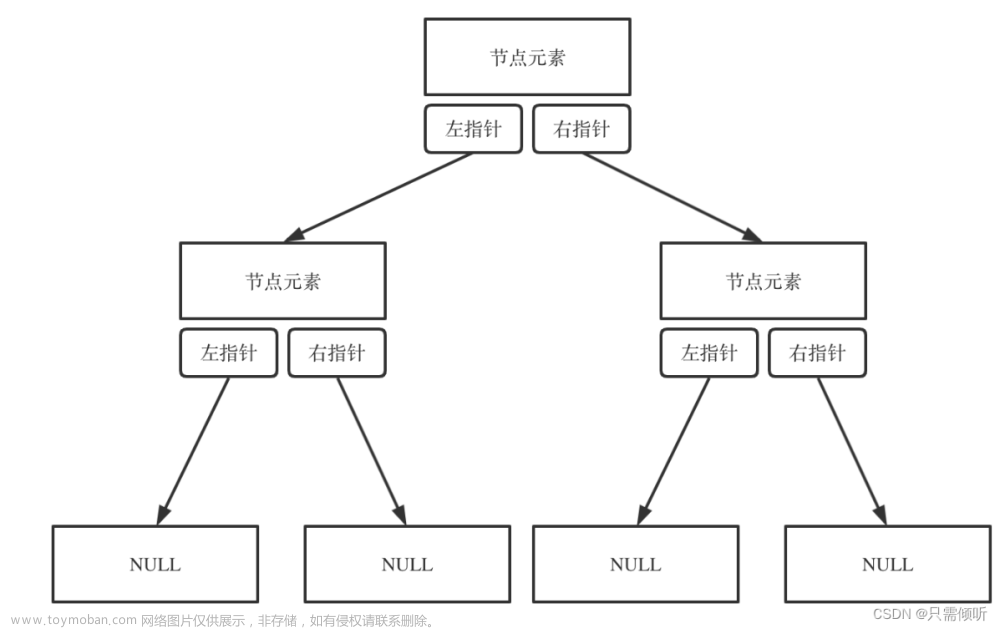
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【二叉树的遍历】,使用【二叉树】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为:目标公司+最近一年+出现频率排序,由高到低的去牛客TOP101去找,只有两个地方都出现过才做这道题(CodeTop本身汇聚了LeetCode的来源),确保刷的题都是高频要面试考的题。

就着这两个高频题目把二叉树的遍历类型题目刷一遍
名曲目标题后,附上题目链接,后期可以依据解题思路反复快速练习,题目按照题干的基本数据结构分类,且每个分类的第一篇必定是对基础数据结构的介绍。
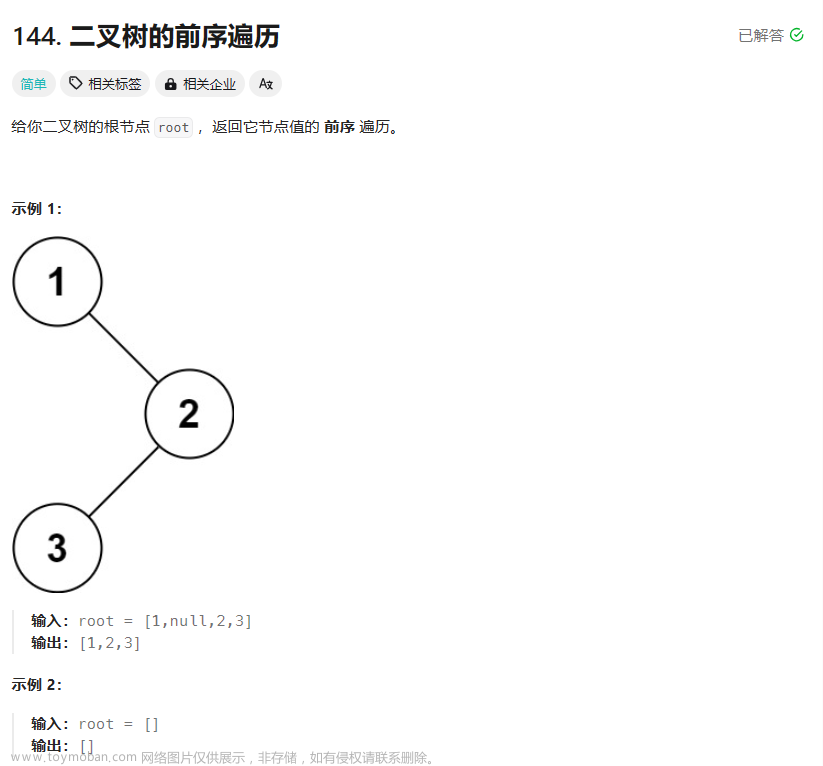
二叉树的前序遍历【EASY】
前序、中序、后序都有迭代和递归的实现方式
题干

