ELK:日志收集平台
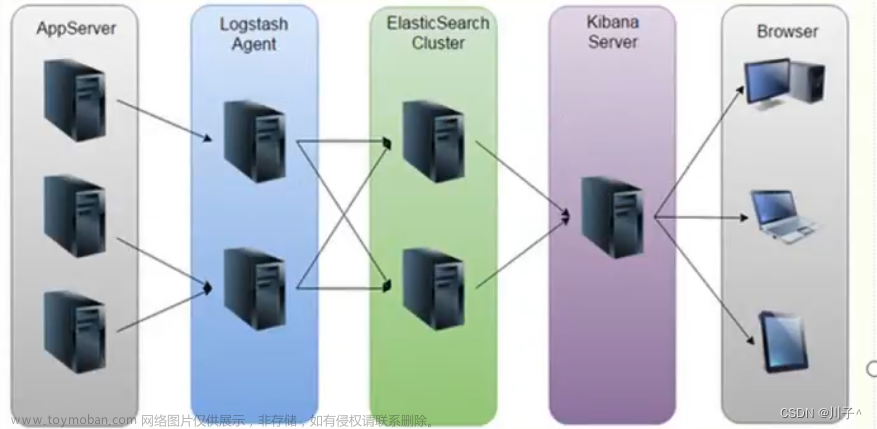
ELK由ElasticSearch、Logstash和Kibana三个开源工具组成:
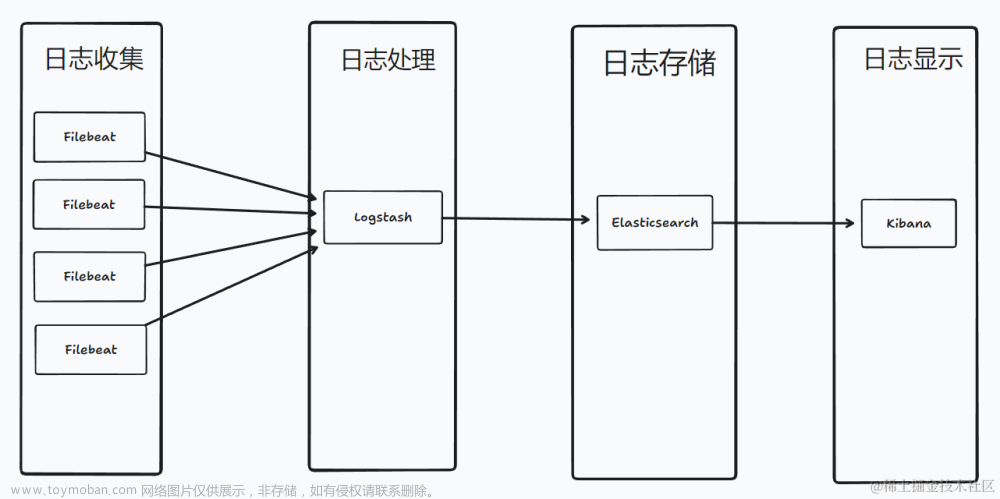
概念图 
组件介绍
1、Elasticsearch:
ElasticSearch是一个基于Lucene的开源分布式搜索服务。只搜索和分析日志
特点:分布式,零配置,自动发现,索引自动分片,索引副本机制,多数据源等。它提供了一个分布式多用户能力的全文搜索引擎。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
在elasticsearch集群中,所有节点的数据是均等的。
索引(库)–>类型(表)–>文档/日志(记录)
2、Logstash:
Logstash是一个完全开源工具,可以对你的日志进行收集、过滤、分析,并将其存储供以后使用(如,搜索),logstash带有一个web界面,搜索和展示所有日志。 **只收集和过滤日志,和改格式**
简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供很多功能强大的滤网以满足你的各种应用场景。
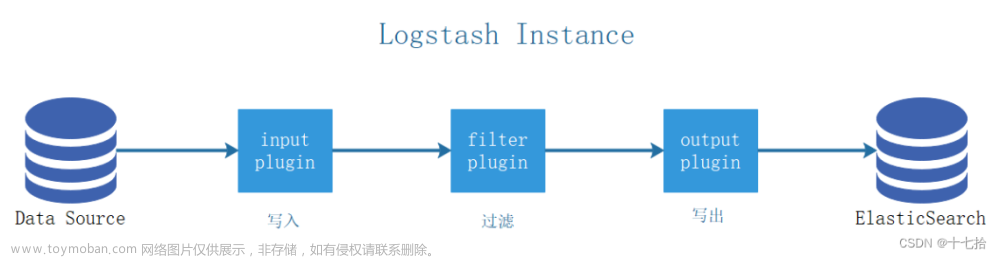
② Logstash的事件(logstash将数据流中等每一条数据称之为一个事件)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
logstash整个工作流程分为三个阶段:输入、过滤、输出。每个阶段都有强大的插件提供支持:
Input 必须,负责产生事件(Inputs generate events),常用的插件有**
- file 从文件系统收集数据
- syslog 从syslog日志收集数据
- redis 从redis收集日志
- beats 从beats family收集日志(如:Filebeats)
Filter常用的插件,负责数据处理与转换(filters modify them)
- grok是logstash中最常用的日志解释和结构化插件。:grok是一种采用组合多个预定义的正则表达式,用来匹配分割文本并映射到关键字的工具。
- mutate 支持事件的变换,例如重命名、移除、替换、修改等
- drop 完全丢弃事件
- clone 克隆事件
output 输出,必须,负责数据输出(outputs ship them elsewhere),常用的插件有
- elasticsearch 把数据输出到elasticsearch
- file 把数据输出为普通的文件
3、Kibana:
Kibana 是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮你汇总、分析和搜索重要数据日志。

