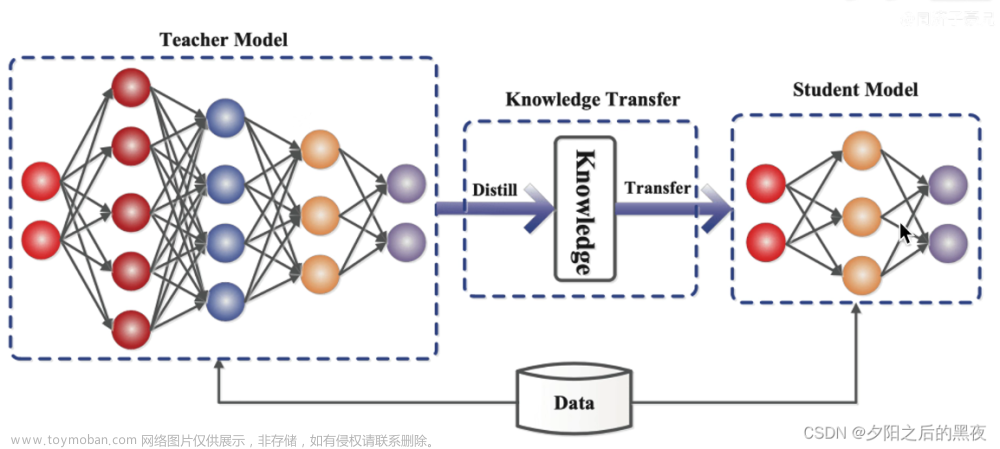
这篇论文的题目是 用于小样本Transformers的监督遮掩知识蒸馏
论文接收: CVPR 2023
论文地址: https://arxiv.org/pdf/2303.15466.pdf
代码链接: https://github.com/HL-hanlin/SMKD
1 Motivation
1.ViT在小样本学习(只有少量标记数据的小型数据集)中往往会 过拟合,并且由于缺乏 归纳偏置 而导致性能较差;
2.目前很多方法使用 自监督学习 和 监督学习 来缓解这个问题,但是没有方法能很好平衡监督和自监督两个的学习目标;
3.最近提出的 自监督掩蔽知识蒸馏 方法在各个领域的Transfomrers取得了先进的效果。
2 Ideas
提出了一种新的基于Transformer的监督知识蒸馏框架(SMKD)
1.将类标签纳入自监督知识蒸馏中,以填补自监督与监督学习之间的空白,从而有效地利用自监督学习的优势来缓解监督训练的过度拟合问题;
2.在 类(全局) 和 patch(局部) 级别上都制定了监督对比损失,允许在 类 和 patch tokens 上进行类内知识蒸馏,以学习到效果更好的小样本Transformer模型;
3.引入跨类内图像遮掩patch tokens重建的挑战性任务,以提高模型泛化性能。

本文结合了自监督知识蒸馏和监督对比学习,同时引入遮掩图像模型(MIM)
3 Related works
1.小样本学习
FSL 中最近的方法开始较少关注元学习,而更多地关注具有良好泛化能力的学习嵌入。
因此,本文提出了一个知识蒸馏框架来学习可泛化的嵌入
2.FSL 中的Vision Transformers
归纳偏置的缺乏使得 Transformer 因其数据量大的特性而臭名昭著,但仍然具有快速适应新类别的潜力。
本文提出的方法在没有明确纳入归纳偏置的Transformer结构依然表现良好
3.FSL 的自监督SSL
(1)自监督可以学习到对基类的较小的偏置表示,这通常会导致对新类的泛化能力更好
(2)两类工作将 SSL 合并到 FSL:一种通过辅助损失将自监督的代理任务纳入标准监督学习;一种采用自监督预训练、监督训练两阶段来训练few-shot Transformers
本文相比之前的工作,没有设计复杂的训练管道,而是在自监督预训练模型上使用监督训练,以填补自监督和监督知识蒸馏之间的差距。
4.SSL的遮掩图像模型(MIM)
恢复损坏的输入图像中遮掩的patch级目标内容
4 Methods
4.1 SMKD 框架
1.从跨类内图像(两个图像)分别生成两个视图。
2.第一个试图应用随机块遮掩,送入学生网络;同时第二个未遮掩试图送入教师网络。这两个网络都由一个ViT 主干的编码器和一个带有 3 层多层感知器 (MLP) 的投影头组成。
3.SMKD在类和patch级别上在类内跨试图中蒸馏知识。
L
[
c
l
s
]
L_{[cls}]
L[cls] 从
[
c
l
s
]
[cls]
[cls] 标记中蒸馏知识,而
L
[
p
a
t
c
h
]
L_{[patch]}
L[patch] 通过找到具有最高相似度的匹配标记对(由红色虚线连接)的密集对应关系,从
[
p
a
t
c
h
]
[patch]
[patch] 标记中提取知识。

