引言
近日,在学习完操作系统的进程调度部分后,我萌生了一个有趣的想法:通过编写代码来模拟进程调度算法,以加深自己对这一知识点的理解。于是,我花了一整天的时间投入到了这个突发奇想的实践中。
背景
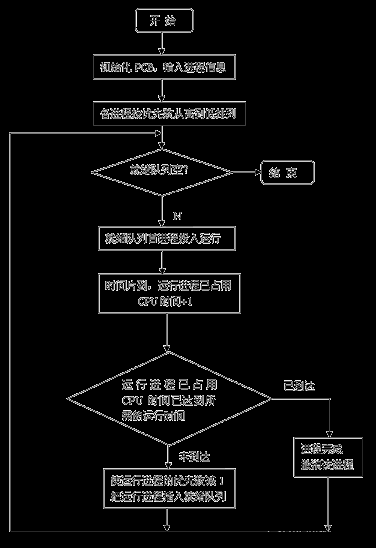
进程调度是操作系统中的重要概念,它决定了如何合理地分配处理器时间,以便多个进程能够高效地并发运行。在学习完进程调度算法后,我想通过编写代码来模拟其中一些经典的调度算法,包括先来先服务(FCFS)、最短作业优先(SJF)、轮转调度(Round Robin)、最高响应比(HRRN)和优先级调度。
前言
这里先简单介绍一下我们在进程调度问题里面常见的用语:(以下我用“作业”代表进程和线程)
# 周转时间 = 完成时间- 到达时间
# 带权周转时间 = 周转时间 /运行时间
# 等待时间 = 周转时间- 运行时间
# 平均带权周转时间=带权周转时间 /作业数量
完成时间:操作系统执行这个作业所需的时间
到达时间:作业到达就绪队列的时刻
周转时间:作业被提交给系统开始,到作业完成为止的这段时间间隔
代码实现(每行代码都有注释)
1. 先来先服务 (FCFS)
基本思想
先来先服务的调度算法:最简单的调度算法,系统将按照作业到达的先后次序来进行调度,优先从后备队列中,选择一个或多个位于队列头部的作业,把他们调入内存,分配所需资源、创建进程,然后放入“就绪队列”,直到该进程运行到完成或发生某事件堵塞后,进程调度程序才将处理机分配给其他进程。
实现代码(可直接运行)
# 周转时间 = 完成时间- 到达时间
# 带权周转时间 = 周转时间 /运行时间
# 等待时间 = 周转时间- 运行时间
class Job: # 作业类
def __init__(self, name, arrival_time, burst_time):
self.name = name # 作业名
self.arrival_time = arrival_time # 作业到达时间
self.burst_time = burst_time # 作业运行时间
def fcfs(Jobs):
print("先来先服务算法-----------------")
print("进程\t到达时间\t执行时间\t完成时刻\t周转时间\t等待时间\t带权周转时间")
current_time = 0 # 当前时间,记录每次作业运行完后的时间点
total_waiting_time = 0 # 总等待时间
total_turnaround_time_rate = 0 # 总带权周转时间
Jobs.sort(key=lambda x: (x.arrival_time, x.burst_time)) # 按到达时间和执行时间排序
for job in Jobs:
if current_time < job.arrival_time: # 作业到达时间比当前时间早(小),则等待
current_time = job.arrival_time # 更新当前时间为作业到达时间
completion_time = round((current_time + job.burst_time),2) # 作业完成时间=当前时间+作业运行时间
turnaround_time = round((completion_time - job.arrival_time),2) # 作业周转时间=完成时间-到达时间
waiting_time = round((turnaround_time - job.burst_time),2) # 等待时间=周转时间-运行时间
turnaround_time_rate = round((turnaround_time / job.burst_time),) # 带权周转时间=周转时间/运行时间
print(
f"{job.name}\t{job.arrival_time}\t\t{job.burst_time}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
current_time = completion_time # 更新当前时间为作业完成时间
total_waiting_time += waiting_time # 累加等待时间
total_turnaround_time_rate += turnaround_time_rate # 累加带权周转时间
print("\n作业总用时:", current_time)
print("平均等待时间:", total_waiting_time / len(Jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(Jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
# 示例作业列表
Jobs = [
Job("P1", 0, 10),
Job("P2", 5, 4),
Job("P3", 2, 8),
Job("P4", 10, 5),
Job("P5", 2, 5)
]
fcfs(Jobs)
2. 最短作业优先 (SJF)
基本思想
当所有作业都到达就绪队列时,这时候操作系统会优先执行所需时间最少的作业(之前我这里理解错了,我以为当有作业0时刻到达,就先执行这个0时刻到达的作业,然后再执行所需时间最短的作业)
实现代码(可直接运行)
#非抢占式的最短作业优先调度算法:
#先执行0时刻到达的执行时间最短的作业
class Job:
def __init__(self, name, arrival_time, burst_time):
self.name = name
self.arrival_time = arrival_time
self.burst_time = burst_time
def sjf(Jobs):
print("最短作业优先算法-----------------")
print("进程\t到达时间\t执行时间\t完成时刻\t周转时间\t等待时间\t带权周转时间")
current_time = 0 # 当前时间,记录每次作业运行完后的时间点
total_waiting_time = 0 # 总等待时间
total_turnaround_time_rate = 0 # 总带权周转时间
Jobs.sort(key=lambda x: (x.burst_time, x.arrival_time)) # 按到达时间和运行时间排序
#for job in Jobs:
