背景
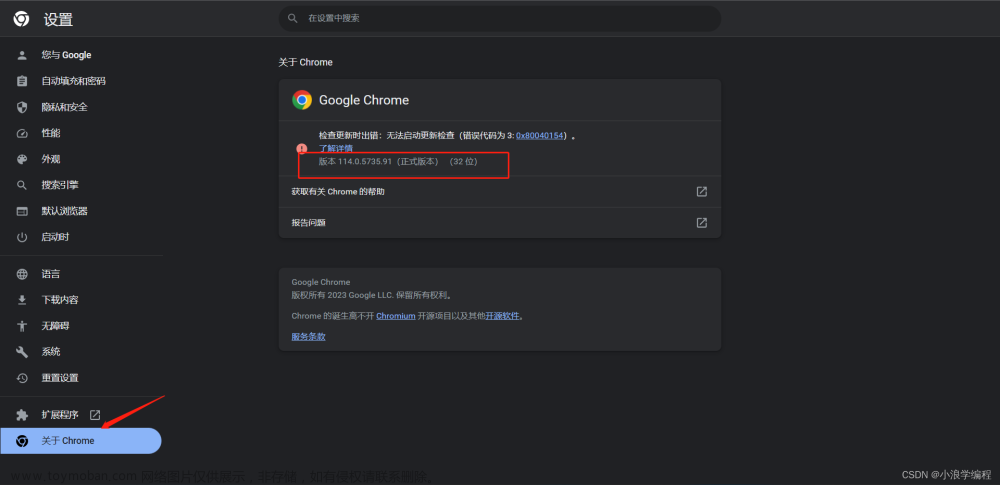
- 很多浏览器会自动更新,但是 driver 不会自动更新。为了确保 driver 版本和浏览器匹配,可以使用第三方库 webdriver_manager
代码
- 这个文件里封装了几个函数
- driver_seek : 根据给定的目录,和文件名称,查找该目录下是否有这个文件
- driver_download : 下载 webdriver 到指定目录,如果path参数不指定,会下载到 C:\Users\当前用户名 目录下,如果指定path,就下载到指定目录 —— 我因为有多个使用Selenium 的爬虫项目,所以会把 driver 下载到1个公用目录下
- driver_test : 测试上面这两个函数是否工作正常
# !/usr/bin/env python3
# _*_ coding:utf-8 _*_
"""
@File : init_webdriver.py
@Project : Scrapy
@CreateTime : 2023/1/2 17:02
@Author : biaobro
@Software : PyCharm
@Last Modify Time : 2023/1/2 17:02
@Version : 1.0
@Description : None
@20230207
# 安装webdriver-manager : pip install webdriver-manager
# webdriver-manager 在python3.11 下报错无法使用,改用python3.10 后正常
# 这个文件只需要完成 检测目标是否存在,如果不存在就下载的任务就好了,不需要做额外的设置,应用层的设置交给应用层
# 如果不写main 函数,被导入时就会自动执行
"""
from selenium import webdriver
# chrome, firefox, edge, IE
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
import os
# from webdriver_manager.firefox import GeckoDriverManager
# from webdriver_manager.microsoft import EdgeChromiumDriverManager
# from webdriver_manager.microsoft import IEDriverManager
def driver_seek(folder_name, file_name):
"""根据输入的文件名称查找对应的文件夹有无改文件,有则返回文件路径"""
for root, dirs, files in os.walk(folder_name):
if file_name in files:
# 当层文件内有该文件,输出文件地址
path = os.path.join(root, file_name) # r'{0}\{1}'.format(root, file_name)
print(path)
print('the driver has already been there. you could load it freely.')
return path
print(file_name + " doesn't exist in " + folder_name + ', please download it firstly.')
return None
def driver_download(path=None):
try:
# 默认 webdriver 会被下载到 .home/.wdm folder
# 本机 [C:\Users\biaob\.wdm\drivers\chromedriver\win32\97.0.4692.71\chromedriver.exe]
# silent logs and remove them from console
# os.environ['WDM_LOG_LEVEL'] = '0'
# disable the blank space in first line
# os.environ['WDM_PRINT_FIRST_LINE'] = 'False'
# 如果没有指定path参数,就下载到项目路径
# 如果指定,就下载到指定路径
if path is None:
# By default, all driver binaries are saved to user.home/.wdm folder.
# You can override this setting and save binaries to project.root/.wdm.
# 设置 'WDM_LOCAL' = '1' 修改设置,下载文件到项目路径
os.environ['WDM_LOCAL'] = '1'
# 下载地址:https://chromedriver.chromium.org/downloads
# 老式写法
# browser = webdriver.Chrome(executable_path=ChromeDriverManager().install()) # , options=options)
# 新式写法
print("driver will be downloaded into default project folder.")
ChromeService(ChromeDriverManager().install())
else:
# Set the directory where you want to download and save the webdriver.
# You can use relative and absolute paths.
print("driver will be downloaded into specified folder.")
path = ChromeDriverManager().install()
print(path)
return True
except Exception as e:
print(e)
return False
def driver_test(path, url="https://www.baidu.com"):
driver_path = driver_init()
# option set to avoid 'data' show in address bar
options = webdriver.ChromeOptions()
# options.add_argument('--no-sandbox')
# options.add_argument('--disable-dev-shm-usage')
# options.add_argument(r"user-data-dir=data")
# options.add_argument(r"headless")
browser = webdriver.Chrome(service=ChromeService(path), options=options)
browser.get(url)
if browser.title == "百度一下,你就知道":
print("selenium browser headless mode visit Baidu test passed.")
elif browser.title is not None:
print(f"selenium browser headless mode visit {url} test passed.")
else:
print("selenium browser headless mode test failed!")
# quit 必须要有,否则停留后台,需要在任务管理器中手动关闭
browser.quit()
# specify the path directly
# 指定本地目录
# driver = webdriver.Chrome('D:\Download\chromedriver_win32\chromedriver.exe')
# 用法示例
def driver_init():
parent_directory = r'..\\'
file_name = r'chromedriver.exe'
driver_path = driver_seek(parent_directory, file_name)
if driver_path is not None:
return driver_path
else:
driver_download(parent_directory)
return driver_seek(parent_directory, file_name)
运行效果
 文章来源:https://www.toymoban.com/news/detail-735546.html
文章来源:https://www.toymoban.com/news/detail-735546.html
文章来源地址https://www.toymoban.com/news/detail-735546.html
到了这里,关于Selenium - 自动下载 webdriver的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!