▼最近直播超级多,预约保你有收获
近期直播:《基于 LLM 大模型的向量数据库企业级应用实践》
1—
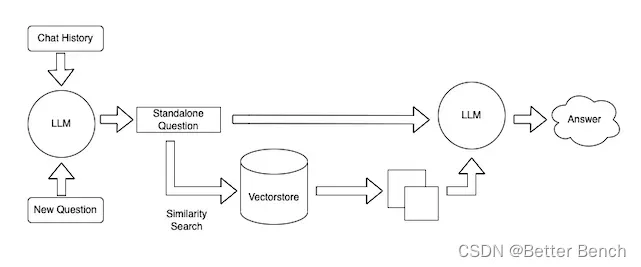
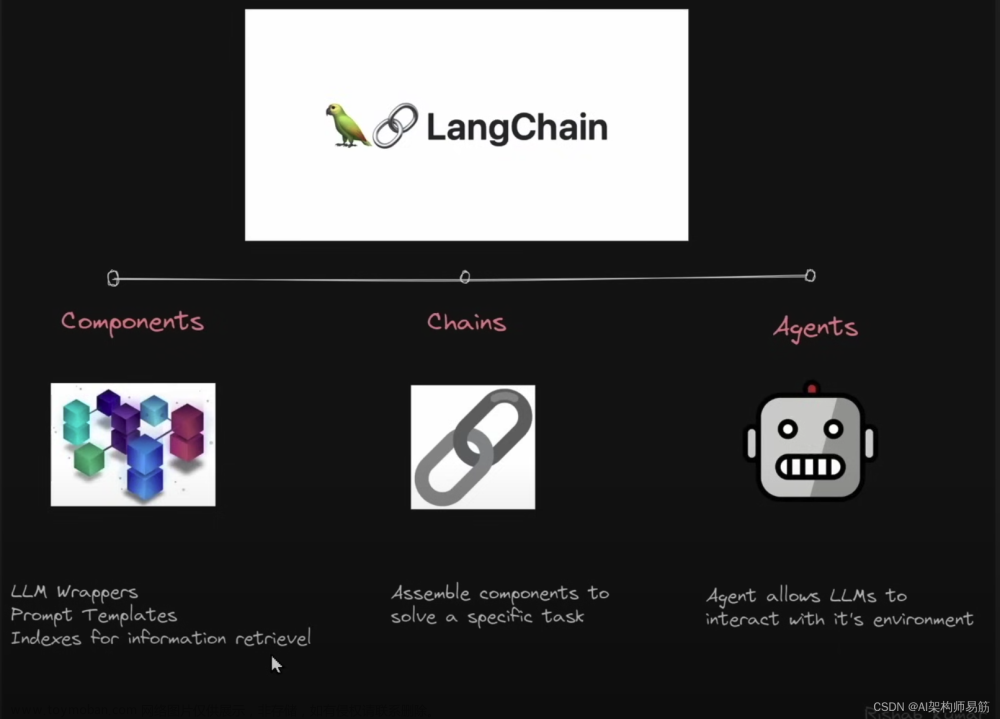
LangChain 是什么?
众所周知 OpenAI 的 API 无法联网的,所以如果只使用自己的功能实现联网搜索并给出回答、总结 PDF 文档、基于某个 Youtube 视频进行问答等等的功能肯定是无法实现的。
数据感知:将 LLM 模型链接到不同的数据源,比如:ChatGPT 访问 PDF 等;
代理:允许与 LLM 模型进行交互。
第一、支持 LLM 调用
-
支持多种模型接口调用:OpenAI、Hugging Face、AzureOpenAI ...
支持多种方式实现缓存记录:In-Mem(内存)、SQLite、Redis、SQL ...
支持流模式(类型打字机的效果)
第二、支持 Prompt 管理
-
支持多种自定义模板
第三、支持索引
-
支持文档切割
支持 token 向量化
支持向量数据库
第四、支持 Chain(链)
-
链允许我们将多个组件组合在一起,以创建一个单一的、连贯的应用程序。比如:我们可以创建一个链,该链接受用户输入,使用提示模板对其进行格式化,然后将格式化的响应传递给 LLM。
第五、文档加载器(Document Loader)
顾名思义,这个就是从指定源进行加载数据的, 比如:
-
文件夹 DirectoryLoader
Azure 存储 AzureBlobStorageContainerLoader
CSV文件 CSVLoader
印象笔记 EverNoteLoader
Google网盘 GoogleDriveLoader
任意的网页 UnstructuredHTMLLoader
PDF PyPDFLoader
S3 S3DirectoryLoader/S3FileLoader
Youtube YoutubeLoader 等官方文档地址:https://python.langchain.com/en/latest/modules/indexes/document_loaders.html
代码实践如下:

— 2 —
文本切割(Text Splitters)
当您想要处理长文本时,有必要将该文本拆分为块。听起来很简单,但这里有很多潜在的复杂性。在理想情况下,我们希望将语义相关的文本片段放在一起。“语义相关”的含义可能取决于文本的类型。文本切割器的工作方式:
-
将文本拆分为语义有意义的小块(通常是句子)
开始将这些小块组合成一个较大的块,直到达到一定的大小(由某个函数测量)
达到一定大小后,将该块设置为自己的文本段,然后开始创建一个具有一些重叠的新文本块(以保持块之间的上下文)
默认推荐的文本拆分器是 RecursiveCharacterTextSplitter。此文本拆分器采用字符列表。它尝试基于第一个字符的拆分来创建块,但如果任何块太大,它就会移动到下一个字符,依此类推。默认情况下,它尝试拆分的字符为 ["\n\n", "\n", " ", ""]。
文本切割代码如下:

—3 —
向量化(向量数据库)
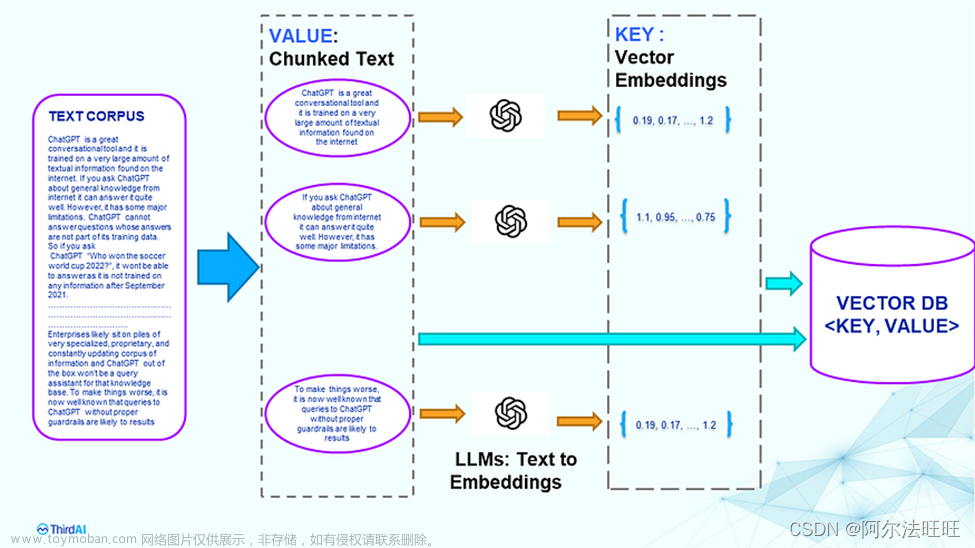
第一、为什么 LLM 需要将文本内容向量化
计算机最擅长处理的就是数字,因此我们需要将文本(如单词或者句子)转化为数字,或者更具体地说,转化为向量。向量是一种数学对象,可以看作是一个有序的数字列表。这种将文本转化为向量的过程就叫做向量化。
第二、什么是欧式距离
把它想象成在多维空间中两点之间的直线距离。比如在二维空间(也就是平面)上,两点之间的欧氏距离就是我们平时说的直线距离。在三维空间中,也就是我们生活的物理世界中,两点之间的欧氏距离就是我们通常意义上的空间直线距离。这个概念可以扩展到更高的维度。
第三、欧式距离在文本分析中的作用
在文本分析中,欧氏距离常常被用来衡量两段文本(或者说,两个向量)的相似度。如果两个向量之间的欧氏距离小,那么这两段文本就被认为是相似的;反之,如果欧氏距离大,那么这两段文本就被认为是不相似的。
第四、向量数据库
顾名思义,专门设计用于高效存储和检索向量数据,向量数据库检索主要基于向量之间的距离或相似度。常用向量数据库有:
-
Chroma(开源本地文件向量数据库)
Milvus(开源分布式高性能数据库)
Pinecone(商业化分布式高性能数据库)
代码实践如下:

— 4 —
链(Chain)
可以把 Chain 理解为任务。一个 Chain 就是一个任务,当然也可以像链条一样,一个一个的执行多个链,常用 Chain 如下:
-
LLMChain(适用于各种 LLM 链)
load_qa_chain( QA 问答)
ConversationalRetrievalChain(使用聊天记录在文档上进行聊天)
— 5—
免费超干货 LLM 大模型直播
为了帮助同学们掌握好 LLM 大模型的向量数据库企业级应用实战,明晚8点,我和陈东老师会开一场直播和同学们深度聊聊大模型的向量化、向量数据库的应用实战,请同学点击下方按钮预约直播,咱们明晚8点不见不散哦~~
近期直播:《基于 LLM 大模型的向量数据库企业级应用实践》文章来源:https://www.toymoban.com/news/detail-735908.html
END文章来源地址https://www.toymoban.com/news/detail-735908.html
到了这里,关于基于Langchain+向量数据库+ChatGPT构建企业级知识库的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![构建搜索引擎,而非向量数据库(Vector DB) [译]](https://imgs.yssmx.com/Uploads/2024/02/761312-1.png)