GPT实战系列-如何用自己数据微调ChatGLM2模型训练
1、训练数据
广告文案生成模型
输入文字:类型#裙颜色#蓝色风格#清新*图案#蝴蝶结
输出文案:裙身处采用立体蝴蝶结装饰辅以蓝色条带点缀,令衣身造型饱满富有层次的同时为其注入一丝甜美气息。将女孩清新娇俏的一面衬托而出。
训练和测试数据组织:
{"content": "类型#裙*颜色#蓝色*风格#清新*图案#蝴蝶结", "summary": "裙身处采用立体蝴蝶结装饰辅以蓝色条带点缀,令衣身造型饱满富有层次的同时为其注入一丝甜美气息。将女孩清新娇俏的一面衬托而出。"}
{"content": "类型#裙*颜色#白色*风格#清新*图案#碎花*裙腰型#松紧腰*裙长#长裙*裙衣门襟#拉链*裙款式#拉链", "summary": "这条颜色素雅的长裙,以纯净的白色作为底色,辅以印在裙上的点点小碎花,<UNK>勾勒出一幅生动优美的“风景图”,给人一种大自然的清新之感,好似吸收新鲜空气的那种舒畅感。腰间贴心地设计成松紧腰,将腰线很好地展现出来,十分纤巧,在裙子的侧边,有着一个隐形的拉链,能够让你穿脱自如。"}
数据可以从 下载链接,test.json
或者Tsinghua Cloud 下载处理好的 ADGEN 完整数据集。可以看到解压后的文件有两个,分别是train.json和dev.json。
2、训练脚本
ChatGLM2的训练源代码:https://github.com/THUDM/ChatGLM2-6B
文件目录结构:
├── FAQ.md
├── MODEL_LICENSE
├── README.md 说明文档
├── README_EN.md
├── api.py
├── cli_demo.py
├── evaluation
│ ├── README.md
│ └── evaluate_ceval.py
├── openai_api.py
├── ptuning
│ ├── README.md 说明文档
│ ├── arguments.py
│ ├── deepspeed.json
│ ├── ds_train_finetune.sh
│ ├── evaluate.sh
│ ├── evaluate_finetune.sh
│ ├── main.py
│ ├── train.sh 训练脚本
│ ├── train_chat.sh
│ ├── trainer.py
│ ├── trainer_seq2seq.py
│ ├── web_demo.py
│ └── web_demo.sh 测试脚本
├── requirements.txt 环境依赖文件
├── resources
│ ├── WECHAT.md
│ ├── cli-demo.png
│ ├── knowledge.png
│ ├── long-context.png
│ ├── math.png
│ ├── web-demo.gif
│ ├── web-demo2.gif
│ └── wechat.jpg
├── utils.py
├── web_demo.py
└── web_demo2.py
# 安装python3.10
pyenv install 3.10.4
# 安装相关依赖
pip install rouge_chinese nltk jieba datasets
pip install -f requirements.txt
p-tuning
P-tuning的全称是Prefix-tuning,意为“前缀调优”。它通过在模型输入前添加小段Discrete prompt(类似填空句),并只优化这个prompt来实现模型微调。P-tuning-v2是基于Prompt-tuning方法的NLP模型微调技术。总体来说,P-tuning-v2是Prompt tuning技术的升级版本,使得Prompt的表示能力更强,应用也更灵活广泛。它被认为是Prompt tuning类方法中效果最优且易用性最好的版本。
进入ptuning目录
代码实现对于 ChatGLM2-6B 模型基于 P-Tuning v2 的微调。P-Tuning v2 将需要微调的参数量,减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,预测最低只需要 7GB 显存即可运行。
将训练和测试数据解压后的 AdvertiseGen 目录放到ptuning目录下。
3、执行训练
训练之前,需要根据自己的训练需求,训练数据和机器配置情况修改代码。
调整
修改训练配置
修改train.sh
# 这两处改为自己数据集的路径
–train_file AdvertiseGen/train.json
–validation_file AdvertiseGen/dev.json
