本文将从原理上详细解释KMP算法中的next数组以及nextval数组,尽量让大家明白它们到底在记录什么,为什么要这样算。以及现在普遍的KMP算法实现当中的next数组与前两者有何不同。篇幅较长,但尽量讲清楚。
next数组
next数组到底在记录什么?
虽然数据结构中对next数组有定义,但并不易于理解,因此我个人对next数组进行了一个简单解释:
next数组指示了当前模式串在该位置匹配冲突(即失配,个人习惯称冲突)时,应该将模式串的哪一位与此位对齐。
这里为刚学习KMP的朋友解释一下,KMP算法进行字符串匹配时,被检索的串称为“文本串”,要检索的目标串称为“模式串”。next数组与nextval数组的求解只与模式串有关。
举个例子:
假设需要在字符串 “abaabbcabaabcac” 中查找是否存在字符串 “abaabcac”,那么 "abaabbcabaabcac"就是文本串,"abaabcac"就是模式串。
这里其它的许多详解中会直接告诉你,next数组的第一位是0,第二位是1,然后从第三位开始继续算什么的,但很少看到有解释为什么第一位一定是0,第二位一定是1。
为了解释这个问题,我们首先要搞清楚模式串的“位”是什么样的。
对“abaabcac”来说,第一个字符a就是第一位,不要受一些编程语言思维的影响认为这是第0位。
| 位数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 模式串 | a | b | a | a | b | c | a | c |
但是为了便于理解,我们假想模式串的最前面还有一个空白字符位,称为第0位,即:
| 位数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| 模式串 | a | b | a | a | b | c | a | c |
现在,我们再来对照前面给出的定义:
next数组指示了当前模式串在该位置匹配冲突时,应该将模式串的哪一位与此位对齐。
是不是就理解为什么第一位一定是0,第二位一定是1了?
还没有?那我们再假想一个文本串加上来。
待求位: 1 2 3 4 5 6 7 8
文本串: x x x x x x x x x x x x x x x x
模式串: a b a a b c a c
现在标红的位置发生冲突,那么下一步应该让模式串的哪一位跟当前冲突的 x 位对齐呢?没错,就是第0位。也就是变成:
待求位: 1 2 3 4 5 6 7 8
文本串: x x x x x x x x x x x x x x x x
模式串: a b a a b c a c
位数: 0 1 2 3 4 5 6 7 8
所以,当模式串的第一位发生冲突时,应该将模式串的第0位与当前位置对齐,也就是next[1]=0;
继续看第二位发生冲突的情况:
待求位: 1 2 3 4 5 6 7 8
文本串: a x x x x x x x x x x x x x x x
模式串: a b a a b c a c
此时需要将模式串移动为:
待求位: 1 2 3 4 5 6 7 8
文本串: a x x x x x x x x x x x x x x x
模式串: a b a a b c a c
位数: 0 1 2 3 4 5 6 7 8
所以,当模式串的第二位发生冲突时,应该将模式串的第1位与当前位置对齐,也就是next[2]=1;
无论模式串如何变化,只要其长度大于等于2,这两种情况都是固定的,因此next[1]一定为0,next[2]一定为1。
继续看第三位发生冲突的情况:
待求位: 1 2 3 4 5 6 7 8
文本串: a b x x x x x x x x x x x x x x
模式串: a b a a b c a c
这时,假如我们仍然只移动一位,可以吗?
待求位: 1 2 3 4 5 6 7 8
文本串: a b x x x x x x x x x x x x x x
模式串: a b a a b c a c
可以发现,如果仍然只移动一位,那么 x 位之前的位置也出现了冲突!
因此究竟该将模式串的哪一位与冲突的位置对齐呢?
一个重要原则是:当前冲突位置之前的一位不能有冲突!
换句话说,要解决第三位的冲突,移动模式串时起码要保证第二位是无冲突的。
那现在出现冲突了怎么办呢?
。
。
。
想想next数组本身的作用?不就是指示了出现了冲突时,应该将哪一位与该位置对齐吗?!
想到这里,问题就变得简单了。
现在第二位出现了冲突,按next[2]指示应该将第一位的a与该位置对齐,那现在冲突解决了吗?
显然b不等于a,没有解决。但是问题已经转化成了第一位的位置出现冲突了!
