上一节,我们用docker-compose搭建了一个RabbitMQ集群,这一节我们来分析一下集群的原理
一、基础概念
1.1 元数据
前面我们有介绍到 RabbitMQ 内部有各种基础构件,包括队列、交换器、绑定、虚拟主机等,他们组成了 AMQP 协议消息通信的基础,而这些构件以元数据的形式存在,它始终记录在 RabbitMQ 内部,它们分别是:
- 队列元数据:队列名称和它们的属性
- 交换器元数据:交换器名称、类型和属性
- 绑定元数据:一张简单的表格展示了如何将消息路由到队列
- vhost 元数据:为 vhost 内的队列、交换器和绑定提供命名空间和安全属性
PS:元数据,指的是包括队列名字属性、交换机的类型名字属性、绑定信息、vhost等基础信息,不包括队列中的消息数据。
1.2 RabbitMQ 存储数据有两种方案:
- 内存模式:这种模式会将数据存储在内存当中,如果服务器突然宕机重启之后,那么附加在该节点上的队列和其关联的绑定都会丢失,并且消费者可以重新连接集群并重新创建队列;
- 磁盘模式:这种模式会将数据存储磁盘当中,如果服务器突然宕机重启,数据会自动恢复,该队列又可以进行传输数据了,并且在恢复故障磁盘节点之前,不能在其它节点上让消费者重新连到集群并重新创建队列,如果消费者继续在其它节点上声明该队列,会得到一个 404 NOT_FOUND 错误,这样确保了当故障节点恢复后加入集群,该节点上的队列消息不会丢失,也避免了队列会在一个节点以上出现冗余的问题。
在单节点 RabbitMQ 上,仅允许该节点是磁盘节点,这样确保了节点发生故障或重启节点之后,所有关于系统的配置与元数据信息都会从磁盘上恢复。
而在 RabbitMQ 集群上,至少有一个磁盘节点,也就是在集群环境中需要添加 2 台及以上的磁盘节点,这样其中一台发生故障了,集群仍然可以保持运行。其它节点均设置为内存节点,这样会让队列和交换器声明之类的操作会更加快速,元数据同步也会更加高效。
二、集群节点类型
在单个节点上,RabbitMQ 存储数据有两种方案:
- 内存模式:这种模式会将数据存储在内存当中,如果服务器突然宕机重启之后,那么附加在该节点上的队列和其关联的绑定都会丢失,并且消费者可以重新连接集群并重新创建队列;
- 磁盘模式:这种模式会将数据存储磁盘当中,如果服务器突然宕机重启,数据会自动恢复,该队列又可以进行传输数据了,并且在恢复故障磁盘节点之前,不能在其它节点上让消费者重新连到集群并重新创建队列,如果消费者继续在其它节点上声明该队列,会得到一个 404 NOT_FOUND 错误,这样确保了当故障节点恢复后加入集群,该节点上的队列消息不会丢失,也避免了队列会在一个节点以上出现冗余的问题。
如下图所示,三个节点的集群,有两个磁盘模式,一个内存模式
在集群中的每个节点,要么是内存节点,要么是磁盘节点,如果是内存节点,会将所有的元数据信息仅存储到内存中,而磁盘节点则不仅会将所有元数据存储到内存上, 还会将其持久化到磁盘。
在单节点 RabbitMQ 上,仅允许该节点是磁盘节点,这样确保了节点发生故障或重启节点之后,所有关于系统的配置与元数据信息都会从磁盘上恢复。
而在 RabbitMQ 集群上,至少有一个磁盘节点,也就是在集群环境中需要添加 2 台及以上的磁盘节点,这样其中一台发生故障了,集群仍然可以保持运行。其它节点均设置为内存节点,这样会让队列和交换器声明之类的操作会更加快速,元数据同步也会更加高效。
三、集群的几种模式
