HTTP 协议工作于客户端-服务端架构上。浏览器作为 HTTP 客户端通过 URL 向 HTTP 服务端即 WEB 服务器发送所有请求。
- WEB 服务器有:Apache服务器,IIS服务器(Internet Information Services)等。
- URL:即统一资源定位符(Uniform Resource Locator),用来唯一地标识万维网中的某一个文档。URL由协议、主机和端口(默认为80)以及文件名三部分构成。如:

HTTP 默认端口号为80,但是你也可以改为8080或者其他端口。
HTTP 协议是属于应用层协议,并建立在 TCP/IP 的基础之上的超文本传输协议。当用户访问 WEB 服务器上的一个网页时,首先向 WEB 服务器提出连接请求,WEB 服务器接受并解析 HTTP 请求,然后从服务器的文件系统获取所请求的文件,将响应消息发送给客户端,客户端浏览器将收到的文件内容显示出来。如果请求的文件不存在于服务器中,则服务器应该向客户端发送“ 404 Not Found ”差错报文。
本实验通过对具体的请求响应过程中协议内容的分析来理解和掌握 HTTP 协议的通信过程。
1 HTTP 协议
1.1 HTTP 基本请求与应答
HTTP 请求包括三部分,分别是请求行(请求方法)、请求头(消息报头)和请求正文。HTTP 请求第三行为请求正文,请求正文是可选的,它最常出现在 post 请求方式中,get 请求无正文,所以回车之后为空。示例如下:

请求行
由三部分构成:第一部分说明请求类型为 get 方法请求,第二部分(用/分开)是资源 URL,第三部分说明使用的是 HTTP1.1 版本。
GET /success.txt HTTP/1.1\r\n
常见的请求方法如下图所示:

其中用得最多的方法是 get 方法和 post 方法,二者的区别:
- get 直接在浏览器输入,post 需要工具发送请求;
- get 用 url 或者 cookie 传参,post 将数据放在 body 中;
- get 的 URL 有长度限制,post 数据可以非常大;
- post 比 get 安全,因为 URL 看不到数据;
- get 用来获取数据,post 用来发送数据。
请求头
请求头(消息头)包含(客户机请求的服务器主机名,客户机的环境信息等)。具体内容及含义如下:
- Accept:用于告诉服务器,客户机支持的数据类型 (例如:Accept:text/html,image/*);
- Accept-Charset:用于告诉服务器,客户机采用的编码格式;
- Accept-Encoding:用于告诉服务器,客户机支持的数据压缩格式;
- Accept-Language:客户机语言环境;
- Host:客户机通过这个头,告诉服务器想访问的主机名;
- If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间;
- Referer:客户机通过这个头告诉服务器,它(客户端)是从哪个资源来访问服务器的(防盗链);
- User-Agent:客户机通过这个头告诉服务器,客户机的软件环境(操作系统,浏览器版本等);
- Cookie:客户机通过这个头,将 Coockie 信息带给服务器;
- Connection:告诉服务器,请求完成后,是否保持连接;
- Date:告诉服务器,当前请求的时间。
请求正文
浏览器端通过 HTTP 协议发送给服务器的实体数据。get 请求时,通过 url 传给服务器的值 name=dylan&id=110。post 请求时,通过表单发送给服务器的值。也可以为空。
HTTP响应
一个 HTTP 响应代表服务器端向客户端回送的数据,它包括:一个状态行,若干个消息头,以及实体内容。示例如下:

响应行
包括 HTTP 版本HTTP/1.1,状态码200,以及消息OK;其中 HTTP 响应常见的状态码及其含义如下:

响应头
响应头有若干个字段组合(根据具体情况选择),常见字段及其含义如下:
- Content-Type:服务器给客户端传回来的文件格式;
- Content-Length:这个是返回的实体在压缩之之后的长度为 8 byte;
- Last-Modified:文档的最后改动时间;
- ETag:这个响应头中有种Weak Tag,值为W/“xxxxx”。它声明Tag是弱匹配的,只能做模糊匹配,在差异达到一定阈值时才起作用;
- Accept-Ranges:表示该服务器是否支持文件的范文请求;
- Server:设置服务器名称;
- Date:当前 GMT 时间,这个就是你请求的东西被服务器创建的时间。
响应正文
响应包含浏览器能够解析的静态内容,例如:HTML,纯文本,图片等等信息。
1.2 HTTP 协议缓存的响应分析
浏览器缓存访问过程及机制
WEB 缓存一般分为浏览器缓存、代理服务器缓存以及网关缓存。WEB 缓存就在服务器-客户端之间搞监控,监控请求,并且把请求输出的内容(例如 HTML 页面、图片和文件)另存一份(统称为副本);然后,如果下一个请求是相同的 URL,则直接请求保存的副本,而不是再次访问资源服务器。
使用缓存的 2 个主要优势
- 降低延迟:缓存离客户端更近,因此,从缓存请求内容比从源服务器所用时间更少,呈现速度更快,网站就显得更灵敏;
- 降低网络传输:副本被重复使用,大大降低了用户的带宽使用,其实也是一种变相的省钱(如果流量要付费的话),同时保证了带宽请求在一个低水平上,更容易维护了。
HTTP 协议缓存是 WEB 缓存的一种,它是通过 HTTP 头信息来控制缓存的,HTTP 头信息可以让你对浏览器和代理服务器如何处理你的副本进行更多的控制。他们在 HTML 代码中是看不见的,一般由 Web 服务器自动生成。但是,根据你使用的服务器,你可以在某种程度上进行控制。
浏览器第一次请求流程如下图所示:

浏览器在第一次请求的时候不存在缓存,直接从浏览器请求,等请求返回结果之后再根据 HTTP 头信息将数据缓存在内存或者硬盘中。
浏览器再次请求同一 URL 时的流程如下图所示:

浏览器需要根据 HTTP 头信息来判断是否直接从缓存读取数据,还是交由服务器来判断是否从缓存读取数据。几种状态码的区别如下图所示:

HTTP报文中与缓存有关的字段
HTTP 状态码(status code)
- 200 请求成功,浏览器会把响应回来的信息显示在浏览器端;
- 304 第一次访问一个资源后,浏览器会将该资源缓存到本地;第二次再访问该资源时,如果该资源没有发生改变或失效,那么服务器响应给浏览器 304 状态码,告诉浏览器使用本地缓存的资源。
HTTP 响应时,如何判断是该返回 200 还是 304 呢?与之相关的字段是:
- Last-Modified: 表示这个响应资源的最后修改时间。web 服务器在响应请求时,告诉浏览器资源的最后修改时间。
- If-Modified-Since: 当资源过期时(使用 Cache-Control 标识的 max-age),发现资源具有 Last-Modified 声明,则再次向 WEB 服务器请求时,带上 If-Modified-Since,表示请求时间。WEB 服务器收到请求后发现有 If-Modified-Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源有被改动过,则响应资源内容(写在响应消息包体内),HTTP 200 ;若最后修改时间较旧,说明资源无新修改,则响应 HTTP 304 (无需包体,节省流量),告知浏览器继续使用缓存。
HTTP 协议缓存捕获操作方法与步骤
- 启动浏览器,确保浏览器的缓存被清除。在 Firefox 下执行此操作,请选择“工具” - > “清除最近历史记录”,然后检查缓存框;
- 启动 Wireshark 数据包嗅探,在浏览器中输入某一 URL ,浏览器应显示一个 HTML 文件;
- 再次快速地将相同的 URL 输入到浏览器中(或者只需在浏览器中点击刷新按钮);
- 停止 Wireshark 数据包捕获,并在 display-filter-specification 窗口中输入“http”,以便只捕获 HTTP 消息,并在数据包列表窗口中显示。
1.3 HTTP 协议对长文件的处理
TCP报文段
在以太网中,最大传输单元(MTU)为 1500 个字节,在一个 IP 包中,去除 IP 包头的 20 个字节,可以传输的最大数据长度为 1480 个字节。在 TCP 包中,去除 20 个 TCP 包头,可以传输的最大数据段为 1460 个字节。因此,当数据超过最大数据长度时,将对该数据进行分片处理,在 IP 包头中会看到有多个片在传输,但标识号是相同的,表示是同一个数据包。
HTML 文件相当长时,例如: 4861 字节太大,一个 TCP 数据包不能容纳。因此,单个 HTTP 响应消息由 TCP 分成几个部分,每个部分包含在单独的 TCP 报文段中,如下图:长度为 4861 的报文被分为长度分别为 1440,1440,1440,541 的 4 个 TCP 段,编号分别为 8715,8716,8718,8719 。