# print(job.name)
#这里的for循环,判断是否有0时刻到达的作业,将0时刻到达的执行时间最短的作业放到队列首部先执行
for job in Jobs:
if job.arrival_time==0:
Jobs.remove(job)
Jobs.insert(0,job) #插入到队首
break #上面已经按照运行时间拍好序了,所以这里找到的作业是所有0时刻到达的作业中执行时间最短的,直接退出循环
for job in Jobs:
if current_time < job.arrival_time: # 当前时间小于作业到达时间,则等待
current_time = job.arrival_time # 当前时间更新为作业到达时间
completion_time = round((current_time + job.burst_time),2) # 作业完成时间=当前时间+作业运行时间
turnaround_time = round((completion_time - job.arrival_time),2) #周转时间=作业完成时间-作业到达时间
waiting_time = round((turnaround_time - job.burst_time),2) #等待时间=周转时间-作业运行时间
turnaround_time_rate = round((turnaround_time / job.burst_time),2) #带权周转时间=周转时间/作业运行时间
print(
f"{job.name}\t\t{job.arrival_time}\t\t{job.burst_time}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
current_time = completion_time # 当前时间更新为作业完成时间
total_waiting_time += waiting_time # 总等待时间累加
total_turnaround_time_rate += turnaround_time_rate # 总带权周转时间累加
print("\n作业总用时:", current_time)
print("平均等待时间:", total_waiting_time / len(Jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(Jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
# 示例作业列表
Jobs = [
Job("P1", 0, 10),
Job("P2", 5, 4),
Job("P3", 2, 8),
Job("P4", 10, 5),
Job("P5", 2, 5)
]
sjf(Jobs)
3. 轮转调度 (Round Robin)
基本思想
给每个作业固定的执行时间,根据作业到达的先后顺序让作业在固定的时间片内执行,执行完成后便调度下一个进程执行,时间片轮转调度不考虑进程等待时间和执行时间,属于抢占式调度。优点是兼顾长短作业;缺点是平均等待时间较长,上下文切换较费时。适用于分时系统。
实现代码(可直接运行)
# 时间片轮转算法
class Job:
def __init__(self, name, arrival_time, burst_time):
self.name = name
self.arrival_time = arrival_time
self.burst_time = burst_time
def round_robin(Jobs, time_slice):
print("时间片轮转算法-----------------")
print("进程\t到达时间\t执行时间\t完成时刻\t周转时间\t等待时间\t带权周转时间")
current_time = 0
remaining_time = [job.burst_time for job in Jobs] # 用于记录每个作业的剩余执行时间
completed_jobs = [] # 已完成的作业队列
total_waiting_time = 0 # 总等待时间
total_turnaround_time_rate = 0 # 总带权周转时间
while any(remaining > 0 for remaining in remaining_time):# 只要有作业的剩余执行时间大于0,就继续执行
for i, job in enumerate(Jobs):# 遍历作业列表
if remaining_time[i] > 0 and job not in completed_jobs: # 如果作业的剩余执行时间大于0且作业没有完成
if remaining_time[i] <= time_slice: # 如果作业的剩余执行时间小于等于时间片,说明作业可以在本轮执行完
current_time += remaining_time[i] # 当前时间加上作业的剩余执行时间
remaining_time[i] = 0 # 作业的剩余执行时间置为0
completed_jobs.append(job) # 将作业加入已完成的作业队列
else: # 如果作业的剩余执行时间大于时间片,说明作业不能在本轮执行完
current_time += time_slice # 当前时间加上时间片
remaining_time[i] -= time_slice # 作业的剩余执行时间减去时间片
if (len(completed_jobs)==0):
continue;
for job in completed_jobs:
completion_time = round((current_time),2) # 完成时间=当前时间
turnaround_time = round((completion_time - job.arrival_time),2) # 周转时间=完成时间-到达时间
waiting_time = round((turnaround_time - job.burst_time),2) # 等待时间=周转时间-执行时间
turnaround_time_rate = round((turnaround_time / job.burst_time),2) # 带权周转时间=周转时间/执行时间
print(
f"{job.name}\t{job.arrival_time}\t\t{job.burst_time}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