解题思路
前序遍历简单来说就是“根左右”,展开来说就是对于一颗二叉树优先访问其根节点,然后访问它的左子树,等左子树全部访问完了再访问其右子树,而对于子树也按照之前的访问方式,直到到达叶子节点,每次访问一个节点之后,它的左子树是一个要前序遍历的子问题,它的右子树同样是一个要前序遍历的子问题。那我们可以用递归处理:
- 终止条件: 当子问题到达叶子节点后,后一个不管左右都是空,因此遇到空节点就返回。
- 返回值: 每次处理完子问题后,就是将子问题访问过的元素返回,依次存入了数组中。
- 本级任务: 每个子问题优先访问这棵子树的根节点,然后递归进入左子树和右子树。
具体做法:
step 1:准备数组用来记录遍历到的节点值,Java可以用List
step 2:从根节点开始进入递归,遇到空节点就返回,否则将该节点值加入数组。
step 3:依次进入左右子树进行递归。
代码实现
给出代码实现基本档案
基本数据结构:二叉树
辅助数据结构:无
算法:递归、DFS
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* public TreeNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return int整型一维数组
*/
public int[] preorderTraversal (TreeNode root) {
// 1 定义用来返回的数据
List<Integer> list = new ArrayList<>();
// 2 递归填充list的值
preorder(list, root);
// 3 返回结果处理
int[] result = new int[list.size()];
for (int i = 0; i < list.size(); i++) {
result[i] = list.get(i);
}
return result;
}
private void preorder(List<Integer> list, TreeNode root) {
// 1 递归终止条件
if (root == null) {
return;
}
// 2 按顺序递归填充左右子树
list.add(root.val);
preorder(list, root.left);
preorder(list, root.right);
}
}
复杂度分析
时间复杂度:遍历了N个节点,所以时间复杂度为O(N)
空间复杂度:最坏情况下,树退化为链表,递归栈深度为N,所以空间复杂度为O(N)
二叉树的中序遍历【EASY】
换位中序遍历
题干

