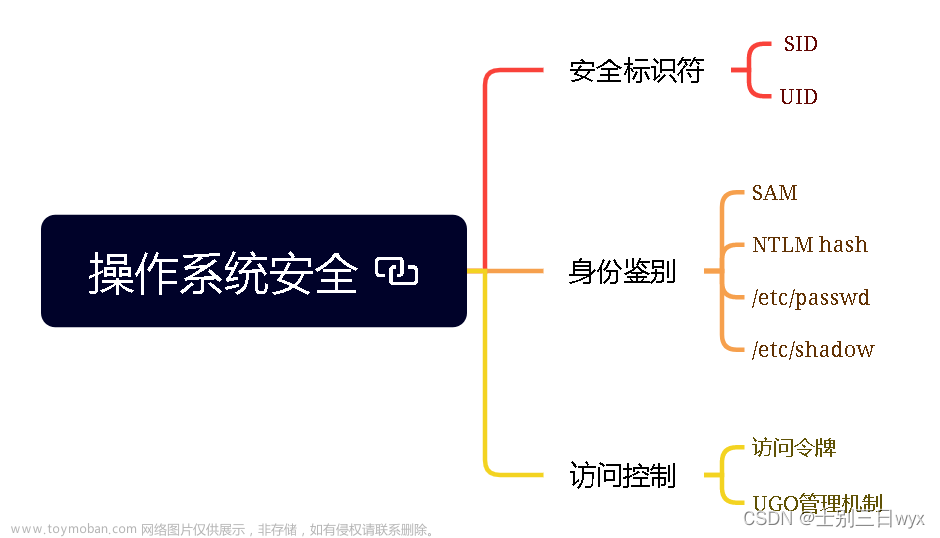
1. 主体的标志
在计算机安全领域,访问发起者被称为主体,访问动作就是具体的操作,被访问者被称为客体。比如,进程A 读文件 a,进程 A 是主体,读是操作,文件 a 是客体。Linux的主体只能是进程;操作只有读、写或者执行;客体可以是目录和文件{包括管道、设备、IPC(进程间通信)、socket(套接字)、key(密钥)}。备注:目录的执行是进入,文件的执行是运行,只有普通文件可以执行,管道等文件是不可以执行的。
自主访问控制的自主是指使用计算机的人可以决定访问策略,比如规定某文件只能读不能写,制造出一种“只读”文件,防止文件内容被不小心更改。再比如,张三有个 mp3 文件,规定李四可以读,但赵五不可以读。Linux是通过uid和gid标记一个进程是谁在操作的,他们没有直接记录在task_struct结构体中,而是记录在task_struct结构体中的ptracer_cred、real_cred、cred中:
struct task_struct {
...
/* Process credentials: */
/* Tracer's credentials at attach: *///调试使用的主体
const struct cred __rcu *ptracer_cred;
/* Objective and real subjective task credentials (COW): */
const struct cred __rcu *real_cred;
/* Effective (overridable) subjective task credentials (COW): */
const struct cred __rcu *cred;
...
}
从上面代码可见,进程的控制结构中有三个cred :
- ptracer_cred适用于调试的,一般是该进程被tracer控制着,记录tracer进程的身份和权限信息;
- real_cred存储的是进程初始时的身份和权限信息,为了安全性,任何时候都不能修改real_cred结构体;
- cred,存储的是进程当前的身份和权限信息,在大多数情况下,和real_cred的值是相同的,在某些情况下内核代码会修改当前进程的cred,以获得某种访问权限,待执行完任务后再将主体凭证改回原值。
Linux内核中的cred结构体是用来存储进程的安全上下文,即用户的身份信息和权限信息。cred数据结构存储了进程的UID、GID、有效UID等信息,还包括一些标志位,例如CAP_SYS_ADMIN等权限控制标志。在Linux操作系统中,每个进程都有自己的cred结构体,用于描述它的身份和权限。当一个进程进行系统调用或在内核中执行操作时,内核会在cred结构体中查找相应的权限来确定该进程是否有足够的权限执行该操作。这种方式可以帮助Linux操作系统实现细粒度的安全控制,例如限制用户对关键系统资源的访问。
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
* keys to */
struct key *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
/* RCU deletion */
union {
int non_rcu; /* Can we skip RCU deletion? */
struct rcu_head rcu; /* RCU deletion hook */
};
} __randomize_layout;
进程凭证中多个 uid 机制的引入是为了在运行时暂时授权,各个uid和gid成员解析:
- uid和gid:进程的真实用户ID和组ID,在资源统计和资源分配中使用,比如限制某用户拥有的进程数量。