total_waiting_time += waiting_time # 累加等待时间
total_turnaround_time_rate += turnaround_time_rate # 累加带权周转时间
completed_jobs.remove(job)
print("\n用时:", current_time)
print("平均等待时间:", total_waiting_time / len(Jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(Jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
# 示例作业列表
Jobs = [
Job("P1", 0, 4),
Job("P2", 1, 3),
Job("P3", 2, 4),
Job("P4", 3, 2),
Job("P5", 4, 4)
]
time_slice = 4 # 设置时间片大小
round_robin(Jobs, time_slice)
4.优先级调度算法
基本思想
给每个作业都设置一个优先级,然后在调度的时候,在所有处于就绪状态的任务中选择优先级最高的任务去运行。
实现代码(可直接运行)
#非抢占式优先级调度算法,当所有进程都处于就绪状态时,按照优先级从高到低顺序选择一个进程执行
class Job:
def __init__(self, name, arrival_time, burst_time, priority):
self.name = name
self.arrival_time = arrival_time
self.burst_time = burst_time
self.priority = priority #作业优先级
def priority_scheduling(Jobs):
print("优先级调度算法-----------------")
print("进程\t到达时间\t执行时间\t优先级\t完成时刻\t周转时间\t等待时间\t带权周转时间")
current_time = 0
completed_jobs = [] #记录已经完成的作业列表
while Jobs:
max_priority = float('-inf') #设置负无穷小为目前的最大优先级
selected_job = None #记录当前选中的作业
for job in Jobs:#选出到达作业中的优先级最高的作业
if job.arrival_time <= current_time and job not in completed_jobs: #如果作业到达时间小于(早于)等于当前时间,并且作业还没有被完成
if job.priority > max_priority:#如果作业优先级大于当前最大优先级,则将当前作业设为选中作业
max_priority = job.priority
selected_job = job
if selected_job is None: #如果没有选中作业,则说明当前时间没有到达作业,则直接跳过
current_time += 1
continue
completion_time = round((current_time + selected_job.burst_time),2) # 完成时间 = 当前时间 + 作业运行时间
turnaround_time = round((completion_time - selected_job.arrival_time),2)#周转时间 = 完成时间 - 到达时间
waiting_time = round((turnaround_time - selected_job.burst_time),2)#等待时间 = 周转时间 - 运行时间
turnaround_time_rate = round((turnaround_time / selected_job.burst_time),2) #带权周转时间 = 周转时间 / 运行时间
print(
f"{selected_job.name}\t\t{selected_job.arrival_time}\t\t{selected_job.burst_time}\t\t{selected_job.priority}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
current_time = completion_time #当前时间更新为完成时间
completed_jobs.append(selected_job) #将选中作业加入已完成作业列表
Jobs.remove(selected_job) #将选中作业从作业列表中移除
total_waiting_time = sum(turnaround_time - job.burst_time for job in completed_jobs)#计算总等待时间
total_turnaround_time_rate = sum(turnaround_time / job.burst_time for job in completed_jobs)#计算总带权周转时间
print("\n用时:", current_time)
print("平均等待时间:", total_waiting_time / len(completed_jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(completed_jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
# 示例作业列表
Jobs = [
Job("P1", 0, 10, 3),
Job("P2", 5, 4, 1),
Job("P3", 2, 8, 4),
Job("P4", 10, 5, 2),
Job("P5", 2, 5, 5)
]
priority_scheduling(Jobs)
5.高响应比优先调度算法(HRRN)
基本思想
高响应比优先调度算法(Highest Response Ratio Next)是一种介于FCFS(先来先服务算法)与SJF(短作业优先算法)之间的折中算法,根据作业的响应比惊醒调度。既考虑作业等待时间又考虑作业运行时间,既照顾短作业又不使长作业等待时间过长,改进了调度性能。
响应比=(作业等待时间+作业运行时间)/作业运行时间
实现代码
#响应比=(等待时间+作业运行时间)/作业运行时间
#响应比越大,优先级越高