2、环境介绍
| 安装软件 | 主机名 | IP地址 | 系统版本 |
| ------------------------ | :-------------------: | :-------------: | :------------: |
| Elasticsearch/ | mes-1-zk | 192.168.246.234 | centos7.4--3G |
| zookeeper/kafka/Logstash | es-2-zk-log | 192.168.246.231 | centos7.4--2G |
| head/Kibana | es-3-head-kib-zk-File | 192.168.246.235 | centos7.4---2G |
所有机器关闭防火墙,selinux
3、版本说明
Elasticsearch: 6.5.4 #https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.4.tar.gz
Logstash: 6.5.4 #https://artifacts.elastic.co/downloads/logstash/logstash-6.5.4.tar.gz
Kibana: 6.5.4 #https://artifacts.elastic.co/downloads/kibana/kibana-6.5.4-linux-x86_64.tar.gz
Kafka: 2.11-2.1 #https://archive.apache.org/dist/kafka/2.1.0/kafka_2.11-2.1.0.tgz
Filebeat: 6.5.4
相应的版本最好下载对应的插件
相关地址:
官网地址:https://www.elastic.co
官网搭建:https://www.elastic.co/guide/index.html



选择版本号
 第二个插件
第二个插件
 第三个插件
第三个插件

实施部署
1、 Elasticsearch部署
系统类型:Centos7.4
节点IP:172.16.246.234
软件版本:jdk-8u191-linux-x64.tar.gz、elasticsearch-6.5.4.tar.gz
示例节点:172.16.246.2341、安装配置jdk8,依赖包
ES运行依赖jdk8 -----三台机器都操作,先上传jdk1.8
[root@mes-1 ~]# tar xzf jdk-8u191-linux-x64.tar.gz -C /usr/local/
[root@mes-1 ~]# cd /usr/local/
[root@mes-1 local]# mv jdk1.8.0_191/ java编写环境变量
[root@mes-1 local]# vim etc/profile
JAVA_HOME=/usr/local/java
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
刷新查看版本
[root@mes-1 ~]# source /etc/profile
[root@mes-1 local]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
2、安装配置ES----只在第一台操作操作下面的部分
(1)创建运行ES的普通用户
[root@mes-1 ~]# useradd elsearch
[root@mes-1 ~]# passwd elsearch 123456
(2)安装配置ES
[root@mes-1 ~]# tar xzf elasticsearch-6.5.4.tar.gz -C /usr/local/
[root@mes-1 ~]# cd /usr/local/elasticsearch-6.5.4/config/
[root@mes-1 config]# ls
elasticsearch.yml log4j2.properties roles.yml users_roles
jvm.options role_mapping.yml users
[root@mes-1 config]# cp elasticsearch.yml elasticsearch.yml.bak
[root@mes-1 config]# vim elasticsearch.yml ----找个地方添加如下内容,提示最后俩行不要被注释掉拉,如果注释掉啦,则第二台机器监控不了
cluster.name: elk
node.name: elk01
node.master: true
node.data: true
path.data: /data/elasticsearch/data
path.logs: /data/elasticsearch/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
#discovery.zen.ping.unicast.hosts: ["192.168.246.234", "192.168.246.231","192.168.246.235"]
#discovery.zen.minimum_master_nodes: 2
#discovery.zen.ping_timeout: 150s
#discovery.zen.fd.ping_retries: 10
#client.transport.ping_timeout: 60s
http.cors.enabled: true
http.cors.allow-origin: "*"
配置项含义:
cluster.name 集群名称,各节点配成相同的集群名称。