数据包
分为请求数据包和响应数据包:展开 HTTP 分组,查找浏览器发送的请求消息,所以此时我们捕捉到的只有 1 个请求消息。

请求数据包
单击 get 数据包,其内容包含:请求行,请求头,空行,请求体。

响应数据包
点开响应数据包,其状态码和短语都在此数据包里。并且其状态码为 200 ,短语为 OK :

响应内容包括:状态行,响应头,空行,响应正文:

1.4 对嵌入对象网页处理
网页嵌入对象
在制作网页时,除了可以在网页中放置文本外,还可以在页面中嵌入图片、声音、视频、动画等多媒体内容,使得页面看上去更加丰富多彩、动感十足。
在网页中嵌入对象,实际上并不会在网页中插入对象,而是通过某种标签链接到指定的对象,标签创建的只是被引用对象的占位符而已。
嵌入图像:
<img src="url" alt="some_text">
浏览器将图像显示在文档中图像标签出现的地方。URL 指存储图像的位置。URL 可以使用完整的位置,如:
<img src="http://data.educoder.net/images/flower.jpg" alt="flower">
也可以使用相对位置如:
<img src="flower.jpg" alt="flower">
表示图片文件flower.jpg位于当前页面所处的服务器位置上面。
嵌入声音:
在早期的 HTML 标准中,嵌入声音:
<embed src="your.mid" autostart=true loop=2>
在 HTML5 标准中,还可以嵌入音频和视频对象。如:
<audio controls>
<source src="horse.ogg" type="audio/ogg">
<source src="horse.mp3" type="audio/mpeg">
您的浏览器不支持 audio 元素。
</audio>
嵌入 flash 对象:
<object classid="clsid:d27cdb6e-ae6d-11cf-96b8-444553540000" codebase="http://download.macromedia.com/pub/shockwave/cabs/flash/swflash.cab#version=7,0,19,0" width="500" height="300" id="忍耐中爆发" >
<param name="movie" value="忍耐中爆发.swf">
<param name="FlashVars" value="prizeResult=3">
<param name="quality" value="high">
<param name="menu" value="false">
<param name="wmode" value="transparent">
<param name="allowScriptAccess" value="always" />
<embed src="images/忍耐中爆发.swf" FlashVars="prizeResult=3" allowScriptAccess="always" wmode="transparent" menu="false" quality="high" width="500" height="300" type="application/x-shockwave-flash" pluginspage="http://get.adobe.com/cn/flashplayer/" name="忍耐中爆发"/>
</object>
嵌入对象的连接方式
在客户端请求有嵌入对象的网页时,除开要对请求的页面文件进行响应之外,还需要对网页中嵌入的每个对象进行发起请求。对嵌入对象的请求可以采用串行方式或并行方式。
串行方式
假设一个包含了 3 个嵌入图片的 WEB 页面,浏览器需要发起 4 个 HTTP GET 请求来显示此页面:1 个用于顶层的 HTML 页面,3 个用于嵌入的图片。浏览器可以先完整地请求原始的 HTML 页面,然后请求第一个嵌入对象,然后请求第二个嵌入对象等,以这种简单的方式对每个嵌入对象串行处理。如图所示:

并行方式
串行方式的处理效率非常低。HTTP 允许客户端打开多条连接,并行地执行多个 HTTP GET 请求,并行加载了 4 幅嵌入式图片,每个事务都有自己的 TCP 连接。如图所示:

并行连接的时间线,比单条连接快很多。首先要装载的是封闭的 HTML 页面,然后并行处理其他的 3 个事务,每个事务都有自己的连接。图片中的装载是并行的,连接的时延也是重叠的。
从理论上说,并行连接的速度可能会更快。但实际上不一定总是更快的。客户端的网络带宽不足时,大部分的时间可能都是用来传送数据的。在这种情况下,一个连接到速度较快服务器上的 HTTP 事务就会很容易地耗尽所有可用的 Modem 带宽。如果并行加载,每个对象可能会去竞争有限的带宽,每个对象都会以较慢的速度按比例加载,这样带来的性能提升就很小,甚至没有提升。
另外,打开大量连接会消耗很多内存资源,从而引发自身的性能问题。复杂的 WEB 页面可能会有数十或数百个内嵌对象。客户端可能可以打开数百个连接,但服务器通常要同时处理很多其他用户的请求,所以很少有 WEB 服务器希望出现这样的情况。这会造成服务器性能的严重下降,对高负荷的代理来说也同样如此。
实际上,浏览器使用并行连接时,会将并行连接的总数限制在一个较小的值。服务器可以随意关闭来自特定客户端的超量连接。
持久连接
WEB 客户端经常会打开到同一个站点的连接。一个 WEB 页面上的大部分内嵌图片通常都来自同一个 WEB 站点,而且相当一部分指向对象的超链接通常都指向同一个站点。因此,初始化了对某服务器 HTTP 请求的应用程序很可能会在不久的将来对那台服务器发起更多的请求,这种性质被称为站点本地服务(site locality)。
HTTP/1.1 允许 HTTP 设备在事务处理结束之后将 TCP 连接保持在打开状态,以便为未来的 HTTP 请求重用现存的连接。在事务处理结束之后,仍然保持在打开状态的 TCP 连接被称为持久连接。非持久连接会在每个事务结束之后关闭。持久连接会在不同事务之间保持打开状态,直到客户端或服务器决定将其关闭为止。
重用已对目标服务器打开的空闲持久连接,就可以避开缓慢的链接建立阶段。而且已经打开的链接还可以避免慢启动的拥塞适应阶段,以便更快速地进行数据传输。
keep-alive 与 persistent 连接
持久连接与并行连接配合使用可能是最高效的方式。现在,很多 WEB 应用程序都会打开少量的并行连接,其中的每一个都是持久连接。持久连接有两种类型:比较老的 HTTP/1.0+“keep-alive” 连接,以及现代的 HTTP/1.1“persistent” 连接。
KEEP-alive