# 数据集少的话,训练步数可以调整
–max_steps 3000
–PRE_SEQ_LEN 和 LR 分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。
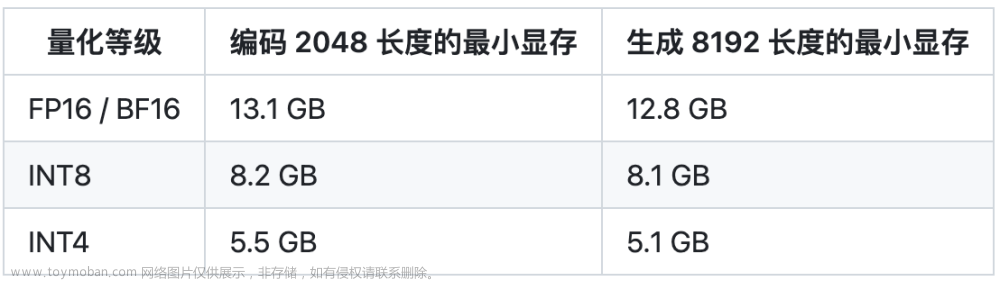
–模型量化、批次参数 P-Tuning-v2 方法会冻结全部的模型参数,可通过调整 quantization_bit 来被原始模型的量化等级,不加此选项则为 FP16 精度加载。
在默认配置 quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16 下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
–模型目录。如果你想要从本地加载模型,可以将 train.sh 中的 THUDM/chatglm2-6b 改为你本地的模型路径。
修改main.py
在代码的351行,代码注释掉了 trainer.save_model(),这是保存模型的语句。当训练完成后就会生成一个pytorch_model.bin文件,后面测试时会用到。
运行
执行以下指令进行训练:
./train.sh
当出现以下信息后,模型训练迭代开始。
{'loss': 3.0614, 'learning_rate': 0.018000000000000002, 'epoch': 4.21}
{'loss': 2.2158, 'learning_rate': 0.016, 'epoch': 8.42}
训练完成后,屏幕将打印这类信息:
***** train metrics *****
epoch = xx
train_loss = xx
train_runtime = xx
train_samples = xx
train_samples_per_second = xx
train_steps_per_second = xx
4、问题解决
问题一
from rouge_chinese import Rouge
ModuleNotFoundError: No module named 'rouge_chinese'
解决:
没有安装rouge模块,pip安装即可。
pip install rouge_chinese
问题二
[W socket.cpp:558] [c10d] The client socket has failed to connect to [localhost]:12355 (errno: 99 - Cannot assign requested address).
解决:
因为之前安装云容器,云主机访问不到,hosts把相应的配置注释掉即可。
问题三
RuntimeError: Default process group has not been initialized, please make sure to call init_process_group.
解决:
检查transforms版本,调整transformers版本即可。
问题四
ValueError: Unable to create tensor, you should probably activate truncation and/or padding with 'padding=True' 'truncation=True' to have batched tensors with the same length. Perhaps your features 。。
ERROR:torch.distributed.elastic.multiprocessing.api:failed (exitcode: 1) local_rank: 0 (pid: 16858) of binary
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
解决:
显存不够,调小batch_size等调低显存的方式。
End
相关文章:
GPT实战系列-ChatGLM2模型的微调训练参数解读
GPT实战系列-如何用自己数据微调ChatGLM2模型训练
GPT实战系列-ChatGLM2部署Ubuntu+Cuda11+显存24G实战方案文章来源:https://www.toymoban.com/news/detail-735413.html
GPT实战系列-Baichuan2本地化部署实战方案文章来源地址https://www.toymoban.com/news/detail-735413.html
到了这里,关于GPT实战系列-如何用自己数据微调ChatGLM2模型训练的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!