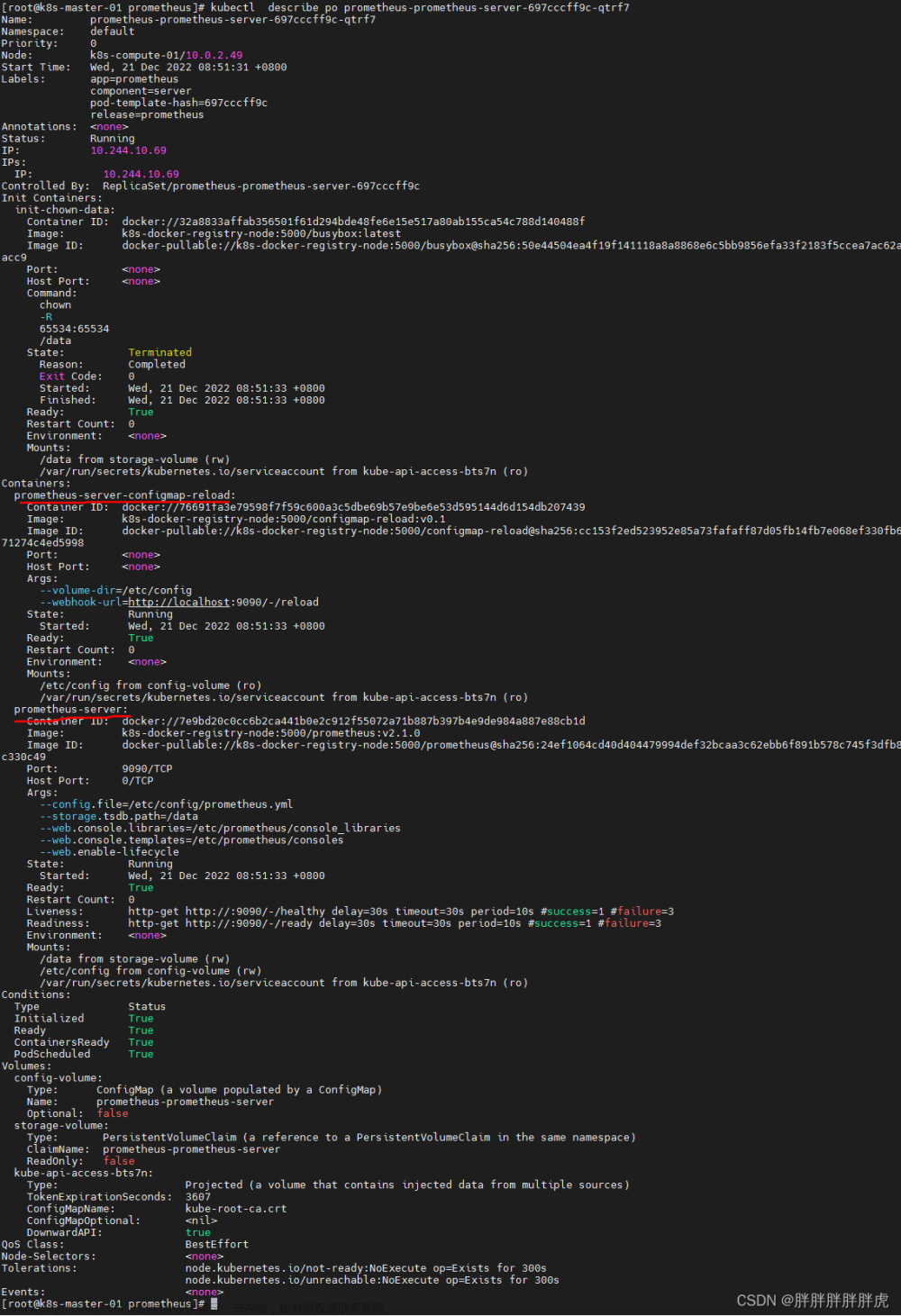
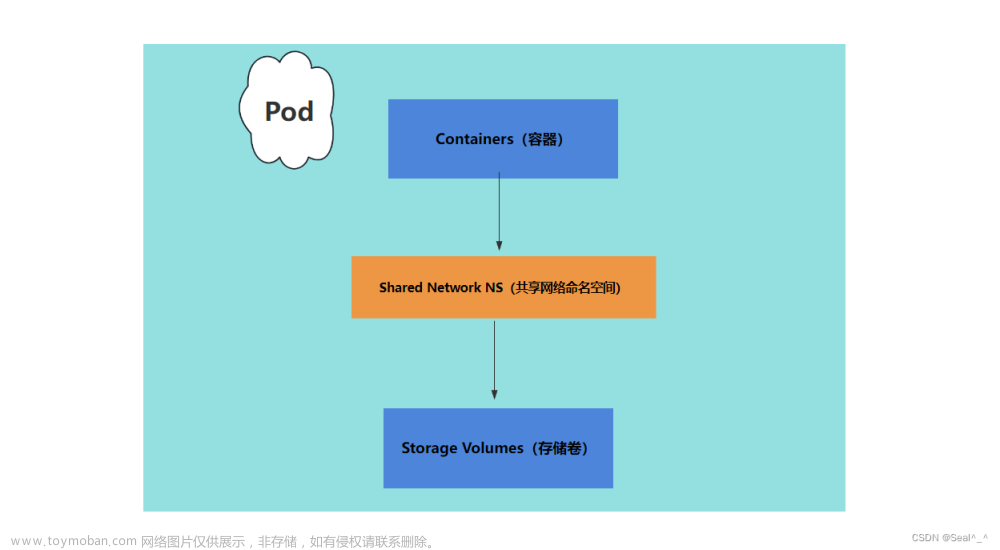
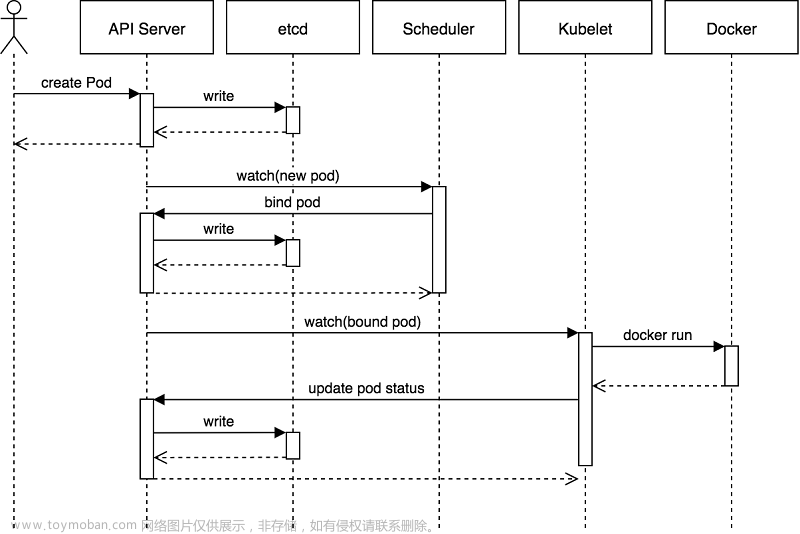
Pod
k8s中的port【端口:30000-32767】
port :为Service 在 cluster IP 上暴露的端口
targetPort:对应容器映射在 pod 端口上
nodePort:可以通过k8s 集群外部使用 node IP + node port 访问Service
containerPort:容器内部使用的端口

