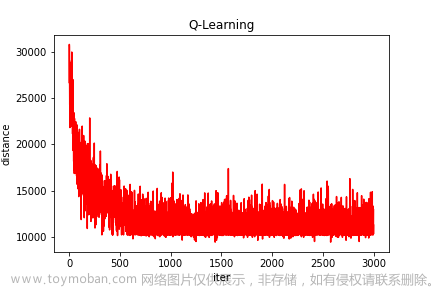
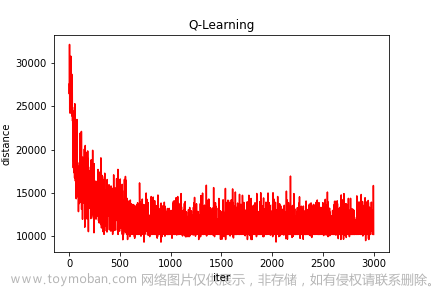
Q-learning 是一种强化学习算法,用于解决马尔可夫决策过程(MDP)问题。
什么是马尔可夫决策过程(MDP)问题?马尔可夫决策过程(MDP)是一种用于建模序贯决策问题的数学框架。在MDP中,决策问题被建模为一个基于马尔可夫链的数学模型。MDP由以下要素组成:
-
状态空间(State Space):一组可能的状态,用来描述系统的状态。例如,对于一个机器人导航问题,状态空间可以是所有可能的位置。
2. 行动空间(Action Space):一组可能的行动,代表决策者可以采取的行动。例如,机器人导航问题中的行动空间可以是向前、向后、向左、向右等。
-
转移概率(Transition Probability):描述在给定状态下,采取某个行动后转移到下一个状态的概率。例如,机器人在某个位置采取向前行动后,转移到相邻位置的概率。 -
奖励函数(Reward Function):定义在每个状态和行动上的即时奖励。奖励函数可以鼓励或惩罚决策者采取特定的行动。 -
折扣因子(Discount Factor):用于衡量未来奖励的重要性。折扣因子决定了决策者对即时奖励和未来奖励的权衡。
MDP问题的目标是找到一个最优的策略,该策略在给定的状态下选择最佳的行动,以最大化长期累积奖励。最优策略可以通过动态规划、值迭代、策略迭代等方法来求解。
在实际应用中,MDP可以用于许多决策问题,如机器人路径规划、资源分配、金融投资等。
那麽,我们通过python实现了一个基于Q-learning 算法的函数 q_learning。以下是代码示例:
def q_learning(zodiacs, target_length, num_episodes=1000, learning_rate=0.1, discount_factor=0.9):
q_table = np.zeros((target_length + 1,
len(zodiacs))) # 创建一个 Q 表格,大小为 `(target_length + 1) × len(zodiacs)`,
# 初始化所有值为 0。Q 表格用于存储状态和动作的 Q 值。
for episode in range(num_episodes): # 根据指定的训练轮数 `num_episodes`,开始进行 Q-learning 算法的训练。
state = np.random.randint(1,
target_length) # 随机选择初始状态
# 在每个训练轮次开始时,随机选择一个初始状态 `state`,该状态的取值范围在 1 到 `target_length` 之间。
done = False # 设置一个标志变量 `done`,表示当前训练轮次是否结束。
while not done: # 在当前训练轮次内,进行 Q-learning 算法的迭代更新。
action = np.argmax(q_table[state]) # 根据 Q 表选择动作,根据当前状态 `state` 在 Q 表格中选择具有最高 Q 值的动作 `action`。
next_state = state + 1 # 进入下一个状态
if next_state == target_length: # 判断是否达到目标状态。
# - 如果达到目标状态,设置奖励 `reward` 为 1,并将标志变量 `done` 设置为 True,表示当前训练轮次结束。
# - 如果未达到目标状态,设置奖励 `reward` 为 0。
reward = 1
done = True
else:
reward = 0
q_table[state, action] += learning_rate * (reward + discount_factor * np.max(q_table[next_state]) - q_table[
state, action]) # 使用 Q-learning 更新 Q 表格中的 Q 值。
# - `learning_rate` 是学习率参数,控制每次更新时新 Q 值的权重。
# - `discount_factor` 是折扣因子参数,控制未来奖励的衰减程度。
# - `np.max(q_table[next_state])` 表示在下一个状态 `next_state` 中选择具有最高 Q 值的动作的 Q 值。
state = next_state # 将当前状态更新为下一个状态,进行下一轮迭代。
return q_table
这段代码实现了一个基于 Q-learning 算法的函数 q_learning。Q-learning 是一种强化学习算法,用于解决马尔可夫决策过程(MDP)问题。
以下是对代码的详细解析:
-
q_table = np.zeros((target_length + 1, len(zodiacs))):创建一个 Q 表格,大小为(target_length + 1) × len(zodiacs),初始化所有值为 0。Q 表格用于存储状态和动作的 Q 值。 -
for episode in range(num_episodes)::根据指定的训练轮数num_episodes,开始进行 Q-learning 算法的训练。 -
state = np.random.randint(1, target_length): 在每个训练轮次开始时,随机选择一个初始状态state,该状态的取值范围在 1 到target_length之间。 -
done = False:设置一个标志变量done,表示当前训练轮次是否结束。 -
while not done::在当前训练轮次内,进行 Q-learning 算法的迭代更新。 -
action = np.argmax(q_table[state]):根据当前状态state在 Q 表格中选择具有最高 Q 值的动作action。 -
next_state = state + 1:执行动作后,进入下一个状态next_state,即当前状态加 1。 -
if next_state == target_length::判断是否达到目标状态。- 如果达到目标状态,设置奖励
reward为 1,并将标志变量done设置为 True,表示当前训练轮次结束。 - 如果未达到目标状态,设置奖励
reward为 0。
- 如果达到目标状态,设置奖励
-
q_table[state, action] += learning_rate * (reward + discount_factor * np.max(q_table[next_state]) - q_table[state, action]):使用 Q-learning 更新 Q 表格中的 Q 值。-
learning_rate是学习率参数,控制每次更新时新 Q 值的权重。 -
discount_factor是折扣因子参数,控制未来奖励的衰减程度。 -
np.max(q_table[next_state])表示在下一个状态next_state中选择具有最高 Q 值的动作的 Q 值。
-
-
state = next_state:将当前状态更新为下一个状态,进行下一轮迭代。 -
训练结束后,返回最终的 Q 表格
q_table。文章来源:https://www.toymoban.com/news/detail-733164.html
总结起来,这段代码通过随机选择初始状态和迭代更新 Q 表格,来学习和优化动作选择策略,以达到最大化累积奖励的目标。希望这个解析能够帮助你理解这段代码的作用和实现方式。文章来源地址https://www.toymoban.com/news/detail-733164.html
到了这里,关于Python Q-learning 算法 --2023博客之星候选--城市赛道的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![强化学习基础篇[2]:SARSA、Q-learning算法简介、应用举例、优缺点分析](https://imgs.yssmx.com/Uploads/2024/02/468458-1.jpeg)