node.name 节点名称,各节点配置不同。
node.master 指示某个节点是否符合成为主节点的条件。
node.data 指示节点是否为数据节点。数据节点包含并管理索引的一部分。
path.data 数据存储目录。
path.logs 日志存储目录。
bootstrap.memory_lock 内存锁定,是否禁用交换。
bootstrap.system_call_filter 系统调用过滤器。
network.host 绑定节点IP。
http.port 端口。
discovery.zen.ping.unicast.hosts 提供其他 Elasticsearch 服务节点的单点广播发现功能。
discovery.zen.minimum_master_nodes 集群中可工作的具有Master节点资格的最小数量,官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量。
discovery.zen.ping_timeout 节点在发现过程中的等待时间。
discovery.zen.fd.ping_retries 节点发现重试次数。
http.cors.enabled 是否允许跨源 REST 请求,用于允许head插件访问ES。
http.cors.allow-origin 允许的源地址。
(3)设置JVM堆大小
第一种方法
/usr/local/elasticsearch-6.5.4/config
[root@mes-1 config]# vim jvm.options ----将
-Xms1g ----修改成 -Xms2g
-Xmx1g ----修改成 -Xms2g
第二种方法 用一种即可
推荐设置为4G,请注意下面的说明: 电脑合适的情况下
sed -i 's/-Xms1g/-Xms4g/' /usr/local/elasticsearch-6.5.4/config/jvm.options
sed -i 's/-Xmx1g/-Xmx4g/' /usr/local/elasticsearch-6.5.4/config/jvm.options
注意:
确保堆内存最小值(Xms)与最大值(Xmx)的大小相同,防止程序在运行时改变堆内存大小。
堆内存大小不要超过系统内存的50%
(4)创建ES数据及日志存储目录
因为上面配置这个目录拉,所以要求创建
[root@mes-1 ~]# mkdir -p /data/elasticsearch/data (/data/elasticsearch)
[root@mes-1 ~]# mkdir -p /data/elasticsearch/logs (/log/elasticsearch)
(5)修改安装目录及存储目录权限
[root@mes-1 ~]# chown -R elsearch:elsearch /data/elasticsearch
[root@mes-1 ~]# chown -R elsearch:elsearch /usr/local/elasticsearch-6.5.4
3、系统优化(1)增加最大文件打开数
第一种方式 用一种即可 建议第一个
永久生效方法
echo "* - nofile 65536" >> /etc/security/limits.conf
第二种方法
(2)增加最大进程数
vim /etc/security/limits.conf —在文件最后面添加如下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
更多的参数调整可以直接用这个
解释:
soft xxx : 代表警告的设定,可以超过这个设定值,但是超过后会有警告。
hard xxx : 代表严格的设定,不允许超过这个设定的值。
nofile : 是每个进程可以打开的文件数的限制
nproc : 是操作系统级别对每个用户创建的进程数的限制
(3)增加最大内存映射数(调整使用交换分区的策略)
第一种方法,永久生效
vim /etc/sysctl.conf —添加如下
vm.max_map_count=262144
vm.swappiness=0
[root@mes-1 ~]# sysctl -p
解释:在内存不足的情况下,使用交换空间。 查看一下
第二种方法,临时添加
sysctl -w vm.max_map_count=262144
增大用户使用内存的空间(临时)
启动ES
切换到创建的用户下面
第一种方法
[root@mes-1 ~]# su - elsearch
Last login: Sat Aug 3 19:48:59 CST 2019 on pts/0
[root@mes-1 ~]$ cd /usr/local/elasticsearch-6.5.4/
[root@mes-1 elasticsearch-6.5.4]$ ./bin/elasticsearch #先启动看看报错不,需要多等一会
终止之后
[root@mes-1 elasticsearch-6.5.4]$ nohup ./bin/elasticsearch & #放后台启动 建议用这个
[1] 11462
nohup: ignoring input and appending output to ‘nohup.out’
第二种方法
su - elsearch -c "cd /usr/local/elasticsearch-6.5.4 && nohup bin/elasticsearch &"
切换回来root用户查看一下
[root@mes-1 elasticsearch-6.5.4]$ tail -f nohup.out #看一下是否启动
测试:浏览器访问http://192.168.246.234:9200