class Job:
def __init__(self, name, arrival_time, burst_time):
self.name = name
self.arrival_time = arrival_time
self.burst_time = burst_time
#计算响应比
def calculate_response_ratio(job, current_time):
wait_time = max(0, current_time - job.arrival_time) #更新等待时间
response_ratio = (wait_time + job.burst_time) / job.burst_time #计算响应比
return response_ratio
def hrrn(Jobs):
print("高响应比优先算法(HRRN)-----------------")
print("进程\t到达时间\t执行时间\t完成时刻\t周转时间\t等待时间\t带权周转时间")
current_time = 0 #当前时间
completed_jobs = [] #已完成的作业队列
while Jobs:
max_response_ratio = -1 #设置目前最大响应比为-1,响应比越大,优先级越高
selected_job = None
for job in Jobs:#计算每个作业的当前响应比
if job.arrival_time <= current_time and job not in completed_jobs: #如果作业已到达且未完成
response_ratio = calculate_response_ratio(job, current_time) #计算响应比
if response_ratio > max_response_ratio:
max_response_ratio = response_ratio
selected_job = job
if selected_job is None: #如果没有作业被选中,说明当前时间没有作业到达
current_time += 1 #当前时间加1
continue
completion_time = round((current_time + selected_job.burst_time),2) #计算完成时间
turnaround_time = round((completion_time - selected_job.arrival_time),2) #计算周转时间
waiting_time = round((turnaround_time - selected_job.burst_time),2) #计算等待时间
turnaround_time_rate =round((turnaround_time / selected_job.burst_time),2) #计算带权周转时间
print(
f"{selected_job.name}\t{selected_job.arrival_time}\t\t{selected_job.burst_time}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
current_time = completion_time #更新当前时间
completed_jobs.append(selected_job) #将已完成的作业加入已完成作业队列
Jobs.remove(selected_job) #将已完成的作业从作业队列中移除
total_waiting_time = sum(turnaround_time - job.burst_time for job in completed_jobs) #计算总等待时间
total_turnaround_time_rate = sum(turnaround_time / job.burst_time for job in completed_jobs) #计算总带权周转时间
print("\n用时:", current_time)
print("平均等待时间:", round(total_waiting_time / len(completed_jobs)),2)
avg_turnaround_time_rate = total_turnaround_time_rate / len(completed_jobs)
print("平均带权周转时间:", round(avg_turnaround_time_rate),2)
# 示例作业列表
Jobs = [
Job("P1", 8, 2),
Job("P2", 8.3, 0.5),
Job("P3", 8.5, 0.1),
Job("P4", 9, 0.4),
#Job("P5", 4, 4)
]
hrrn(Jobs)
6.整合
这里我将五个算法封装在了同一个py文件中,方便用多个测试用例调用这些算法
class Job:
def __init__(self, name, arrival_time, burst_time, priority=None):
self.name = name
self.arrival_time = arrival_time
self.burst_time = burst_time
self.priority = priority
def fcfs(Jobs):
print("作业-到达时间-服务时间-优先权")
for Job in Jobs:
print(f"{Job.name}\t{Job.arrival_time}\t{Job.burst_time}\t{Job.priority}")
current_time = 0
total_waiting_time = 0
total_turnaround_time_rate = 0
print("进程\t到达时间\t执行时间\t完成时刻\t周转时间\t等待时间\t带权周转时间")
for job in Jobs:
if current_time < job.arrival_time:
current_time = job.arrival_time
completion_time = round((current_time + job.burst_time),2) # 作业完成时间=当前时间+作业运行时间
turnaround_time = round((completion_time - job.arrival_time),2) # 作业周转时间=完成时间-到达时间