继续查next[1],等于0,也就是说需要将模式串的第0位与该位置对齐。第0位是空的,我们认为它一定不会产生冲突,至此,第二位的冲突顺利解决了,那现在我们和第二位对齐的是哪一位呢?没错,是第0位,如下:
待求位: 1 2 3 4 5 6 7 8
文本串: a b x x x x x x x x x x x x x x
模式串: a b a a b c a c
位数: 0 1 2 3 4 5 6 7 8
那和第三位(待解决的冲突位)对齐的自然是第0位的下一位,即第一位。由此,便可以得到next[3]=1。
而这个过程就是其他计算详解中所提到的,【找到当前要求的next字符的前一个字符,以它为标准,找到其next对应下标的字符,和这个字符做比较。若相等,那么当前字符的next值就位此字符next加一;若不等,继续找现在字符next所指的下一个字符,还是和之前的字符比较,直到找到第一个位置为止,那么next为1。】其实就是依据现有next值解决前一位冲突的过程。
为了让大家更熟悉这个过程,再继续看一下第四位发生冲突的情况:
待求位: 1 2 3 4 5 6 7 8
文本串: a b a x x x x x x x x x x x x x
模式串: a b a a b c a c
按前面所讲,要确定需要让哪一位与第四位对齐,起码要保证第三位是无冲突的。
第三位是什么?字符a,第三位冲突时需要对齐的是哪一位?是next[3]=1,即第一位的字符a。
显然a和a是相等的,至此第三位的冲突已经解决,我们将模式串的第一位与第三位对齐,如下:
待求位: 1 2 3 4 5 6 7 8
文本串: a b a x x x x x x x x x x x x x
模式串: a b a a b c a c
位数: 0 1 2 3 4 5 6 7 8
那和第四位(待解决的冲突位)对齐的自然是第一位的下一位,即第二位。由此,便可以得到next[4]=2。
第五位冲突的情况:
待求位: 1 2 3 4 5 6 7 8
文本串: a b a a x x x x x x x x x x x x
模式串: a b a a b c a c
至少保证第四位无冲突,第四位为字符a,next[4]=2,所指示字符为第二位的b,a不等于b,转化为第二位的冲突;next[2]=1,所指示的字符位第一位的a,a等于a,冲突解决。此时和第四位对齐的是第一位的a,如下:
待求位: 1 2 3 4 5 6 7 8
文本串: a b a a x x x x x x x x x x x x
模式串: a b a a b c a c
位数: 0 1 2 3 4 5 6 7 8
那和第五位(待解决的冲突位)对齐的自然是第一位的下一位,即第二位。由此,便可以得到next[5]=2。
第六位冲突的情况:
待求位: 1 2 3 4 5 6 7 8
文本串: a b a a b x x x x x x x x x x x
模式串: a b a a b c a c
至少保证第五位无冲突,第五位为字符b,next[5]=2,所指示字符为第二位的b,b等于b,冲突解决。此时和第五位对齐的是第二位的b,如下:
待求位: 1 2 3 4 5 6 7 8
文本串: a b a a b x x x x x x x x x x x
模式串: a b a a b c a c
位数: 0 1 2 3 4 5 6 7 8
那和第六位(待解决的冲突位)对齐的自然是第二位的下一位,即第三位。由此,便可以得到next[6]=3。
第七位和第八位的冲突大家可以自行计算,最终便可以得到模式串的next数组值:
| 位数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 模式串 | a | b | a | a | b | c | a | c |
| next值 | 0 | 1 | 1 | 2 | 2 | 3 | 1 | 2 |
nextval数组
nextval数组在记录什么? 为什么需要nextval数组?
其实和next数组一样,nextval数组也是用来指示当前模式串在该位置匹配冲突时,应该将模式串的哪一位与此位对齐的。
既然nextval数组的作用和next数组一样,那为什么需要nextval数组呢?
在严蔚敏的《数据结构(C语言版)》中,说明了next数组存在的问题,我们同样以该例子来讲。
假设文本串为 “aaabaaaab”,模式串为 “aaaab”。
根据前面的讲述,我们可以得到模式串的next数组值如下:
| 位数 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 模式串 | a | a | a | a | b |
| next值 | 0 | 1 | 2 | 3 | 4 |
冲突发生在第四位:
文本串: a a a b a a a a b
模式串: a a a a b
根据next值,next[4]=3,需要将第3位与该位置对齐:
文本串: a a a b a a a a b
模式串: a a a a b
但此时仍有冲突,这时冲突发生在模式串的第三位,根据next[3]=2,需要将第二位与此位置对齐:
文本串: a a a b a a a a b
模式串: a a a a b
仍有冲突,发生在模式串第二位,next[2]=1,将模式串第一位与此位置对齐:
文本串: a a a b a a a a b
模式串: a a a a b
依然冲突,发生在模式串第一位,next[1]=0,将模式串第0位与此位置对齐:
文本串: a a a b a a a a b
模式串: a a a a b
至此,冲突解决,匹配成功。
但整个过程效率很低,因为模式串前四个字符都为a,当第一次发生冲突时,就可以知道应该直接将第0位和该位置对齐,中间的几次比较和移动都是多余的。
因此,nextval所做的工作就是对next值进行一次修正,排除掉无效移动。
而计算nextval值也有一个原则:保留不同。
为什么说是保留不同呢?分析一下上述例子问题产生的原因就清楚了:
由于计算next值时,我们不清楚当前位置的情况,最多只考虑到了冲突的前一位,就可能导致移动后对齐的字符仍和上一个冲突的字符相同,而这种情况必然会继续冲突。
所以我们要对next值进行一次筛选,保证冲突位置指示的应该对齐的字符和原字符不同。(注:这里我们认为第0位的空白字符与所有字符都不同)
以aaaab为例:
next[1]=0,第一位冲突指示的第0位为空白字符,和第一位本身的a不同,保留原next值,故nextval[1]=0;
next[2]=1,第二位冲突指示的第一位为字符a,和第二位本身的a相同,继续看第一位next[1]的值,(因为相同就表示按next值的此次对齐是无效的,会继续发生第一位的冲突,因此继续看next[1])next[1]=0,指示的第0位位空白字符,和第二位本身的a不同,保留next[1]的值,故nextval[2]=0;
以此类推,可以得到nextval值如下:
| 位数 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 模式串 | a | a | a | a | b |
| next值 | 0 | 1 | 2 | 3 | 4 |
| nextval值 | 0 | 0 | 0 | 0 | 4 |
现在普遍的KMP实现算法中的next数组又在记录什么?