解题思路
如果一棵二叉树,对于每个根节点都优先访问左子树,那结果是什么?从根节点开始不断往左,第一个被访问的肯定是最左边的节点。然后访问该节点的右子树,最后向上回到父问题。因为每次访问最左的元素不止对一整棵二叉树成立,而是对所有子问题都成立,因此循环的时候自然最开始都是遍历到最左,然后访问,然后再进入右子树,我们可以用栈来实现回归父问题
- 寻找最左子树,此过程逐层将树及左子树的根节点压入栈中,把要后处理的上层子树根节点先压入操作栈
- 栈顶即当前最左子树根节点,也是上层子树的左子节点,将值放入到list
- 节点指针移动到当前指针右节点,如果右节点为空,则本层处理完成,栈再弹出上层节点,接着循环处理
其实思路与递归就相似了,只不过将递归栈具象化了
代码实现
递归的思路和代码不再赘述,直接给出
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* public TreeNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return int整型一维数组
*/
public int[] inorderTraversal (TreeNode root) {
// 1 定义入参和返回值
List<Integer> list = new ArrayList<>();
// 2 中序递归获取list
inorder(list, root);
// 3 list结果转换
int[] result = new int[list.size()];
for (int i = 0; i < list.size(); i++) {
result[i] = list.get(i);
}
return result;
}
private void inorder(List<Integer> list, TreeNode root) {
// 1 终止条件
if (root == null) {
return;
}
inorder(list, root.left);
list.add(root.val);
inorder(list, root.right);
}
}
给出代码实现基本档案
基本数据结构:二叉树
辅助数据结构:栈、DFS
算法:迭代
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* public TreeNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return int整型一维数组
*/
public int[] inorderTraversal (TreeNode root) {
// 1 定义入参和辅助栈
List<Integer> list = new ArrayList<>();
Stack<TreeNode> stack = new Stack<TreeNode>();
if (root == null) {
return new int[0];
}
// 2 寻找最左子树
TreeNode tempRoot = root;
while (tempRoot != null || !stack.isEmpty()) {
// 2-1 寻找最左子树,此过程逐层将树及左子树的根节点压入栈中
while (tempRoot != null) {
// 把要后处理的上层子树根节点先压入操作栈
stack.push(tempRoot);
tempRoot = tempRoot.left;
}
// 2-2 栈顶即当前最左子树根节点,也是上层子树的左子节点
TreeNode node = stack.pop();
list.add(node.val);
// 2-3 节点指针移动到当前指针右节点,如果右节点为空,则本层处理完成,栈再弹出上层节点
tempRoot = node.right;
}
// 3 list结果转换
int[] result = new int[list.size()];
for (int i = 0; i < list.size(); i++) {
result[i] = list.get(i);
}
return result;
}
}
复杂度分析
时间复杂度:遍历了N个节点,所以时间复杂度为O(N)
空间复杂度:最坏情况下,树退化为链表,辅助递归栈深度为N,所以空间复杂度为O(N)
二叉树的后序遍历【EASY】
ok,再来看二叉树的后序遍历
题干

解题思路
左右根,同前序遍历及中序遍历的递归解法,不再赘述
代码实现
给出代码实现基本档案
基本数据结构:二叉树
辅助数据结构:无
算法:递归、DFS
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* public TreeNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return int整型一维数组
*/
public int[] postorderTraversal (TreeNode root) {
// 1 定义用来返回的数据
List<Integer> list = new ArrayList<>();
// 2 递归填充list的值
postorder(list, root);
// 3 返回结果处理
int[] result = new int[list.size()];
for (int i = 0; i < list.size(); i++) {
result[i] = list.get(i);
}
return result;
}
private void postorder(List<Integer> list, TreeNode root) {
if (root == null) {
return;
}
postorder(list, root.left);
postorder(list, root.right);
list.add(root.val);
}
}
复杂度分析
时间复杂度:遍历了N个节点,所以时间复杂度为O(N)
空间复杂度:最坏情况下,树退化为链表,递归栈深度为N,所以空间复杂度为O(N)
二叉树的层序遍历【MID】
二叉树的层序遍历
题干

解题思路
二叉树的层次遍历就是按照从上到下每行,然后每行中从左到右依次遍历,得到的二叉树的元素值。对于层次遍历,我们通常会使用队列来辅助:
因为队列是一种先进先出的数据结构,我们依照它的性质,如果从左到右访问完一行节点,并在访问的时候依次把它们的子节点加入队列,那么它们的子节点也是从左到右的次序,且排在本行节点的后面,因此队列中出现的顺序正好也是从左到右,正好符合层次遍历的特点
- step 1:首先判断二叉树是否为空,空树没有遍历结果。
- step 2:建立辅助队列,根节点首先进入队列。不管层次怎么访问,根节点一定是第一个,那它肯定排在队伍的最前面。
- step 3:每次进入一层,统计队列中元素的个数。因为每当访问完一层,下一层作为这一层的子节点,一定都加入队列,而再下一层还没有加入,因此此时队列中的元素个数就是这一层的元素个数。
- step 4:每次遍历一层的节点数,将其依次从队列中弹出,然后加入这一行的一维数组中,如果它们有子节点,依次加入队列排队等待访问。
- step 5:访问完这一层的元素后,将这个一维数组加入二维数组中,再访问下一层。