waiting_time = round((turnaround_time - job.burst_time),2) # 等待时间=周转时间-运行时间
turnaround_time_rate = round((turnaround_time / job.burst_time),) # 带权周转时间=周转时间/运行时间
print(
f"{job.name}\t\t{job.arrival_time}\t\t{job.burst_time}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
current_time = completion_time
total_waiting_time += waiting_time
total_turnaround_time_rate += turnaround_time_rate
print("\n用时:", current_time)
print("平均等待时间:", total_waiting_time / len(Jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(Jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
def sjf(Jobs):
print("最短作业优先算法-----------------")
print("进程\t到达时间\t执行时间\t完成时刻\t周转时间\t等待时间\t带权周转时间")
current_time = 0 # 当前时间,记录每次作业运行完后的时间点
total_waiting_time = 0 # 总等待时间
total_turnaround_time_rate = 0 # 总带权周转时间
Jobs.sort(key=lambda x: (x.burst_time, x.arrival_time)) # 按到达时间和运行时间排序
#for job in Jobs:
# print(job.name)
#这里的for循环,判断是否有0时刻到达的作业,将0时刻到达的执行时间最短的作业放到队列首部先执行
for job in Jobs:
if job.arrival_time==0:
Jobs.remove(job)
Jobs.insert(0,job) #插入到队首
break #上面已经按照运行时间拍好序了,所以这里找到的作业是所有0时刻到达的作业中执行时间最短的,直接退出循环
for job in Jobs:
if current_time < job.arrival_time: # 当前时间小于作业到达时间,则等待
current_time = job.arrival_time # 当前时间更新为作业到达时间
completion_time = round((current_time + job.burst_time),2) # 作业完成时间=当前时间+作业运行时间
turnaround_time = round((completion_time - job.arrival_time),2) #周转时间=作业完成时间-作业到达时间
waiting_time = round((turnaround_time - job.burst_time),2) #等待时间=周转时间-作业运行时间
turnaround_time_rate = round((turnaround_time / job.burst_time),2) #带权周转时间=周转时间/作业运行时间
print(
f"{job.name}\t\t{job.arrival_time}\t\t{job.burst_time}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
current_time = completion_time # 当前时间更新为作业完成时间
total_waiting_time += waiting_time # 总等待时间累加
total_turnaround_time_rate += turnaround_time_rate # 总带权周转时间累加
print("\n作业总用时:", current_time)
print("平均等待时间:", total_waiting_time / len(Jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(Jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
def rr(Jobs, time_slice):
print("时间片轮转算法-----------------")
print("进程\t到达时间\t执行时间\t完成时刻\t周转时间\t等待时间\t带权周转时间")
current_time = 0
remaining_time = [job.burst_time for job in Jobs] # 用于记录每个作业的剩余执行时间
completed_jobs = [] # 已完成的作业队列
total_waiting_time = 0 # 总等待时间
total_turnaround_time_rate = 0 # 总带权周转时间
while any(remaining > 0 for remaining in remaining_time):# 只要有作业的剩余执行时间大于0,就继续执行
for i, job in enumerate(Jobs):# 遍历作业列表
if remaining_time[i] > 0 and job not in completed_jobs: # 如果作业的剩余执行时间大于0且作业没有完成
if remaining_time[i] <= time_slice: # 如果作业的剩余执行时间小于等于时间片,说明作业可以在本轮执行完
current_time += remaining_time[i] # 当前时间加上作业的剩余执行时间
remaining_time[i] = 0 # 作业的剩余执行时间置为0
completed_jobs.append(job) # 将作业加入已完成的作业队列
else: # 如果作业的剩余执行时间大于时间片,说明作业不能在本轮执行完
current_time += time_slice # 当前时间加上时间片
remaining_time[i] -= time_slice # 作业的剩余执行时间减去时间片