k8s 集群内部流程:
客户端→clusterIP:port→通过 tagerport→pod IP:container port
k8s 集群外部流程:
客户端→nodeIP:nodeport→通过 tagerport→pod IP:container port
k8s中的pod A 与 pod B 怎么互相通信
同一个节点
pause容器启动之前,会为容器创建虚拟一对ethernet接口,一个保留在宿主机vethxx(插在网桥Q上),一个保留在容器网络命名空间内,并重命名为eth0。两个虚拟接口的两端,从一端进入,另一端出来。任何Pod连接到该网桥的Pod都可以收发数据。
跨节点
跨节点Pod通信,相当于创建一个整个集群公用的【网桥】然后把集群中所有的Pod连接起来,就可以通信了。其中跨整个集群的 Pod ip 是唯一的,当报文从一个节点转发到另外一个节点时,报文首先通过veth,然后通过网桥转发到物理适配器网卡,最后转发到其它节点的虚拟网桥,进而到达veth目标容器。其实现方式有Flannel、calico、weave等。
pod基本概念
pod是 k8s 最小的创建和运行单元,一个 pod 包含几个容器
pod 存在的意义
-
在一组容器作为一个单元的情况下,难以对整体的容器简单地进行判断及有效地进行行动。(比如,一个容器死亡那么引入与业务无关的Pausc容器作为Pod的基础容器,以它的状态代表若整个容器组的状态,这样就可以解决该问题)
-
Pod里的多个应用容器共享Pausc容器的TP,共享Pausc容器挂裁的Volume,这样简化了应用容器之问的通信问题,也解决了容器之间的文件共享问题
k8s创建的pod分为两类:
-
自主式/静态pod
不被控制器管理的 pod ,没有自愈能力,一旦 pod 挂掉,不会被重新拉起,而且副本数量也不会因为达不到期望值而创建新的 pod
不存在etcd中
-
控制器管理的pod
被控制器管理的 pod ,有自愈能力,一旦pod 挂掉,会被重新拉起,而且副本数量 会因为达不到期望值而创建新的 pod
在Kubrenetes集群中Pod有如下两种使用方式
-
一个pod中运行一个容器
可以把Pod想象成是单个容器的封装,k8s管理的是Pod而不是直接管理容器。
-
一个pod中同时运行多个容器
一个Pod中也可以同时封装几个需要紧密耦合互相协作的容器,它们之间共享资源。这些在同一个Pod中的容器可以互相协作成为一个service单位,比如一个容器共享文件,另个“sidecar”容器来更新这些文件。Pod将这些容器的存储资源作为一个实体来管理

