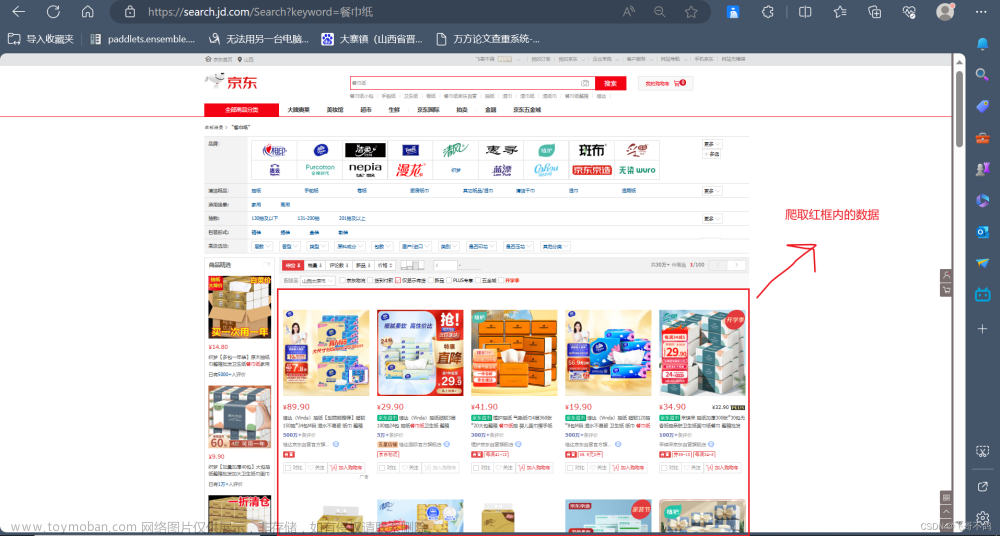
该项目主要参考与:http://c.biancheng.net/python_spider/selenium-case.html
你看完上述项目内容之后,会发现京东登录是一个比较坑的点,selenium控制浏览器没有登录京东,导致我们自动爬取网页被重定向到京东登录注册页面。
因此,我们要单独能一个登录注册。
但是,发现京东的验证功能 -- 滑动图片/发送验证码到手机目前我没办法解决,因此我们可以手动验证:我们启动浏览器,自己手动验证完之后,跳转到京东首页。
1. 登录功能文章来源:https://www.toymoban.com/news/detail-734161.html
# 登录
def login_html(self, loginname, password):
self.browser.get(url=self.url)
# 进入登录页面
self.browser.find_element(by=By.LINK_TEXT, value='你好,请登录').click()
time.sleep(2)
# 选择账户登录方式
self.browser.find_element(by=By.LINK_TEXT, value='账户登录').click()
# 输入框输入账号和密码
self.browser.find_element(value='loginname').send_keys(loginname)
self.browser.find_element(value='nloginpwd').send_keys(password)
time.sleep(2)
# 登录
self.browser.find_element(value='loginsubmit').click()
# 登录成功会跳转到京东首页,并且没有请登录字段。
# 延长30s,自己手工验证;30s,之内没验证,自动断开
start_time = time.time()
while True:
condition = (self.browser.page_source.find('你好,请登录') == -1) and (
self.browser.current_url == 'https://www.jd.com/')
# 如果登录成功,跳出循环
if condition:
return True
time1 = int(time.time() - start_time)
# 60s没验证成功,直接终止selenium进程
if time1 >= 60:
self.browser.quit()
return False2.完整代码 文章来源地址https://www.toymoban.com/news/detail-734161.html
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
class JdSpider(object):
def __init__(self):
self.url = 'https://www.jd.com/'
self.browser = webdriver.Chrome() # 创建无界面参数的浏览器对象
self.i = 0 # 计数,一共有多少件商品
# 输入地址+输入商品+点击按钮,切记这里元素节点是京东首页的输入栏、搜索按钮
def get_html(self):
self.browser.find_element(by=By.XPATH, value='//*[@id="key"]').send_keys('python书籍')
self.browser.find_element(by=By.XPATH, value="//*[@class='form']/button").click()
# 登录
def login_html(self, loginname, password):
self.browser.get(url=self.url)
# 进入登录页面
self.browser.find_element(by=By.LINK_TEXT, value='你好,请登录').click()
time.sleep(2)
# 选择账户登录方式
self.browser.find_element(by=By.LINK_TEXT, value='账户登录').click()