if (len(completed_jobs)==0):
continue;
for job in completed_jobs:
completion_time = round((current_time),2) # 完成时间=当前时间
turnaround_time = round((completion_time - job.arrival_time),2) # 周转时间=完成时间-到达时间
waiting_time = round((turnaround_time - job.burst_time),2) # 等待时间=周转时间-执行时间
turnaround_time_rate = round((turnaround_time / job.burst_time),2) # 带权周转时间=周转时间/执行时间
print(
f"{job.name}\t{job.arrival_time}\t\t{job.burst_time}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
total_waiting_time += waiting_time # 累加等待时间
total_turnaround_time_rate += turnaround_time_rate # 累加带权周转时间
completed_jobs.remove(job)
print("\n用时:", current_time)
print("平均等待时间:", total_waiting_time / len(Jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(Jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
def priority_scheduling(Jobs):
print("作业-到达时间-服务时间-优先权")
for Job in Jobs:
if(Job.priority==None):
Job.priority=0
print(f"{Job.name}\t{Job.arrival_time}\t{Job.burst_time}\t{Job.priority}")
current_time = 0
completed_jobs = []
print("进程\t到达时间\t执行时间\t优先级\t完成时刻\t周转时间\t等待时间\t带权周转时间")
while Jobs:
max_priority = float('-inf')
selected_job = None
for job in Jobs:
if job.arrival_time <= current_time and job not in completed_jobs:
if job.priority > max_priority:
max_priority = job.priority
selected_job = job
if selected_job is None:
current_time += 1
continue
completion_time = round((current_time + selected_job.burst_time),2) # 完成时间 = 当前时间 + 作业运行时间
turnaround_time = round((completion_time - selected_job.arrival_time),2)#周转时间 = 完成时间 - 到达时间
waiting_time = round((turnaround_time - selected_job.burst_time),2)#等待时间 = 周转时间 - 运行时间
turnaround_time_rate = round((turnaround_time / selected_job.burst_time),2) #带权周转时间 = 周转时间 / 运行时间
print(
f"{selected_job.name}\t\t{selected_job.arrival_time}\t\t{selected_job.burst_time}\t\t{selected_job.priority}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
current_time = completion_time
completed_jobs.append(selected_job)
Jobs.remove(selected_job)
total_waiting_time = sum(turnaround_time - job.burst_time for job in completed_jobs)
total_turnaround_time_rate = sum(turnaround_time / job.burst_time for job in completed_jobs)
print("\n用时:", current_time)
print("平均等待时间:", total_waiting_time / len(completed_jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(completed_jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
def hrrn(Jobs):
print("作业-到达时间-服务时间-优先权")
for Job in Jobs:
print(f"{Job.name}\t{Job.arrival_time}\t{Job.burst_time}\t{Job.priority}")
current_time = 0
completed_jobs = []
print("进程\t到达时间\t执行时间\t完成时刻\t周转时间\t等待时间\t带权周转时间")
while Jobs:
max_response_ratio = -1
selected_job = None
for job in Jobs:
if job.arrival_time <= current_time and job not in completed_jobs:
response_ratio = (current_time - job.arrival_time + job.burst_time) / job.burst_time
if response_ratio > max_response_ratio:
max_response_ratio = response_ratio
selected_job = job
if selected_job is None:
current_time += 1
continue
completion_time = round((current_time + selected_job.burst_time),2) #计算完成时间
turnaround_time = round((completion_time - selected_job.arrival_time),2) #计算周转时间
waiting_time = round((turnaround_time - selected_job.burst_time),2) #计算等待时间
turnaround_time_rate =round((turnaround_time / selected_job.burst_time),2) #计算带权周转时间
print(
f"{selected_job.name}\t\t{selected_job.arrival_time}\t\t{selected_job.burst_time}\t\t{completion_time}\t\t{turnaround_time}\t\t{waiting_time}\t\t{turnaround_time_rate:.2f}")
current_time = completion_time
completed_jobs.append(selected_job)
Jobs.remove(selected_job)
total_waiting_time = sum(turnaround_time - job.burst_time for job in completed_jobs)
total_turnaround_time_rate = sum(turnaround_time / job.burst_time for job in completed_jobs)
print("\n用时:", current_time)
print("平均等待时间:", total_waiting_time / len(completed_jobs))
avg_turnaround_time_rate = total_turnaround_time_rate / len(completed_jobs)
print("平均带权周转时间:", avg_turnaround_time_rate)
# 作业列表
Jobs2 = [
Job("P1", 0, 9),
Job("P2", 0, 6),
Job("P3", 0, 3),
Job("P4", 0, 5),
Job("P5", 0, 9)
]
Jobs = [
Job("P1", 0, 10, 3),
Job("P2", 1, 13, 1),
Job("P3", 2, 8, 4),
Job("P4", 3, 9, 2),
Job("P5", 2, 7, 5)
]
print("Complete by 黄奔on Nov. 1 at Jiangxi University of Traditional Chinese Medicine")
print("先来先服务算法-------------------------------------------------------------------------------------------------------------------------------")
fcfs(Jobs.copy())#浅拷贝,防止原列表被修改
print("\n最短作业优先算法-------------------------------------------------------------------------------------------------------------------------------")
sjf(Jobs.copy())
print("\n时间片轮转算法-------------------------------------------------------------------------------------------------------------------------------")
time_slice = 3
rr(Jobs.copy(), time_slice)
print("\n优先级调度算法-------------------------------------------------------------------------------------------------------------------------------")
priority_scheduling(Jobs.copy())
print("\n高响应比优先算法-----------------------------------------------------------------------------------------------------------------------------")
hrrn(Jobs.copy())
运行结果

总结
通过一天的努力,我成功地编写了用代码模拟进程调度算法的示例,包括先来先服务、最短作业优先、轮转调度和优先级调度算法。虽然这个实践实现的东西很简单,还有很多实际问题、特殊情况没有考虑到,但是这个过程不仅加深了我对操作系统进程调度算法的理解,还让我更深入地体验了算法在实际应用中的工作原理。我希望这种实践能够帮助我、同时帮助你们更好地掌握这一重要概念。文章来源:https://www.toymoban.com/news/detail-734698.html
写这篇文章是为了记录我今天的成果,当然以后我肯定用得上这些代码,毕竟我还没学操作系统这门课,下学期才学,我相信肯定有要我们算什么“周转时间”、“平均等待时间”的这些题目,大伙如果碰到了这种题目,可以用代码来检测一下自己的结果是不是正确(当然我写的示例过于简单,实际的调度比这个复杂了多,有些特殊情况可能没有考虑到)哈哈哈,如果你觉得我说的没错就给我点个赞呗!文章来源地址https://www.toymoban.com/news/detail-734698.html
到了这里,关于用代码模拟操作系统进程调度算法(Python)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!