集群主要有两种模式主备模式(Warren)和镜像模式(Mirror)
下面分别对两种模式进行说明
主备模式(Warren)
1、基本特征
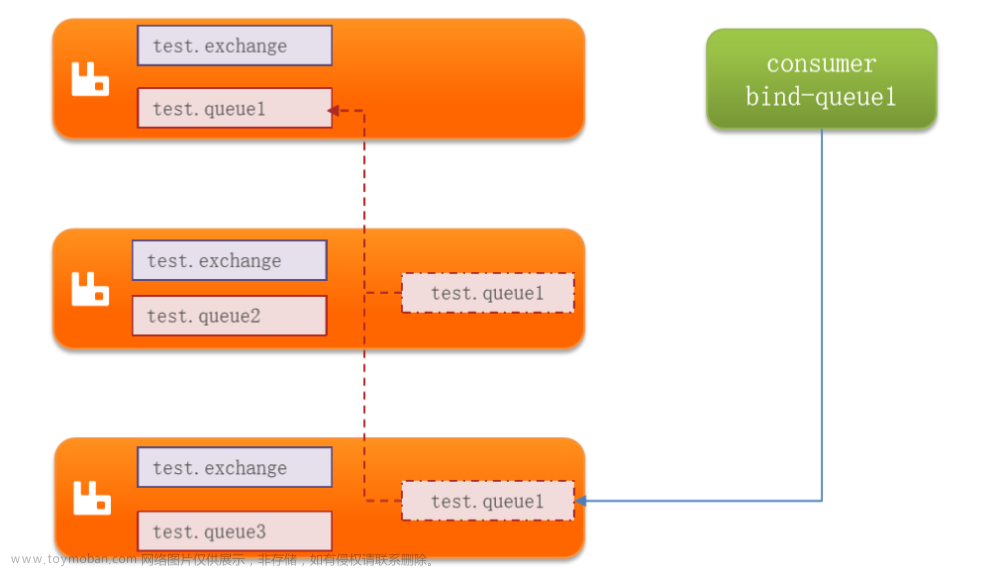
- 交换机和队列的元数据存在于所有的节点上
- queue队列中的完整数据只存在于创建该队列的节点上
- 其他节点只保存队列的元数据信息以及指向当前队列的owner node的指针

2、数据消费
进行数据消费时随机连接到一个节点,当队列不是当前节点创建的时候,需要有一个从创建队列的实例拉取队列数据的开销。此外由于需要固定从单实例获取数据,因此会出现单实例的瓶颈。
3、优点:
可以由多个节点消费单个队列的数据,提高了吞吐量
4、缺点:
节点实例需要拉取数据,因此集群内部存在大量的数据传输可用性保障低,一旦创建队列的节点宕机,只有等到该节点恢复其他节点才能继续消费消息
镜像模式(Mirror)
1、基本特征
创建的queue,不论是元数据还是完整数据都会在每一个节点上保存一份
向queue中写消息时,都会自动同步到每一个节点上
2、优点:
- 保障了集群的高可用
- 配置方便,只需要在后台配置相应的策略,就可以将指定数据同步到指定的节点或者全部节点
3、缺点:
- 性能开销较大,网络带宽压力和消耗很严重,所以镜像队列的吞吐量会低于主备模式
- 无法线性扩展,例如单个queue的数据量很大,每台机器都要存储同样大量的数据
集群实操
集群的部署
下面的链接是最快最简单的一种集群部署方法
3分钟部署一个RabbitMQ集群
由于是docker部署,所以我任意找一个节点,进入集群节点
先docker ps查看运行的进程,然后根据容器id,进入容器
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4d75d7be9cf5 bitnami/rabbitmq "/opt/bitnami/script…" 7 minutes ago Up 7 minutes 4369/tcp, 5551-5552/tcp, 5671-5672/tcp, 15671-15672/tcp, 25672/tcp mycompose-queue-disc1-1
b4f7618ffdd4 bitnami/rabbitmq "/opt/bitnami/script…" 7 minutes ago Up 7 minutes 4369/tcp, 5551-5552/tcp, 5671-5672/tcp, 15671/tcp, 25672/tcp, 0.0.0.0:15672->15672/tcp, :::15672->15672/tcp mycompose-stats-1
f3a97e8d74de bitnami/rabbitmq "/opt/bitnami/script…" 7 minutes ago Up 7 minutes 4369/tcp, 5551-5552/tcp, 5671-5672/tcp, 15671-15672/tcp, 25672/tcp mycompose-queue-ram1-1
[root@localhost ~]# docker exec -it 4d /bin/bash
查看集群状态
I have no name!@4d75d7be9cf5:/$ rabbitmqctl cluster_status
Cluster status of node rabbit@queue-disc1 ...
