声明:本文章中所有内容仅供学习交流,不可用于任何商业用途和非法用途,否则后果自负,如有侵权,请联系作者立即删除!由于本人水平有限,如有理解或者描述不准确的地方,还望各位大佬指教!!
练习网站:
Q3JhenkgUHJvTW9ua2V5IGh0dHBzOi8vd3d3LnBhbnpob3UuZ292LmNuL3p3Z2tfMTU4NjEvemZ4eGdremwvZmR6ZGdrbnJfNTgzNTQxNi9senlqXzU4MzU0MTcvemZ3al81ODM1NDE4L2luZGV4Lmh0bWw=
网站分析:
打开开发者工具,发现数据走的是wss协议,如图

前面的文章中也有介绍过,以下特征就是代表着wss协议

既然知道了数据走的wss协议,那么我们就看他的wss链接,如图。但是我们发现wss链接是由几个加密值拼接的,那么我们的任务就是破解加密值以及寻找解密方法和入口

实战操作:
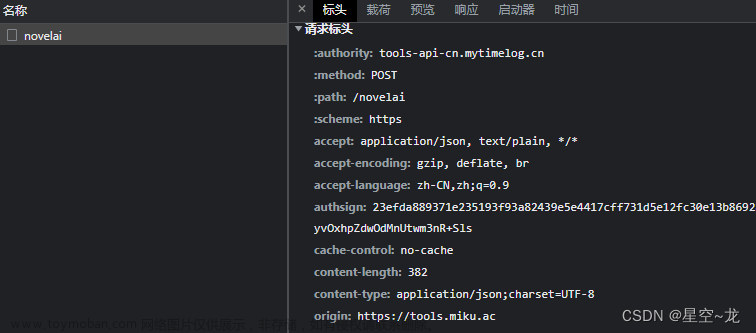
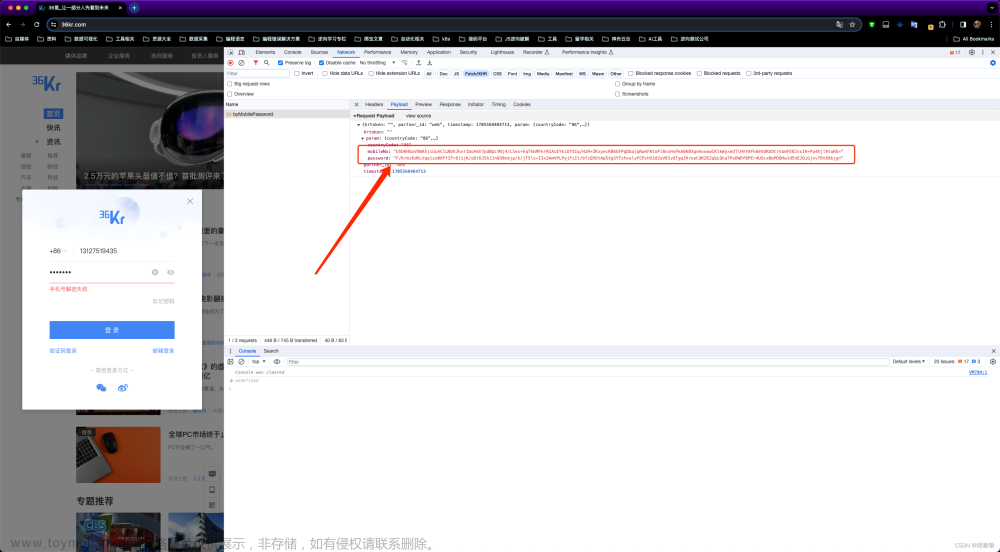
想必细心的大佬们都能发现,在ajax接口中,其响应的cookie值是和wss链接是吻合的,如图,那么,我们就可以大胆的请求这个接口了

然后接口还需要传参,参数值是加密的,那么我们就需要破解加密参数

又经过跟栈,找到了参数的加密入口,i 即为加密值,我们又发现请求接口时,请求头有对Fetch-Mode(为定值)和etag两个值有校验,那么我们同时还要拿到etag的值

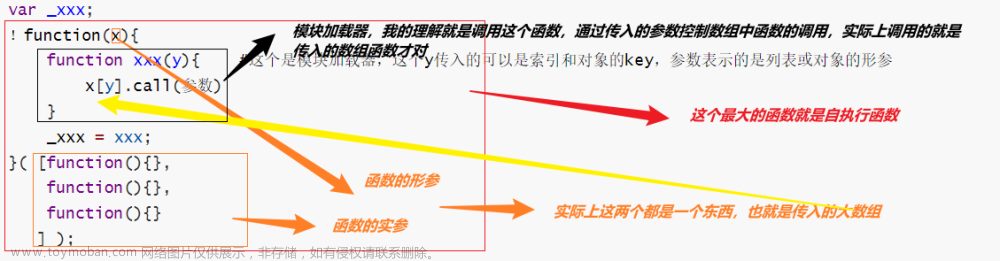
而 i 的值是有 r 函数对 L 进行操作的,那么我们可以模拟 L 的生成(对url进行改变即可),但是我们却没有 r 函数