pause容器主要为每个容器提供以下功能:
-
在pod中担任Linux命名空间 (如网络命令空间) 共享的基础;
-
启用PID命名空间,开启init进程。
-
协调他的容器生命周期
-
提供健康检查和生存探针
pause容器使得pod中的所有容器可以共享两种资源:
-
网络
每个 pod 都会被分配一个唯一的IP地址,pod中所有容器共享网络空间,包括 ip 和端口
pod 内部的容器可以使用 localhost 互相通信
pod 中的容器与外界通信时,必须分配共享网络资源【例如使用宿主机的端口映射】
-
存储
pod可以指定多个共享的 volume,pod中的所有容器都可以访问共享的 volume
Volume也可以用来持久化Pod中的存储资源,以防容器重启后文件丢失
总结:
每个 Pod 都有一个特殊的被称为"基础容器"的 Pause 容器。Pause 容器对应的镜像属于K8s平台的一部分,除了 pause 容器,每个 Pod 还包含一个或者多个紧密相关的用户应用容器。
三种容器:
1、pause容器
- 给pod中的所有应用容器提供网络(共享IP)和存储(共享存储)。
- 资源共享:作为PID=1的进程【int进程】,管理整个pod 种容器组生命周期
2、初始化容器(init容器)
- 阻塞或者延迟应用容器的启动,可以为应用容器实现提供好运行环境和工具
- 多个init容器时,串行启动,每个init容器都必须在下一个init容器启动前完成启动和退出
3、应用容器(main)
- 在所有init容器成功启动和退出后应用容器才会启动 并行启动的,提供应用程序的业务
镜像拉取的策略【imagePullPolicy】
-
IfNotPresent:优先使用本地已存在的仓库,如本地没有,则从仓库镜像拉取
-
Always:总是从仓库拉取镜像 ,无论本地是否已存在镜像
-
Never:总是不从仓库拉去镜像 ,仅使用本地镜像
【注意:对于标签为 "latest" 的镜像文件,其默认的镜像获取策略即为 "Always" 而对于其他标签的镜像,其默认策略则为 "IfNotPresent"】
Pod容器的重启策略【restartPolicy】
container在同一层
-
Always:当容器退出后,总是重启容器,不管返回状态码如何【默认策略】
-
OnFailure:仅在容器异常退出时,【返回状态码非0】时,会重启容器
-
Never:容器退出时,从不重启容器,不管返回状态码如何
【注意: K8S 中不支持重启 Pod 资源,只有先重建后删除】
例1、



例2、



资源限制
当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。
当为 Pod 中的容器指定了 request 资源时,调度器就使用该信息来决定将 Pod 调度到哪个节点上。当还为容器指定了 limit 资源时,kubelet 就会确保运行的容器不会使用超出所设的 limit 资源量。kubelet 还会为容器预留所设的 request 资源量, 供该容器使用。
如果 Pod 运行所在的节点具有足够的可用资源,容器可以使用超出所设置的 request 资源量。不过,容器不可以使用超出所设置的 limit 资源量。
如果给容器设置了内存的 limit 值,但未设置内存的 request 值,Kubernetes 会自动为其设置与内存 limit 相匹配的 request 值。 类似的,如果给容器设置了 CPU 的 limit 值但未设置 CPU 的 request 值,则 Kubernetes 自动为其设置 CPU 的 request 值 并使之与 CPU 的 limit 值匹配。
官网示例:
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
Pod 和容器的资源请求和限制:
spec.containers [] .resources.requests.cpu #定义创建容器时预分配的CPU资源
spec.containers [] .resources.requests.memory #定义创建容器时预分配的内存资源
【创建pod容器时需要预留的资源,例:0.5 或者 500m 】
spec.containers [] .resources.limits.cpu #定义 cpu 的资源上限
spec.containers [] .resources.limits.memory #定义内存的资源上限
【pod容器能够使用的资源量的上限 MI、GI(2为底数),MI、GI(10为底数)】例:




生存探针(包含存活、就绪、启动)
-
livenessProbe【存活探针】
判断容器是否正在运行如果检测失败,则杀掉容器(不是pod),容器会根据容器策略决定是否重启
-
readinessProbe【就绪探针】
判断pod是否能够进入ready状态,做好接受请求的准备,如果探测失败就会进入 notready 状态并且 service 资源的 endpoints 中剔除,service将不会把访问请求转发给这个 pod
-
startupProbe【启动探针】
判断容器内的应用程序是否已启动,在探测成功转变为success之前,其他探针都会处于失效状态
Probe支持三种检查方法:
-
exec
通过command 设置执行在容器内执行的linux命令来探测,返回码为0,则表示探测成功
-
tcpSocket
对指定端口上的容器的IP地址进行TCP检查(三次握手)。如果端口打开,则诊断被认为是成功的文章来源:https://www.toymoban.com/news/detail-735582.html
-
httpGet
通过 http get 请求指定的容器端接口和 url路径,如果返回状态大于200且小于400,则表示成功文章来源地址https://www.toymoban.com/news/detail-735582.html
到了这里,关于k8s、pod的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!