上图对串行连接实现 4 个 HTTP 事务的时间与在一条持久连接上实现同样事务所需的时间线进行了比较,由于去除了进行连接和关闭连接的开销,所以时间线有所缩减。
很多 HTTP/1.0 浏览器和服务器支持 keep-alive 连接。但由于受到一些互操作性设计的困扰, HTTP/1.1 逐渐停止了对 keep-alive 连接的支持,用持久连接(persistent connection)的改进型设计取代了它。持久连接的目的与 keep-alive 了解的目的相同,但工作机制更优。
与 HTTP/1.0 的 keep-alive 连接不同,HTTP/1.1 持久连接在默认情况下是激活的。除非特别指明,否则 HTTP/1.1 假定所有连接都是持久的。要在事务处理结束之后将连接关闭,HTTP/1.1 应用程序必须向报文中显示地添加一个 Connection:close 首部。
HTTP/1.1 客户端假定在收到响应后,除非响应中包含了 Connection:close 首部,不然 HTTP/1.1 连接就仍维持在打开状态。但是,客户端和服务器仍然可以随时关闭空闲的连接。不发送 Connection:close ,并不意味着服务器承诺永远将连接保持在打开状态。
1.5 HTTP 认证
HTTP认证方式
HTTP 中有如下常用认证方式:
- Basic 认证;
- Digest 认证;
- SSL Client 认证;
- 表单认证。
HTTP 基本认证
当一个客户端向 HTTP 服务器进行数据请求时,如果客户端未被认证,则 HTTP 服务器将通过基本认证过程对客户端的用户名及密码进行验证,以决定用户是否合法。
客户端在接收到 HTTP 服务器的身份认证要求后,会提示用户输入用户名及密码,然后将用户名及密码以BASE64加密,加密后的密文将附加于请求信息中。 如当用户名为anjuta,密码为:123456时,客户端将用户名和密码用“:”合并,并将合并后的字符串用 BASE64 加密为密文,并于每次请求数据时,将密文附加于请求头(Request Header)中。HTTP 服务器在每次收到请求包后,根据协议取得客户端附加的用户信息(BASE64 加密的用户名和密码),解开请求包,对用户名及密码进行验证,如果用户名及密码正确,则根据客户端请求,返回客户端所需要的数据;否则,返回错误代码或重新要求客户端提供用户名及密码。
BASIC 认证的步骤:
- 客户端访问一个受 HTTP 基本认证保护的资源;
- 服务器返回 401 状态,要求客户端提供用户名和密码进行认证。(验证失败的时候,响应头会加上 WWW-Authenticate: Basic realm=“请求域” ),如下所示:
401 Unauthorized
WWW-Authenticate: Basic realm="WallyWorld"
- 客户端将输入的用户名密码用Base64进行编码后,采用非加密的明文方式传送给服务器;
Authorization: Basic xxxxxxxxxx.
- 服务器将 Authorization 头中的用户名密码解码并取出,进行验证,如果认证成功,则返回相应的资源;如果认证失败,则仍返回 401 状态,要求重新进行认证。
HTTP 摘要认证 digest authentication
该认证是 HTTP1.1 提出的基本认证的替代方法,不包含密码的明文传递。摘要认证使用随机数 + MD5 加密哈希函数来对用户名、密码进行加密,在上述第二步时,服务器返回随机字符串 nonnce 之后,客户端发送摘要MD5(HA1:nonce:HA2)。其中HA1=MD5(username:realm:password),HA2=MD5(method:digestURI)。
HTTP 开放认证 OAuth Authentication
开放认证允许用户提供一个令牌,而不是用户名和密码来访问它们存放在特定服务器的数据,每一个令牌授权一个特定的第三方系统。
HTTP(令牌认证) Token Authentication
令牌认证是指当用户第一次登陆时,服务器生成一个 token 并返回给客户端,之后的每次访问客户端都会带上该 token,无需再次带上用户名和密码。
2 实验分析
2.1 基本的HTTP GET/response交互
我们开始探索HTTP,方法是下载一个非常简单的HTML文件,非常短,并且不包含嵌入的对象。执行以下操作:
- 启动您的浏览器。
- 启动Wireshark数据包嗅探器,如Wireshark实验-入门所述(还没开始数据包捕获)。在display-filter-specification窗口中输入“http”(只是字母,不含引号标记),这样就在稍后的分组列表窗口中只捕获HTTP消息。(我们只对HTTP协议感兴趣,不想看到其他所有的混乱的数据包)。
- 稍等一会儿(我们将会明白为什么不久),然后开始Wireshark数据包捕获。
- 在浏览器中输入以下内容 http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file1.html 您的浏览器应显示非常简单的单行HTML文件。
- 停止Wireshark数据包捕获。
你的Wireshark窗口应该类似于图1所示的窗口。如果你无法连接网络并运行Wireshark,您可以根据后面的步骤下载已捕获的数据包:
下载zip文件 http://gaia.cs.umass.edu/wireshark-labs/wireshark-traces.zip
解压缩文件 http-ethereal-trace-1。这个zip文件中的数据是由本书作者之一使用Wireshark在作者电脑上收集的,并且是按照Wireshark实验中的步骤做的。 如果你下载了数据文件,你可以将其加载到Wireshark中,并使用文件菜单选择打开并查看数据,然后选择http-ethereal-trace-1文件。 结果显示应与图1类似。(在不同的操作系统上,或不同的Wireshark版本上,Wireshark的界面会不同)。

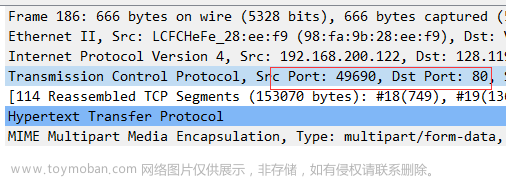
- 您的浏览器是否运行HTTP 版本1.0 或1.1?服务器运行的是什么版本的
HTTP?
答:服务器运行HTTP1.1,我浏览器运行HTTP1.1。