4.2 初步:自监督知识蒸馏

具体来说,给定从训练集I 中均匀采样的单个图像 x,应用随机数据增强来生成两个增强视图 x 1 x^1 x1和 x 2 x^2 x2,然后将其输入教师和学生网络。
1. [ c l s ] [cls] [cls]标记。学生网络首先生成一个 [ c l s ] [cls] [cls]标记,教师网络 θ t \theta_t θt 由学生网络 θ s \theta_s θs通过 指数移动平均 (EMA) 更新,教师网络通过最小化 学生网络和教师网络在 [ c l s ] [cls] [cls]上的交叉熵损失 将其知识蒸馏到学生网络

其中,
H
(
x
,
y
)
=
−
x
l
o
g
y
H(x, y) = −x log y
H(x,y)=−xlogy
2.在[patch] 标记上执行遮掩图像模型(MIM)。给定一个随机采样的掩码序列
m
∈
{
0
,
1
}
N
m\in\left\{0,1\right\}^N
m∈{0,1}N ,
m
i
m_i
mi = 1 的patches被替换为可学习的标记嵌入
e
[
M
A
S
K
]
e_{\left[MASK\right]}
e[MASK] ,从而损坏的图像可以表示为:
这个损坏的图像和原始未损坏的图像分别被送入学生和教师网络。
MIM 的目标是从损坏的图像中恢复遮掩标记,这相当于最小化学生网络和教师网络在 遮掩patches上 的交叉熵损失:
4.3 监督遮掩知识蒸馏

4.3.1 提取类标记
为了将标签信息纳入此类自监督框架,本文进一步允许从类内跨视图中提取有关 [cls] 标记的知识。
不是对单个图像 进行采样并生成两个视图,而是现在我们对两个图像 x,y进行采样并为每个图像生成一个视图。
x’ 和 y’ 分别表示为从图像 x 和 y 生成的增强视图,在 x’上应用额外的随机块遮掩,分别送入学生和教师网络。
在 [cls] 标记上的监督对比损失变为:
当 x, y 被采样为同一图像 (x = y) 时,相当于执行自监督遮掩知识蒸馏,即等式(1)。
在 x 和 y 表示不同图像 (
x
≠
y
x \neq y
x=y) ,相当于执行监督遮掩知识蒸馏
这样的设计有两个主要优点。
(1) 可高效实施。我们不需要有意地从同一类中采样图像对,我们只需要在mini-batch中查看图像,找到属于同一类的图像对,然后将我们的损失应用到等式(3)中。
(2) 与以前使用监督 或自监督对比损失的作品不同,我们的方法遵循 SSL 作品的最新趋势,并且避免了负样本的需要。
4.3.2 提取patch标记
除了全局 [cls] 标记的知识蒸馏之外,提出了跨类内图像的掩蔽patch标记重建的挑战性任务,以充分利用图像的局部细节进行训练。
本文基于这样的假设:对于类内图像,即使它们的语义信息在块级别上可能有很大差异,但至少应该存在一些共享相似语义的块。
所以,对于教师网络的每一个patch k(其相应的标记嵌入定义为
f
k
t
f_k^t
fkt ),从学生网络的遮掩视图中找到与其最相似的patch k+(其相应的标记嵌入定义为
f
k
+
t
f_{k+}^t
fk+t )。
由于没有任何patch级别的标注,使用余弦相似度在学生网络中的所有 [patch] 标记中找到 k 的最佳匹配标记:
patch级知识蒸馏损失现在变成:
其中
ω
k
+
\omega_{k+}
ωk+ 是一个标量,表示我们赋予每个损失项的权重。
本文的损失与 DenseCL 有一些相似之处。然而,差异也很明显:
(1) 本文的损失是将他们的自监督对比损失扩展到监督设置中。
(2) 本文进一步结合了 MIM ,并允许遮掩patch被匹配,这使任务更加困难,并导致更具语义意义的patch嵌入
5 Experiments
5.1 训练管道
分两个阶段训练我们的模型:自我监督预训练和监督训练。
在第一阶段,我们使用最近提出的 MIM 框架 [88] 进行自监督预训练。
自监督损失是方程(1)和方程(2)中 L[cls] 和
L
M
I
M
L_{MIM}
LMIM 的总和,没有缩放。
在第二阶段,我们继续使用方程(3)和方程(5)中的监督对比损失
L
[
c
l
s
]
L_{\left[cls\right]}
L[cls] 和
L
[
p
a
t
c
h
]
L_{\left[patch\right]}
L[patch]来训练预训练模型
其中 λ 控制这patch级损失的缩放比例。
5.2 实现细节
列了一张表,如图所示:
5.3 与SOTAs的比较



5.4 可视化


5.5 消融实验
 文章来源:https://www.toymoban.com/news/detail-735617.html
文章来源:https://www.toymoban.com/news/detail-735617.html
通过本文的监督对比损失设计,在类和patch级知识蒸馏,同时仍然享受不需要大batch size和负样本的好处。
统一了自监督学习和监督对比学习的学习目标,为未来的工作使用精心设计的课程学习策略。文章来源地址https://www.toymoban.com/news/detail-735617.html
到了这里,关于论文笔记|CVPR2023:Supervised Masked Knowledge Distillation for Few-Shot Transformers的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!