本次使用3台服务器进行安装Hadoop。其中服务器系统均为Centos7.6、Hadoop版本为3.3.6、jdk版本为1.8.0_371。
################################################################################################
此外,大数据系列教程还在持续的更新中(包括跑一些实例、安装数据库、spark、mapreduce、hive等),欢迎大家关注我
基础环境部署
服务器基础环境部署
主机更名
为了使主机间通信更为方便,同时为了更好辨别各个主机,我们先将主机进行更名。
查看主机名cat /etc/hostname
如果发现需要修改主机名,则使用 hostnamectl set-hostname 主机名,修改完成后重新登陆即可实现修改,这里分别将主机名改为Hadoop01、Hadoop02、Hadoop03。
设置host映射
修改hosts表vim /etc/hosts
新增(根据自身机器情况分别填入3个虚拟机的ip及对应名称)
192.168.10.150 hadoop01
192.168.10.151 hadoop02
192.168.10.152 hadoop03
关闭防火墙、设置ssh免密登录、服务器时间同步、创建统一工作目录
临时关闭防火墙systemctl stop firewalld.service
禁止防火墙开机自启动systemctl disable firewalld.service
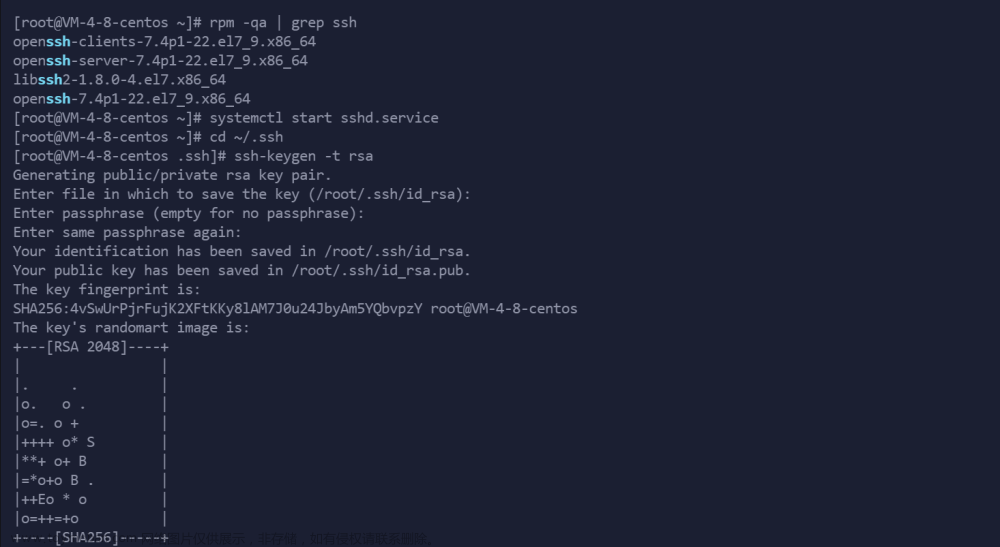
设置ssh 公钥 私钥免密登录
在三台主机(hadoop01、hadoop02、hadoop03)上,分别输入以下命令:
ssh-keygen -t rsa
//向各个虚拟机拷贝公钥(拷贝时,要输入主机密码)
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
服务器时间同步
安装 ntpyum -y install ntp
同步时间,这里以阿里云3号服务器为例ntpdate ntp3.aliyun.com
创建统一工作目录(分别为服务、数据、软件,三台主机都要创建)
mkdir -p /export/server/
mkdir -p /export/data/
mkdir -p /export/software/
jdk的下载与安装
Hadoop01机器的jdk下载与安装
本次选用jdk-8u371的版本。下载地址
https://www.oracle.com/java/technologies/oracle-java-archive-downloads.html
将软件上传至/export/server/路径下,解压缩并删除原安装包。
解压命令:tar -zxvf jdk-8u371-linux-x64.tar.gz
修改配置文件/etc/profile,配置环境变量
输入命令:vim /etc/profile
快捷键G o跳转文件最后一行,写入以下配置文件(具体路径根据自身机器情况修改):
export JAVA_HOME=/export/server/jdk1.8.0_371
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存后重新加载配置source /etc/profile
输入java -version测试是否成功(若出现java版本则为配置成功)
远程分发给其余两台机器
文件拷贝与环境变量拷贝
scp -r /export/server/jdk1.8.0_371/ root@hadoop02:/export/server/
scp -r /export/server/jdk1.8.0_371/ root@hadoop03:/export/server/
scp /etc/profile root@hadoop02: /etc/
scp /etc/profile root@hadoop03: /etc/
输入命令重新加载配置:source /etc/profile
输入java -version测试是否成功(若出现java版本则为配置成功)
Hadoop的下载与安装
Hadoop的下载
本次选用3.3.6的版本。下载地址
Apache Hadoop
将软件上传至/export/server/路径下,解压缩并删除原安装包。
解压命令:tar -zxvf hadoop-3.3.6.tar.gz
修改Hadoop配置文件
文件1 路径/export/server/hadoop-3.3.6/etc/Hadoop/hadoop-env.sh文件尾部添加
export JAVA_HOME=/export/server/jdk1.8.0_371
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#注意将jdk目录改为实际目录
文件2 路径/export/server/hadoop-3.3.6/etc/Hadoop/core-site.xml
将以下配置文件复制到<configuration>``</configuration>之间
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.6</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
文件3 路径/export/server/hadoop-3.3.6/etc/Hadoop/hdfs-site.xml
将以下配置文件复制到<configuration> </configuration>之间
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:9868</value>
</property>
文件4 路径/export/server/hadoop-3.3.6/etc/Hadoop/mapred-site.xml
将以下配置文件复制到<configuration> </configuration>之间
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
文件5 路径/export/server/hadoop-3.3.6/etc/Hadoop/yarn-site.xml
将以下配置文件复制到<configuration> </configuration>之间
<!-- 设置YARN集群主角色运行机器位置 -->
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop02:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
文件6 路径/export/server/hadoop-3.3.6/etc/Hadoop/workers
将以下配置文件复制到文件中(该步骤为告诉机器hadoop工作的各个虚拟机)
hadoop01
hadoop02
hadoop03
将hadoop添加到环境变量中
输入命令vim /etc/profile
#文件尾部添加以下内容
export HADOOP_HOME=/export/server/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存之后输入命令source /etc/profile
配置文件部分完成
远程拷贝文件
配置文件拷贝与环境变量拷贝
scp -r /export/server/hadoop-3.3.6 root@hadoop02:/export/server/
scp -r /export/server/hadoop-3.3.6 root@hadoop03:/export/server/
scp /etc/profile root@hadoop02: /etc/
scp /etc/profile root@hadoop03: /etc/
在其他的两台机器上输入命令source /etc/profile之后,输入hadoop测试hadoop安装是否正常。文章来源:https://www.toymoban.com/news/detail-735228.html
HDFS NameNode format格式化(初始化)
输入命令hdfs namenode -format之后,若返回命令中含有Storage directory则代表成功。 文章来源地址https://www.toymoban.com/news/detail-735228.html
文章来源地址https://www.toymoban.com/news/detail-735228.html
到了这里,关于Centos7系统下搭建Hadoop 3.3.6的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![Hadoop集群搭建记录 | 云计算[CentOS7] | 伪分布式集群 Master运行WordCount](https://imgs.yssmx.com/Uploads/2024/01/406862-1.png)