- 您的浏览器指示哪些语言(如果有)可以接受服务器?
ANS:我浏览器仅能接收 en-us, en; q=0.5

- 您的计算机的IP地址是什么? gaia.cs.umass.edu服务器地址呢?
答:我的IP:192.168.1.102;gaia.cs.umass.edu的IP:128.119.245.12

- 服务器返回到浏览器的状态代码是什么?
答:服务器返回200 OK 代码

- 服务器上HTML文件的最近一次修改是什么时候?

- 服务器返回多少字节的内容到您的浏览器?
答:返回了 73Byte 的内容

- 通过检查数据包内容窗口中的原始数据,你是否看到有协议头在数据包列表窗口中未显示? 如果是,请举一个例子。
答:没有。仅有这四条HTTP请求。

2.2 HTTP的条件 get/response交互
大多数Web浏览器使用对象缓存,从而在检索HTTP对象时执行条件GET。执行以下步骤之前,请确保浏览器的缓存为空。(要在Firefox下执行此操作,请选择“工具” - > “清除最近历史记录”,然后检查缓存框,对于Internet Explorer,选择“工具” - >“Internet选项” - >“删除文件”;这些操作将从浏览器缓存中删除缓存文件。 现在按下列步骤操作:
- 启动您的浏览器,并确保您的浏览器的缓存被清除,如上所述。
- 启动Wireshark数据包嗅探器。
- 在浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file2.html 您的浏览器应显示一个非常简单的五行HTML文件。
- 再次快速地将相同的URL输入到浏览器中(或者只需在浏览器中点击刷新按钮)。
- 停止Wireshark数据包捕获,并在display-filter-specification窗口中输入“http”,以便只捕获HTTP消息,并在数据包列表窗口中显示。
- (注意:如果无法连接网络并运行Wireshark,则可以使用http-ethereal-trace-2数据包跟踪来回答以下问题。)
- 检查第一个从您浏览器到服务器的HTTP GET请求的内容。您在HTTP GET中看到了“IF-MODIFIED-SINCE”行吗?
答:没看到

- 检查服务器响应的内容。服务器是否显式返回文件的内容? 你是怎么知道的?
答:是,查看Line-based text data: text/htm1 10 lines

- 现在,检查第二个HTTP GET请求的内容。 您在HTTP GET中看到了
“IF-MODIFIED-SINCE:”吗? 如果是,“IF-MODIFIED-SINCE:”头后面包含哪些信息?
答:看到了,发现后面的值刚好是上次得到的服务器最后修改这个文件的时间。

IF-MODIFIED-SINCE: 意思是我们在请求时会发送给服务器上次它修改这个文件最后一次时间,如果服务器发现仍然没有修改这个文件,就会返回 304 文件未改变的信息,调用本地cache 缓存,如果改变就会重新得到。

- 针对第二个HTTP GET,从服务器响应的HTTP状态码和短语是什么?服务器是否明确地返回文件的内容?请解释。
答:很显然不会有的,因为服务器未改变文件,所以返回304 Modified,也就是304 未改变,因此我们不会得到请求信息的,直接调用本地的cache。

2.3 检索长文件
在我们到目前为止的例子中,检索的文档是简短的HTML文件。 接下来我们来看看当我们下载一个长的HTML文件时会发生什么。 按以下步骤操作:
- 启动您的浏览器,并确保您的浏览器缓存被清除,如上所述。
- 启动Wireshark数据包嗅探器
- 在您的浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file3.html 您的浏览器应显示相当冗长的美国权利法案。
- 停止Wireshark数据包捕获,并在display-filter-specification窗口中输入“http”,以便只显示捕获的HTTP消息。
- (注意:如果无法连接网络并运行Wireshark,则可以使用http-ethereal-trace-3数据包跟踪来回答以下问题。)
- 您的浏览器发送多少HTTP GET请求消息?哪个数据包包含了美国权利法案的消息?
答:我的浏览器仅仅发送了一个HTTP GET 请求信息,在追踪的数据包中,第 14 个
包含请求GET message 的 Bill 或 Rights。