- euid和egid:进程的有效用户ID和组ID,在内核做特权判断时使用它。它的引入和提升权限有关,内核在做 ipc(进程间通信)和 key(密钥)的访问控制时也使用 euid。
- suid和sgid:进程的超级用户ID和组ID,跟 euid 和特权有关,当euid需要为0的时候,进程就具有了超级用户的权限,为了让进程不要一直具有全部特权,总能为所欲为,系统的设计者引入了 suid,用于暂存 euid 的值。euid 为 0 时做需要特权的操作,执行完操作,将 0 赋予suid,euid 恢复为非 0 值,做普通的不需要特权的操作,需要特权时再将 suid 的值传给 euid。
- fsuid和fsgid:进程的文件系统用户ID和组ID,用于在文件系统相关的访问控制中判断操作许可。比如进程的uid 是 1000,fsuid 是 1001,进程就具备了 1001 用户的访问文件的权限,但是仅仅是访问,但不能删除。
内核提供了 proc 文件/proc/[pid]/status 来查看相关的信息。
2. 客体的标记
Linux中进程有多个 uid 和多个 gid,但是文件只有一个 uid 和一个 gid,分别称为属主和属组。它们的含义是标记文件属于哪一个用户,属于哪一个用户组。文件的标记除了有一个 uid 和一个 gid,还有操作权限的允许位和acl权限,这些都放在内核中 inode 结构体:
struct inode {
umode_t i_mode;//文件的访问权限
unsigned short i_opflags;//文件操作的状态
kuid_t i_uid;//使用者id
kgid_t i_gid;//使用组id
unsigned int i_flags;//文件系统标志
#ifdef CONFIG_FS_POSIX_ACL
//acl访问控制相关属性
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
#endif
const struct inode_operations *i_op;//索引节点操作方法函数
struct super_block *i_sb;//索引节点所属超级块
struct address_space *i_mapping;//相关地址映射(文件内容映射)
#ifdef CONFIG_SECURITY
void *i_security;//安全模块使用
#endif
...
} __randomize_layout;
上面是自主访问控制用到的文件属性,每一个成员的含义可以看注释。
2.1 允许位
Linux采用了一种相对简单的方式来管理操作许可,以文件为例:
- 在每个文件的属性中存储文件所属的用户(属主)和所属的用户组(属组)。
- 根据用户的属主和属组将所有用户分为三类:同主用户、同组用户、其他用户。
- 在每个文件的属性中为三类用户分别存储访问许可。
内核代码采用一个 bit 来表示一个操作许可,对于文件就需要 9 个 bit 来表示文件的操作许可:同主读、同主写、同主执行、同组读、同组写、同组执行、其他读、其他写、其他执行。这些表示操作许可的比特位合在一起就成为 permission bits,即允许位。其他的客体也类似,只有IPC和秘钥是例外。IPC 只有两个操作许可,所以只需要 6 个比特位。密钥的操作许可是 6 个,它的允许位需要 18 个比特位。
2.2 设置位
Linux为文件分配了九个允许位,也为文件分配了三个设置位,:set-user-bit(又称 set-user-id 或 setuid)、set-group-bit
(又称 set-group-id 或 setgid)、set-other-bit(又称 sticky bit);对应三类用户(同主、同组、其他)。引入这3个设置位更深层的目的是特权提升!
