训练模型
for epoch in range(300):
model.zero_grad()
relation_scores = model(sentence)
loss = loss_function(relation_scores, relation_label)
loss.backward()
optimizer.step()
# 测试
with torch.no_grad():
test_sentence = torch.tensor([1, 2, 3], dtype=torch.long)
relation_scores = model(test_sentence)
predicted_relation = torch.argmax(relation_scores, dim=1)
print(predicted_relation) # 输出应为最可能的关系类型
输入、输出与处理过程
-
输入:一个由词汇表索引组成的句子(
sentence),以及句子中的实体对应的关系标签(relation_label)。 - 输出:模型预测的关系类型。
-
处理过程:
- 句子经过词嵌入层变为嵌入向量。
- BiLSTM处理嵌入向量,并生成隐藏状态。
- Attention机制用于聚焦相关词。
- 全连接层输出预测的关系类型。
该代码是一个基础但完整的关系抽取模型,可以作为此领域进一步研究的基础。
事件抽取
什么是事件抽取
事件抽取(Event Extraction)是自然语言处理(NLP)中用于从非结构化或半结构化文本中识别、分类和链接事件的过程。事件通常包括一个动词(事件触发词)和与该动词有关的一组实体或其他词(论元)。
事件抽取的应用场景
- 新闻聚合:自动识别新闻文章中的关键事件。
- 风险评估:在金融、医疗等领域中自动识别潜在风险事件。
- 社交媒体分析:从社交媒体数据中提取公众关注的事件。
PyTorch实现代码
下面是一个使用PyTorch实现的基础事件抽取模型:
import torch
import torch.nn as nn
import torch.optim as optim
# BiLSTM模型
class EventExtractionModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, event_size):
super(EventExtractionModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim, bidirectional=True)
self.event_fc = nn.Linear(hidden_dim * 2, event_size)
def forward(self, sentence):
embeds = self.embedding(sentence)
lstm_out, _ = self.lstm(embeds.view(len(sentence), 1, -1))
event_scores = self.event_fc(lstm_out.view(len(sentence), -1))
return torch.log_softmax(event_scores, dim=1)
# 参数
VOCAB_SIZE = 10000
EMBEDDING_DIM = 100
HIDDEN_DIM = 50
EVENT_SIZE = 5 # 如 'purchase', 'accident', 'meeting', 'attack', 'none'
# 初始化模型、损失函数和优化器
model = EventExtractionModel(VOCAB_SIZE, EMBEDDING_DIM, HIDDEN_DIM, EVENT_SIZE)
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 示例输入数据
sentence = torch.tensor([1, 2, 3, 4, 5], dtype=torch.long)
event_label = torch.tensor([0], dtype=torch.long)
# 训练模型
for epoch in range(300):
model.zero_grad()
event_scores = model(sentence)
loss = loss_function(event_scores, event_label)
loss.backward()
optimizer.step()
# 测试
with torch.no_grad():
test_sentence = torch.tensor([1, 2, 3], dtype=torch.long)
event_scores = model(test_sentence)
predicted_event = torch.argmax(event_scores, dim=1)
print(predicted_event) # 输出应为最可能的事件类型
输入、输出与处理过程
-
输入:一个由词汇表索引组成的句子(
sentence)以及句子中事件的标签(event_label)。 - 输出:模型预测出的事件类型。
-
处理过程:
- 句子通过词嵌入层转换为嵌入向量。
- BiLSTM用于处理嵌入向量,并生成隐藏状态。
- 通过全连接层输出预测的事件类型。
这个代码示例为读者提供了一个完整但基础的事件抽取模型,为进一步的研究和开发提供了基础。文章来源:https://www.toymoban.com/news/detail-733095.html
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
到了这里,关于NLP信息抽取全解析:从命名实体到事件的PyTorch实战指南的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!