- 哪个数据包包含响应HTTP GET请求的状态码和短语?
答:第 14 个包包括相关联的状态代码和短语,状态代码是200 OK。

- 响应中的状态码和短语是什么?
答:HTTP/1.1 200 OK\r\n:请求的状态码:200 短语: OK
- 需要多少包含数据的TCP段来执行单个HTTP响应和权利法案文本?
答:从图中看出我们有 4 个TCP 协议承载单个 HTTP 响应和权利法案的文本。

2.4 具有签入对象的HTML文档
现在我们已经看到Wireshark如何显示捕获的大型HTML文件的数据包流量,我们可以看看当浏览器使用嵌入的对象下载文件时,会发生什么,即包含其他对象的文件(在下面的例子中是图像文件) 的服务器。
执行以下操作:
- 启动您的浏览器。
- 启动Wireshark数据包嗅探器。
- 在浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/HTTP-wireshark-file4.html 您的浏览器应显示包含两个图像的短HTML文件。这两个图像在基本HTML文件中被引用。也就是说,图像本身不包含在HTML文件中;相反,图像的URL包含在已下载的HTML文件中。如书中所述,您的浏览器将不得不从指定的网站中检索这些图标。我们的出版社的图标是从 www.aw-bc.com 网站检索的。而我们第5版(我们最喜欢的封面之一)的封面图像存储在manic.cs.umass.edu服务器。
- 停止Wireshark数据包捕获,并在display-filter-specification窗口中输入“http”,以便只显示捕获的HTTP消息。
- (注意:如果无法连接网络并运行Wireshark,则可以使用http-ethereal-trace-4数据包跟踪来回答以下问题。)
- 您的浏览器发送了几个HTTP GET请求消息? 这些GET请求发送到哪个IP地址?
答:发送了3 个HTTP GET 请求消息,这些GET 请求发送到了一个 Internet 地址:128.119.245.12

- 浏览器从两个网站串行还是并行下载了两张图片?请说明。
答:由于这些包都是先后发出的,有时间差,所以是串行下载

2.5 HTTP认证
最后,我们尝试访问受密码保护的网站,并检查网站的HTTP消息交换的序列。URL http://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wireshark-file5.html 是受密码保护的。用户名是“wireshark-students”(不包含引号),密码是“network”(再次不包含引号)。所以让我们访问这个“安全的”受密码保护的网站。执行以下操作:
- 请确保浏览器的缓存被清除,如上所述,然后关闭你的浏览器,再然后启动浏览器
- 启动Wireshark数据包嗅探器。
- 在浏览器中输入以下URL http://gaia.cs.umass.edu/wireshark-labs/protected_pages/HTTP-wiresharkfile5.html 在弹出框中键入所请求的用户名和密码。
- 停止Wireshark数据包捕获,并在display-filter-specification窗口中输入“http”,以便只显示捕获的HTTP消息。
- (注意:如果无法连接网络并运行Wireshark,则可以使用http-ethereal-trace-5数据包跟踪来回答以下问题。)
- 对于您的浏览器的初始HTTP GET消息,服务器响应(状态码和短语)是什么响应?
答:服务器先返回401 Authorization Required,即未授权,要求登陆才能访问

- 当您的浏览器第二次发送HTTP GET消息时,HTTP GET消息中包含哪些新字段?
答:访问内容文章来源:https://www.toymoban.com/news/detail-733694.html

提示:新版 Wireshark 自带给base64 加密的用户名和密码解码,因此就不用网站工具了。文章来源地址https://www.toymoban.com/news/detail-733694.html
参考
- 第二章Wireshark实验1:HTTP:https://blog.csdn.net/qq_41708792/article/details/102495369
- 《计算机网络—自顶向下方法》学习笔记:https://github.com/moranzcw/Computer-Networking-A-Top-Down-Approach-NOTES
到了这里,关于《计算机网络—自顶向下方法》 Wireshark实验(二):HTTP协议分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!