2.2.1 setuid
setuid 位仅对二进制程序文件有效。进程调用 execve 执行了一个允许位 setuid 为 1 的文件后,进程的 euid,还有Linux 特有的 fsuid,被改变为所执行文件的属主 id。效果就是进程执行文件不仅将文件的内容读入进程的代码区内存和数据区内存,还将文件属性中的部分数据读入进程凭证。
如果普通用户需要做一些特权操作,那么正规的做法是请求管理员代劳。但是,有的特权操作使用频繁,又不会对系统带来危害,比如探知网络实体存在的 ping 命令,这种情况下总是请管理员做 ping 操作实在没有必要,运行 ping 的进程具有特权就可以了。setuid的作用就是让运行 ping 的进程具有特权。
实现流程:1.ping 文件的属主是 root;2.ping 文件的 setuid 位被置位;3.ping 文件的允许位设置为所有人都可以执行。这样子,任何进程运行ping命令都可以运行成功。如果setuid 位不被置位,运行则会导致因为没有root权限而运行失败。
修改和查看该权限位例子:
jian@ubuntu:/$ ls -l /usr/sbin/useradd
-rwxr-xr-x 1 root root 147160 Nov 29 19:53 /usr/sbin/useradd
jian@ubuntu:/$ sudo chmod u+s /usr/sbin/useradd
[sudo] password for jian:
jian@ubuntu:/$ useradd jkl
jian@ubuntu:/$ ls -l /usr/sbin/useradd
-rwsr-xr-x 1 root root 147160 Nov 29 19:53 /usr/sbin/useradd
我们可以看到user列的操作位从x变成了s。
2.2.2 setgid
setgid位的作用是,在此目录下创建的文件和子目录的属组自动初始化为目录的属组。将目录设置为SGID后,如果在该目录下创建文件,都将与该目录的所属组保持一致。当目录设置了SGID位之后,任何用户或进程在访问该文件或目录时,都将具有该文件或目录所属的组的ID,而不是访问者自己的组ID。例如在一个目录中设置SGID位可以使得进入该目录的人员都拥有该目录所属组的访问权限。在这种情况下,即使用户拥有自己默认组之外的其他组,他们也能够访问该目录,并获得该目录所属组的权限。
修改和查看该权限位例子:
jian@ubuntu:~/share/note/tt$ ls -l
drwxrwxr-x 2 jian jian 4096 Mar 30 14:58 a
jian@ubuntu:~/share/note/tt$ chmod g+s a
jian@ubuntu:~/share/note/tt$ ls -l
drwxrwsr-x 2 jian jian 4096 Mar 30 14:58 a
我们可以看到group列的操作位从x变成了s。
2.2.3 sticky
sticky 位仅对目录有效,他的作用是在其下的文件/子目录只能被该文件/子目录的属主删除。普通用户对该目录拥有w和x权限,即普通用户可以在此目录中拥有写入权限,如果没有sticky 位,那么普通用户拥有w权限,就可以删除此目录下的所有文件,包括其他用户建立的文件。但是一旦被赋予了sticky 位,除了root可以删除所有文件,普通用户就算有w权限也只能删除自己建立的文件,而不能删除其他用户建立的文件。典型的用法是将系统临时目录/tmp 的 sticky bit 置位,这样子所有用户都可以读取到tmp下的文件,却只有root或者文件属主有权限删除文件。
总结就是:
- 带有sticky 位权限的目录下的所有文件,谁都可以读、写 ;
- 带有sticky 位权限的目录下的文件只有属主能删除自己的文件,其他用户无法删除;
- 带有sticky 位权限的目录,只有root能删除。
修改和查看该权限位例子:
jian@ubuntu:~/share/note/tt$ ls -l
total 4
drwxrwsr-x 2 jian jian 4096 Mar 30 14:58 a
jian@ubuntu:~/share/note/tt$ chmod o+t a
jian@ubuntu:~/share/note/tt$ ls -l
total 4
drwxrwsr-t 2 jian jian 4096 Mar 30 14:58 a
我们可以看到other列的操作位从x变成了t。
3. ACL(访问控制列表)
从某个文件的角度看,Linux通过文件属性中的属主和属组,把系统中的进程分为三类:同主、同组、其他。UNIX 通过文件属性中允许位的九个比特,使这三类进程分别拥有自己的操作许可。Linux还可以通过 ACL访问控制列表动态添加和删除某主或者某组的进程的操作权限。
访问控制列表存储在文件的扩展属性之中。在支持扩展属性的文件系统中,inode 和扩展属性在存储设备上是分开存储的,在 inode 中保留一个关联到扩展属性的索引。扩展属性本身则被实现为一个数组,数组项又分为属性名和属性值两部分。属性名是一个字符串,属性值可以是任意类型。属性名字符串本身也是有格式的,它由“.”分割为若干域,比如“system.posix_acl_access”。其中第一个域必须是下列四个之一:user、system、trusted、security,表示它们分别用于应用、系统、可信和安全。和访问控制列表相关的扩展属性有两个,属性名分别是 system.posix_acl_access 和system.posix_acl_default。