代码实现
给出代码实现基本档案
基本数据结构:二叉树
辅助数据结构:队列
算法:迭代、BFS
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* public TreeNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return int整型ArrayList<ArrayList<>>
*/
public ArrayList<ArrayList<Integer>> levelOrder (TreeNode root) {
// 1 定义要返回的数据结构
ArrayList<ArrayList<Integer>> result = new ArrayList<>();
// 2 定义辅助队列结构,每次队列都只存一层
Queue<TreeNode> queue = new LinkedList<TreeNode>();
// 3 首先将第一层也就是根节点放入队列
if (root == null) {
return new ArrayList<>();
}
queue.add(root);
// 4 核心处理逻辑,分层获取元素并加入列表
while (!queue.isEmpty()) {
ArrayList<Integer> levelList = new ArrayList<Integer>();
// 需要用一个临时变量承接队列大小,否则每次新加一层永远无法遍历完本层
int queueSize = queue.size();
for (int i = 0; i < queueSize; i++) {
// 4-1 获取队首元素,当前层元素,并添加到层列表中
TreeNode node = queue.poll();
levelList.add(node.val);
// 4-2 分别将节点左右元素添加到队列尾部
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
// 4-3 将本层元素集合添加到结果集中
result.add(levelList);
}
return result;
}
}
复杂度分析
时间复杂度:遍历了一遍树,时间复杂度为O(N)
空间复杂度:使用了辅助队列,空间复杂度为O(N)
二叉树的锯齿形层序遍历【MID】
难度升级,每层要反过来
题干

解题思路
解题思路与层次遍历相同,只不过需要隔行反转。只需增加标志位即可。
代码实现
给出代码实现基本档案
基本数据结构:二叉树
辅助数据结构:队列
算法:迭代、BFS
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* public TreeNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pRoot TreeNode类
* @return int整型ArrayList<ArrayList<>>
*/
public ArrayList<ArrayList<Integer>> Print (TreeNode pRoot) {
// 1 定义返回结果
ArrayList<ArrayList<Integer>> result = new ArrayList<>();
if (pRoot == null) {
return new ArrayList<>();
}
// 2 定义队列,并将根节点放入
Queue<TreeNode> queue = new LinkedList<>();
queue.add(pRoot);
// 3 设置反转标志位,隔行反转
boolean isReverse = false;
// 4 核心逻辑,将数据放入结果集
while (!queue.isEmpty()) {
int queueSize = queue.size();
ArrayList<Integer> levelList = new ArrayList<Integer>();
for (int i = 0; i < queueSize; i++ ) {
TreeNode node = queue.poll();
levelList.add(node.val);
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
// 依据标志位结果进行层级数据反转
if (isReverse) {
Collections.reverse(levelList);
}
// 重置标志位,以便下一层反转
isReverse = !isReverse;
result.add(levelList);
}
return result;
}
}
复杂度分析
时间复杂度:遍历了一遍树,时间复杂度为O(N)
空间复杂度:使用了辅助队列,空间复杂度为O(N)
二叉树的右视图【MID】
使用深度优先搜素方法
题干

解题思路
我们可以对二叉树进行层次遍历,那么对于每层来说,最右边的结点一定是最后被遍历到的。二叉树的层次遍历可以用广度优先搜索实现。
- 执行广度优先搜索,左结点排在右结点之前,这样,我们对每一层都从左到右访问。因此,只保留每个深度最后访问的结点,我们就可以在遍历完整棵树后得到每个深度最右的结点