往上检查js代码,发现了 r 的生成位置

看到 r = n(42),并跟进去,就知道 r 是由webpack生成的,这里的webpack的处理可以参考前面文章,这里就不做过多介绍了
 当 r 和 etag 复原之后,就可以正常生成加密参数了, 如图
当 r 和 etag 复原之后,就可以正常生成加密参数了, 如图

运行结果如图

那么我们就能拿到ajax接口的响应cookie值了,就可以生成wss链接了,如图
import execjs
from spider_util.utils import *
def data_sign():
# 读取js文件
with open('./2.js', 'r', encoding='utf-8') as f:
reader = f.read()
# 加载编译读取内容
loader = execjs.compile(reader)
# 调用js文件中的方法
r = loader.call('fjm_panzhou_sdk')
# 返回结果
return r
data_sign = data_sign()
etag = data_sign[0]
param = data_sign[1]
headers = {
"content-type": "application/json; charset=UTF-8",
"etag": etag,
"fetch-mode": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36",
}
url = "https://www.panzhou.gov.cn/1ywuKELSO2ahQuWZ/api/v1/sessions"
data = {
"data": param
}
data = json.dumps(data, separators=(',', ':'))
response = requests.post(url, headers=headers, data=data)
wss_param1 = response.cookies.get('dGg2aCfMMK97Ro270mqBFu5qjC8TQbL2opnHvbEpM', '')
wss_param2 = response.cookies.get('FW9uCWqlVzC22m1KfCMCjfvFHpRMsgt', '')
print(wss_param1, wss_param2)
wss_url = f"wss://www.panzhou.gov.cn/1ywuKELSO2ahQuWZ/pr/{wss_param1}/b/ws/m01j9wq8pw/{wss_param2}" # oiysmb2g7k
print(wss_url)
然后用wss协议发送请求链接,接收服务器响应结果,就能拿到数据了,但是却请求失败了
import websocket
import _thread as thread
import time
cookie = f'FW9uCWqlVzC22m1KfCMCjfvFHpRMsgt={wss_param2};dGg2aCfMMK97Ro270mqBFu5qjC8TQbL2opnHvbEpM={wss_param1}'
headers2 = {
"Pragma": "no-cache",
"Origin": "https://www.panzhou.gov.cn",
"Accept-Language": "zh-CN,zh;q=0.9",
"Sec-WebSocket-Key": "krDSpbfAbFkDxWiFXTQWxA==",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36",
"Upgrade": "websocket",
"Cache-Control": "no-cache",
"Cookie": cookie,
"Connection": "Upgrade",
"Sec-WebSocket-Version": "13",
"Sec-WebSocket-Extensions": "permessage-deflate; client_max_window_bits"
}
def on_message(ws, message):
"""收到对方消息处理方法"""
print("对方发来的消息:", "".join(url_unquote(message)))
time.sleep(5) # 控制发送频率
ws.send('ping') # 我方决定再回一个消息
def on_error(ws, error):
""" 错误处理方法 """
print(error)
def on_close(ws,code,msg):
""" 关闭处理方法 """
print("代号:",code)
print("对方关闭发来的消息:", msg)
print("### 程序结束 ###")
def on_open(ws):
""" 运行入口 """
def run(*args):
ws.send('ping') # 我方发送第一个消息
thread.start_new_thread(run, ()) # 开启线程
# websocket.enableTrace(True) # 是否打开日志信息
ws = websocket.WebSocketApp(wss_url,
header=headers2, # 设置请求头
on_open=on_open, # 设置运行入口
on_message=on_message, # 设置收到消息处理
on_close=on_close, # 发生关闭处理
on_error=on_error, # 错误处理
)
ws.run_forever()
这个问题基本上有两种原因,第一是wss_url不完全正确,第二就是请求头有其他检测。而小编已经对可能校验的cookie进行处理了,那目前只剩下wss_url的准确性了。经过仔细观察链接发现,如图参数值也是有变动的

而该参数就与上面ajax请求传参的tabId长度相等,且该值也是变动的。那么小编就且将两者值保持对应,再次进行wss请求

这次请求就能正常返回数据了,结果如图



实战总结:
js逆向的过程就是这样,是一个不断研究和自我推敲的过程,不过是大佬还是新手小白,都是需要一步一步去入口,定位加密参数,寻找解密方法,完成参数复原,模拟正常浏览器请求服务器。所以小编还是希望大家在这个过程中能不断尝试,不断进步文章来源:https://www.toymoban.com/news/detail-734378.html
那么,今日的分享就到这里,想要学习更多的python爬虫和js逆向的相关技巧和知识的小伙伴们一定要点下关注哟,后期会不定时分享相关干货内容文章来源地址https://www.toymoban.com/news/detail-734378.html
到了这里,关于WebSocket爬虫与JS逆向实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!