前面我们看到inode结构体的成员i_acl和i_default_acl是指向struct posix_acl的指针,我们看看struct posix_acl吧:
struct posix_acl {
refcount_t a_refcount;
struct rcu_head a_rcu;
unsigned int a_count;//entry的计数
struct posix_acl_entry a_entries[];//entry存放处
};
struct posix_acl_entry {
short e_tag;
unsigned short e_perm;//权限位
union {//ID的联合体
kuid_t e_uid;
kgid_t e_gid;
};
};
访问控制列表被实现为一个零长的数组。ACL entry 有三个重要成员:tag、id、permission-bits。我们先看tag的值可以有哪些:
| tag | 含义 |
|---|---|
| ACL_USER_OBJ | ACL_USER_OBJ 规定文件属主的操作许可。 |
| ACL_GROUP_OBJ | ACL_GROUP_OBJ 规定文件属组的操作许可。 |
| ACL_USER | ACL_USER 为某一个用户规定操作许可,id 存储的是用户id,当进程fsuid 与该项 id 相同时,进程对文件的操作许可由此项 ACL entry中的 permission-bits 规定 |
| ACL_GROUP | ACL_GROUP 为某一个组规定操作许可,id 存储的是组 id,当进程 fsgid 与该项 id 相同时,进程对文件的操作许可由此项 ACL entry中的 permission-bits 规定 |
| ACL_OTHER | 当一个进程的 fsuid 和任何一项 ACL_USER 中规定的 id 都不匹配,fsgid 和任何一个ACL_GROUP 中规定的 id 都不匹配,fsuid 不等于文件的属主,且 fsgid 不等于文件的属组,此时进程对文件的操作许可由此项中的 permission-bits 规定。 |
| ACL_MASK | ACL_MASK 的引入是为了给规定的部分操作许可设置一个上限。进程从 ACL_USER、ACL_GROUP、ACL_GROUP_OBJ 项获得的操作许可如果不出现在ACL_MASK 项的permission-bits 中,该操作许可会被清除。 |
ACL 使管理的粒度变细,相应地,控制逻辑也变复杂了:
- 如果进程的 fsuid 等于文件的属主,则判断进程申请的操作是否在 ACL_USER_OBJ项的 permission-bits 中,若是,返回允许,否则返回拒绝。
- 如果进程的 fsuid 等于文件的某一项 ACL_USER 中规定的 id,则判断进程申请的操作是否在该项的 permission-bits 和 ACL_MASK 项的 permission-bits 的交集中,若是,返回允许,否则返回拒绝。
- 如果进程的 fsgid 或补充组中的任何一个 gid 等于文件的属组或某一项 ACL_GROUP中规定的 id,则判断进程申请的操作是否在该项的 permission-bits 和ACL_MASK 项的 permission-bits 的交集中,若是,返回允许,否则返回拒绝。
- 如果进程申请的操作出现在 ACL_OTHER 项的 permission-bits 中,返回允许,否则返回拒绝。
ACL和允许位的关系:
允许位分为三部分:三个比特位表示同主进程的操作许可,三个比特位表示同组进程的操作许可,三个比特位表示其他进程的操作许可。这三部分很自然地和 ACL 中 ACL_USER_OBJ、ACL_GROUP_OBJ、ACL_OTHER 对应。改允许位,ACL 跟着变动;改 ACL,允许位跟着变动。属组部分的允许位有一个例外:当 ACCESS 型 ACL 有 ACL_MASK 项存在时,属组部分允许位和 ACL_MASK 项的 permission-bits 对应。反之,当 ACCESS 型 ACL 没有 ACL_MASK项存在时,属组部分允许位和 ACL_GROUP_OBJ 项的 permission-bits 对应。文章来源:https://www.toymoban.com/news/detail-735687.html
4. 能力控制
Linux 内核的能力机制是为了解决传统的 UNIX 内核的特权判定过于简单而产生的。Linux内核的能力机制将传统的特权进行了分割,使得最小特权原则有可能实现。这是一个进步。但是,由于能力机制的复杂和能力机制与原有基于用户标识机制的不兼容,能力机制没有被广泛
使用。而且由于能力机制的后向兼容可以做到让旧有的应用不需修改即可使用,广大的应用开发者甚至根本不知道 Linux 内核能力机制的存在。我也是无意中看到,也不知道怎么用,但是还是在这里占个位吧。具体的能力可以看 include/uapi/linux/capability.h文件。文章来源地址https://www.toymoban.com/news/detail-735687.html
到了这里,关于linux安全-自主访问控制的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!