所以只要按照层序遍历的思路,把每一层的最后一个节点放到结果集就行了。
代码实现
给出代码实现基本档案
基本数据结构:二叉树
辅助数据结构:队列
算法:迭代、BFS
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 求二叉树的右视图
* @param root 树的根节点
* @param inOrder int整型一维数组 中序遍历
* @return int整型一维数组
*/
public List<Integer> rightSideView(TreeNode root) {
// 1 定义返回的结果集
List<Integer> result = new ArrayList<Integer>();
if (root == null) {
return new ArrayList<Integer>();
}
// 2 定义队列,用来容纳每一层节点
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.add(root);
// 3 遍历每一层并获取最右边的节点
while (!queue.isEmpty()) {
int queueSize = queue.size();
for (int i = 0; i < queueSize; i++) {
TreeNode node = queue.poll();
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
// 如果节点是本层最后一个节点,则添加到结果集中
if (i == queueSize - 1) {
result.add(node.val);
}
}
}
return result;
}
}
复杂度分析
时间复杂度: O(N),每个节点都入队出队了 1 次。
空间复杂度: O(N),使用了额外的队列空间。
拓展知识:深度优先遍历和广度优先遍历
广度优先搜索(BFS)和深度优先搜索(DFS)是两种经典的图遍历算法,它们也可以用于二叉树的遍历和搜索。以下是它们的定义以及在二叉树中的应用场景:
广度优先搜索(BFS):
BFS是一种图遍历算法,它从一个起始节点开始,逐层地遍历与该节点相邻的节点,然后再遍历与这些相邻节点相邻的节点,以此类推。BFS通常使用队列数据结构来实现。
在二叉树中的应用场景:文章来源:https://www.toymoban.com/news/detail-733127.html
- 层级遍历:BFS可以用于按层级遍历二叉树,从根节点开始,逐层遍历,可以方便地实现层级顺序的操作。
- 查找最小深度:BFS可以用于查找二叉树的最小深度,即从根节点到最近叶子节点的最短路径。
- 查找特定元素:如果您需要在二叉树中查找特定元素,BFS可以用于在树中搜索,一旦找到目标元素,就可以停止搜索。
- 判断是否为完全二叉树:BFS可以用于判断二叉树是否是完全二叉树,通过观察层级遍历的结果,可以检查每一层是否都填满节点。
深度优先搜索(DFS):
DFS是一种图遍历算法,它从一个起始节点开始,沿着一条路径一直深入到无法继续前进的节点,然后返回上一层,继续探索其他路径。DFS通常使用递归函数或显式的栈数据结构来实现。
在二叉树中的应用场景:
- 前序遍历:DFS通常用于前序遍历二叉树,即先访问根节点,然后递归地访问左子树和右子树。前序遍历用于深度优先搜索问题。
- 中序遍历:DFS也可以用于中序遍历二叉树,即先递归地访问左子树,然后访问根节点,最后递归地访问右子树。中序遍历在二叉搜索树中用于获取有序元素。
- 后序遍历:DFS还可用于后序遍历二叉树,即先递归地访问左子树和右子树,最后访问根节点。后序遍历在某些问题中很有用,例如计算表达式的值或查找树的高度。
总的来说,BFS适用于需要层级遍历或查找最短路径的问题,而DFS适用于需要深度优先搜索或对树的结构进行更复杂操作的问题。在二叉树中,您可以根据具体问题的要求选择使用BFS或DFS。有时,问题可能需要同时使用这两种方法以解决不同的子问题。文章来源地址https://www.toymoban.com/news/detail-733127.html
到了这里,关于【算法训练-二叉树 一】【遍历二叉树】前序遍历、中序遍历、后续遍历、层序遍历、锯齿形层序遍历、二叉树右视图的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!