启动如果报下列错误
memory locking requested for elasticsearch process but memory is not locked
elasticsearch.yml文件
bootstrap.memory_lock : false
/etc/sysctl.conf文件
vm.swappiness=0
错误:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
意思是elasticsearch用户拥有的客串建文件描述的权限太低,知道需要65536个
解决:
切换到root用户下面 vim /etc/security/limits.conf
在最后添加
* hard nofile 65536
* hard nofile 65536
重新启动elasticsearch,还是无效?
必须重新登录启动elasticsearch的账户才可以,例如我的账户名是elasticsearch,退出重新登录。
另外*也可以换为启动elasticsearch的账户也可以,* 代表所有,其实比较不合适
启动还会遇到另外一个问题,就是
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
意思是:elasticsearch用户拥有的内存权限太小了,至少需要262114。这个比较简单,也不需要重启,直接执行
# sysctl -w vm.max_map_count=262144
就可以了
1、 Head插件安装 第二台机器
前提: head插件是Nodejs实现的,所以需要先安装Nodejs。
1.1 安装nodejs
nodejs官方下载地址:https://nodejs.org/
下载linux64位:
[root@es-3-head-kib ~]# wget https://nodejs.org/dist/v14.17.6/node-v14.17.6-linux-x64.tar.xz
[root@es-3-head-kib ~]# tar xf node-v14.17.6-linux-x64.tar.xz -C /usr/local/
vim /etc/profile 添加 如下配置
NODE_HOME=/usr/local/node-v14.17.6-linux-x64
JAVA_HOME=/usr/local/java
PATH=$NODE_HOME/bin:$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
#由于我这里,ES也装在了此台机器上,所以环境变量这样配置;不能删除jdk的配置
[root@es-3-head-kib ~]# source /etc/profile #刷新一下
[root@es-3-head-kib ~]# node --version #查看一下版本
v14.17.6
[root@es-3-head-kib ~]# npm -v #查看一下版本
6.14.15
npm 是随同NodeJS一起安装的包管理工具,能解决NodeJS代码部署上的很多问题。
1.2 安装git
需要使用git方式下载head插件,下面安装git:
[root@es-3-head-kib local]# yum install -y git
[root@es-3-head-kib local]# git --version
git version 1.8.3.1
1.3 下载及安装head插件
[root@es-3-head-kib ~]# cd /usr/local/
[root@es-3-head-kib local]# git clone git://github.com/mobz/elasticsearch-head.git
第一种方法,把网换成国内的淘宝,直接进行下载
[root@es-3-head-kib local]# cd elasticsearch-head/
可以将npm源设置为国内淘宝的,确保能下载成功
[root@es-3-head-kib elasticsearch-head]# npm install -g cnpm --registry=https://registry.npm.taobao.org
[root@es-3-head-kib elasticsearch-head]# npm install #报错,不用管它
第二种方法,如果你的网好可以直接下载
[root@es-3-head-kib elasticsearch-head]# npm install #注意:这里直接安装,可能会失败,如果你的网络没问题,才能下载成功
修改地址:如果你的…和ES没在一台机器上,需要进行如下2处修改,在一台机器,不修改即可
[root@es-3-head-kib elasticsearch-head]# vim Gruntfile.js

[root@es-3-head-kib elasticsearch-head]# vim _site/app.js #配置连接es的ip和port

1.4 配置elasticsearch,允许head插件访问
第一台机器咱们上面配置最后俩行 确保是打开的
[root@es-3-head-kib ~]# vim /usr/local/elasticsearch-6.5.4/config/elasticsearch.yml
在配置最后面,加2行

然后,重启elasticsearch
1.5 测试
进入到head目录,执行npm run start
[root@es-3-head-kib ~]# cd /usr/local/elasticsearch-head/
[root@es elasticsearch-head]# nohup npm run start &
netstat -lntp # 过滤一下端口
 启动成功后,在浏览器访问:http://192.168.153.190:9100/ ,内部输入 http://192.168.153.190:9200/ 点击连接测试,输出绿色背景字体说明配置OK。
启动成功后,在浏览器访问:http://192.168.153.190:9100/ ,内部输入 http://192.168.153.190:9200/ 点击连接测试,输出绿色背景字体说明配置OK。


报错思路
如果说最后启动没有启动起来
nohup npm run start & 过滤端口也过滤不出来的话
建议文章来源:https://www.toymoban.com/news/detail-734930.html
 文章来源地址https://www.toymoban.com/news/detail-734930.html
文章来源地址https://www.toymoban.com/news/detail-734930.html
到了这里,关于1-ELK+ Elasticsearch+head+kibana、企业内部日志分析系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!


![[ELK] ELK企业级日志分析系统](https://imgs.yssmx.com/Uploads/2024/01/810686-1.png)