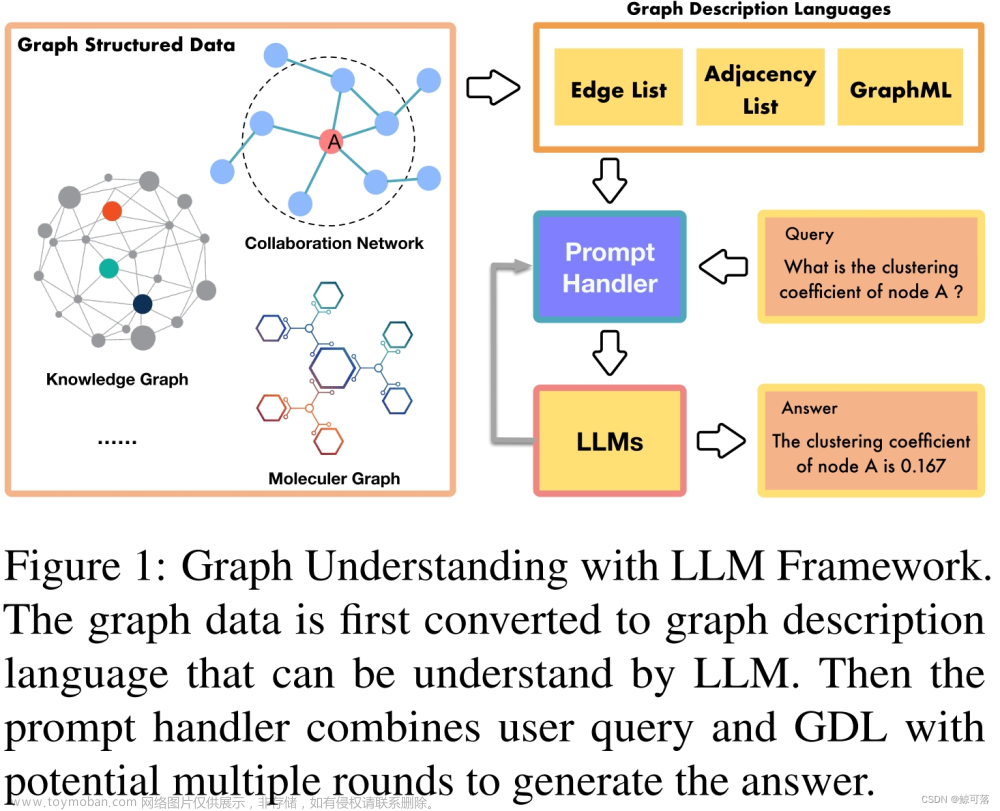
本文是LLM系列文章,针对《Data-Centric Financial Large Language Models》的翻译。
摘要
大型语言模型(LLM)有望用于自然语言任务,但在直接应用于金融等复杂领域时却举步维艰。LLM很难对所有相关信息进行推理和整合。我们提出了一种以数据为中心的方法,使LLM能够更好地处理财务任务。我们的关键见解是,与其一次用所有内容重载LLM,不如对数据进行预处理和预理解。我们使用基于多任务提示的微调创建了一个财务LLM(FLLM),以实现数据预处理和预理解。然而,每个任务的标记数据很少。为了克服手动注释成本,我们使用溯因增强推理(AAR)通过修改FLLM自己输出的伪标签来自动生成训练数据。实验表明,我们的以数据为中心的带有AAR的FLLM大大优于为原始文本设计的基线财务LLM,在财务分析和解释任务方面达到了最先进的水平。我们还开源了一个新的财务分析和解释基准。我们的方法为释放LLM在复杂现实世界领域的潜力提供了一条很有前途的途径。文章来源:https://www.toymoban.com/news/detail-735666.html
1 引言
2 背景
3 方法
4 实验
5 结论和未来工作
本文提出了一种基于FLLM的以数据为中心的方法,以提高LLM在财务分析任务中的能力。为了克服标记数据的稀缺性,他们采用溯因增强推理来自动生成训练数据。实验表明,他们以数据为中心的金融LLM和溯因增强推理大大优于基线LLM,实现了最先进的金融分析和解释基准。以数据为中心的方法为释放LLM在复杂现实世界领域的潜力提供了一个很有前途的方向。采用新的财务分析和解释基准也是一项宝贵的贡献。此外,未来工作的一个有趣方向是将以数据为中心的方法与其他方法相结合,如金融文本的提示和自我监督预训练。整合财务报告、财报电话和股价等多模式数据也可以实现更细致的财务分析。文章来源地址https://www.toymoban.com/news/detail-735666.html
到了这里,关于Data-Centric Financial Large Language Models的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!