# 输入框输入账号和密码
self.browser.find_element(value='loginname').send_keys(loginname)
self.browser.find_element(value='nloginpwd').send_keys(password)
time.sleep(2)
# 登录
self.browser.find_element(value='loginsubmit').click()
# 登录成功会跳转到京东首页,并且没有请登录字段。
# 延长30s,自己手工验证;30s,之内没验证,自动断开
start_time = time.time()
while True:
condition = (self.browser.page_source.find('你好,请登录') == -1) and (
self.browser.current_url == 'https://www.jd.com/')
# 如果登录成功,跳出循环
if condition:
return True
time1 = int(time.time() - start_time)
# 60s没验证成功,直接终止selenium进程
if time1 >= 60:
self.browser.quit()
return False
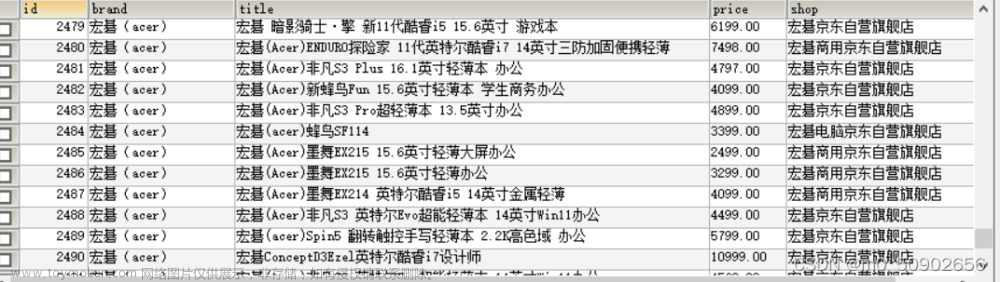
def get_data(self):
# 执行js语句,拉动进度条件, 把进度条件拉倒最底部+提取商品信息
self.browser.execute_script(
'window.scrollTo(0,document.body.scrollHeight)'
)
# 给页面元素加载时预留时间
time.sleep(2)
# 用 xpath 提取每页中所有商品,最终形成一个大列表
li_list = self.browser.find_elements(by=By.XPATH, value='//*[@id="J_goodsList"]/ul/li')
for li in li_list:
# 构建空字典
item = {}
item['name'] = li.find_element(by=By.XPATH, value='.//div[@class="p-name"]/a/em').text.strip()
item['price'] = li.find_element(by=By.XPATH, value='.//div[@class="p-price"]').text.strip()
item['count'] = li.find_element(by=By.XPATH, value='.//div[@class="p-commit"]/strong').text.strip()
item['shop'] = li.find_element(by=By.XPATH, value='.//div[@class="p-shopnum"]').text.strip()
print(item)
self.i += 1
def run(self):
is_login = self.login_html(loginname, password)
# 如果登录失败直接终结函数
if not is_login :
return
self.get_html()
# 循环执行点击“下一页”操作
while True:
# 获取每一页要抓取的数据
self.get_data()
# 判断是否是最一页
if self.browser.page_source.find('pn-next disabled') == -1:
self.browser.find_element(by=By.CLASS_NAME, value='pn-next').click()
# 预留元素加载时间
time.sleep(1)
else:
print('数量', self.i)
break
time.sleep(3)
self.browser.quit()
if __name__ == '__main__':
loginname = '用户名'
password = '密码'
spider = JdSpider()
spider.run()到了这里,关于selenium京东商城爬取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!