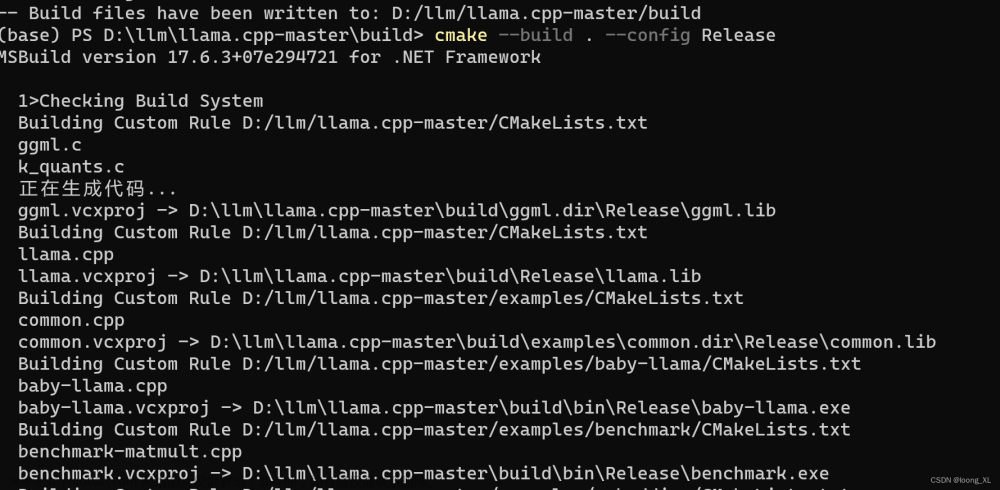
使用transformers加载decapoda-research/llama-7b-hf的踩坑记录。
-
ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported.
解决办法:
https://github.com/huggingface/transformers/issues/22222
将tokenizer_config.json中LLaMATokenizer改为LlamaTokenizer。文章来源:https://www.toymoban.com/news/detail-733716.html -
RecursionError: maximum recursion depth exceeded while getting the str of an object.
解决办法:
https://github.com/huggingface/transformers/issues/22762
使用tokenizer_config.json替换原本的tokenizer_config.json文章来源地址https://www.toymoban.com/news/detail-733716.html
到了这里,关于decapoda-research/llama-7b-hf 的踩坑记录的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[llama懒人包]ChatGPT本地下位替代llama-7b,支持全平台显卡/CPU运行](https://imgs.yssmx.com/Uploads/2024/02/521746-1.png)