Basics
#下面是主节点名称
Cluster name: rabbit@4d75d7be9cf5
#下面是磁盘节点,有两个
Disk Nodes
rabbit@queue-disc1
rabbit@stats
#下面是内存节点,有一个
RAM Nodes
rabbit@queue-ram1
#下面表示有三个节点在运行
Running Nodes
rabbit@queue-disc1
rabbit@queue-ram1
rabbit@stats
# 下面是版本号
Versions
rabbit@queue-disc1: RabbitMQ 3.9.11 on Erlang 24.2
rabbit@queue-ram1: RabbitMQ 3.9.11 on Erlang 24.2
rabbit@stats: RabbitMQ 3.9.11 on Erlang 24.2
Maintenance status
Node: rabbit@queue-disc1, status: not under maintenance
Node: rabbit@queue-ram1, status: not under maintenance
Node: rabbit@stats, status: not under maintenance
Alarms
(none)
Network Partitions
(none)
Listeners
Node: rabbit@queue-disc1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@queue-disc1, interface: [::], port: 15692, protocol: http/prometheus, purpose: Prometheus exporter API over HTTP
Node: rabbit@queue-disc1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@queue-ram1, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@queue-ram1, interface: [::], port: 15692, protocol: http/prometheus, purpose: Prometheus exporter API over HTTP
Node: rabbit@queue-ram1, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Node: rabbit@stats, interface: [::], port: 15672, protocol: http, purpose: HTTP API
Node: rabbit@stats, interface: [::], port: 25672, protocol: clustering, purpose: inter-node and CLI tool communication
Node: rabbit@stats, interface: [::], port: 5672, protocol: amqp, purpose: AMQP 0-9-1 and AMQP 1.0
Feature flags
Flag: drop_unroutable_metric, state: enabled
Flag: empty_basic_get_metric, state: enabled
Flag: implicit_default_bindings, state: enabled
Flag: maintenance_mode_status, state: enabled
Flag: quorum_queue, state: enabled
Flag: stream_queue, state: enabled
Flag: user_limits, state: enabled
Flag: virtual_host_metadata, state: enabled
从上面可以看到,有三个节点,其中有两个磁盘节点,一个内存节点
剔除单个节点
上面有三个节点:rabbit@queue-disc1,rabbit@queue-ram1,rabbit@stats。我们剔除rabbit@queue-disc1
进入rabbit@queue-disc1所在的容器,并执行rabbitmqctl stop_app
[root@localhost ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b31e921dd5e7 bitnami/rabbitmq "/opt/bitnami/script…" 4 hours ago Up 2 hours 4369/tcp, 5551-5552/tcp, 5671/tcp, 15671-15672/tcp, 25672/tcp, 0.0.0.0:5612->5672/tcp, :::5612->5672/tcp mycompose-queue-disc1-1
ed73deb9f1c5 bitnami/rabbitmq "/opt/bitnami/script…" 4 hours ago Up 2 hours 4369/tcp, 5551-5552/tcp, 5671/tcp, 15671/tcp, 25672/tcp, 0.0.0.0:15672->15672/tcp, :::15672->15672/tcp, 0.0.0.0:5602->5672/tcp, :::5602->5672/tcp mycompose-stats-1
[root@localhost ~]# docker exec -it b3 /bin/bash
I have no name!@b31e921dd5e7:/$ rabbitmqctl stop_app
Stopping rabbit application on node rabbit@queue-disc1 ...
进入rabbit@stats节点,然后执行下面的命令
I have no name!@ed73deb9f1c5:/$ rabbitmqctl forget_cluster_node rabbit@queue-disc1
Removing node rabbit@queue-disc1 from the cluster
可以看到,现在只有两个节点了,其中有一个内存节点,由于某些原因,没有启动起来。先暂时不用管。
节点加入集群
刚才的rabbit@queue-disc1被我们剔除了集群,现在我们又尝试把该节点重新加入集群
rabbitmqctl join_cluster rabbit@stats 加入刚才的集群,并重启一下
I have no name!@b31e921dd5e7:/$ rabbitmqctl join_cluster rabbit@stats
Clustering node rabbit@queue-disc1 with rabbit@stats
I have no name!@b31e921dd5e7:~$ rabbitmqctl start_app
Starting node rabbit@queue-disc1 ...

rabbit@queue-disc1又回来了
改变节点类型
将rabbit@queue-disc1节点改变成内存节点,如下所示,先停止应用,再用change_cluster_node_type命令改变为ram类型,最后重启文章来源:https://www.toymoban.com/news/detail-735757.html
I have no name!@b31e921dd5e7:~$ rabbitmqctl stop_app
Stopping rabbit application on node rabbit@queue-disc1 ...
I have no name!@b31e921dd5e7:~$ rabbitmqctl change_cluster_node_type ram
Turning rabbit@queue-disc1 into a ram node
I have no name!@b31e921dd5e7:~$ rabbitmqctl start_app

可以看到节点类型已变成ram了文章来源地址https://www.toymoban.com/news/detail-735757.html
到了这里,关于【RabbitMQ 实战】08 集群原理剖析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!