关于这个问题,似乎很少有人进行解释,但这个问题却很容易让人困惑。因为现在普遍的KMP实现算法中所谓的next数组记录的东西和前面所说的next数组以及nextval数组是有区别的。
为了进行区分,我们称这些KMP实现算法中的next数组为Knext数组。
虽然Knext数组在使用时的功能和next数组以及nextval数组相似,但是其记录的内容和求解方法却与next以及nextval有着很大不同。
由于nextval与next没有本质区别,我们单比较Knext与next之间的异同。
相同之处
- Knext和next都是为了提高算法效率,让串的匹配快速找到下一个可能的起始位置,避免文本串指针的回退。
- Knext和next的求解过程都属于动态规划,需要依赖于之前求解出的Knext值和next值。
不同之处
-
Knext记录的是到对应位为止的最长相等前后缀的长度。
这一点可以说是Knext与next最本质的区别,next直接指示了冲突发生时需要对齐的模式串位置,而Knext则是提供了一个基于前缀和后缀的参考,若要直接将其作为指示当前位置冲突时需要对齐的模式串位置(该对齐仍然是基于最长相等前后缀进行选择的,但next和nextval不会涉及前后缀的概念),需要做另外的处理(如统一减1或整体右移)。
这里补充一下什么是最长相等前后缀:
前缀:不包含最后一个字符的所有以第一个字符开头的连续子串
后缀:不包含第一个字符的所有以最后一个字符结尾的连续子串
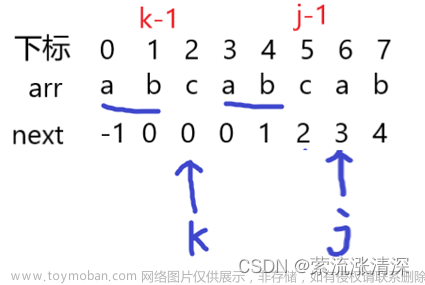
以模式串 aaabbab 为例,
第一位a:没有前缀和后缀,因此最长相等前后缀长度为0,即Knext[1]=0;
第二位a:前缀 {a},后缀 {a},最长相等前后缀长度为1,即Knext[2]=1;
第三位a:前缀 {a,aa},后缀{a,aa},最长相等前后缀长度为2,即Knext[3]=2;
第四位b:前缀{a,aa,aaa},后缀{b,ab,aab},最长相等前后缀长度为0,即Knext[4]=0;
第五位b:前缀{a,aa,aaa,aaab},后缀{b,bb,abb,aabb},最长相等前后缀长度为0,即Knext[5]=0;
第六位a:前缀{a,aa,aaa,aaab,aaabb},后缀{a,ba,bba,abba,aabba},最长相等前后缀长度为1,即Knext[6]=1;
第七位b:前缀{a,aa,aaa,aaab,aaabb,aaabba},后缀{b,ab,bab,bbab,abbab,aabbab},最长相等前后缀长度为0,即Knext[7]=0。
为了更直观地看出它们之间的差异,这里给出模式串aaabbab的next、nextval和Knext值:
| 位数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 模式串 | a | a | a | b | b | a | b |
| next值 | 0 | 1 | 2 | 3 | 1 | 1 | 2 |
| nextval值 | 0 | 0 | 0 | 3 | 1 | 0 | 2 |
| Knext值 | 0 | 1 | 2 | 0 | 0 | 1 | 0 |
关于Knext的求解方法这里不再赘述,可以参考代码随想录的相关讲解。
下方代码块是一个典型的Knext数组求解的实现。文章来源:https://www.toymoban.com/news/detail-736080.html
void getNext(int* next, const string& s) {
int j = 0;
next[0] = 0;
for(int i = 1; i < s.size(); i++) {
while (j > 0 && s[i] != s[j]) {
j = next[j - 1];
}
if (s[i] == s[j]) {
j++;
}
next[i] = j;
}
}
根据个人习惯不同,Knext的求解代码可能会在初始化和比较判断时有差异,但其本质是相同的。文章来源地址https://www.toymoban.com/news/detail-736080.html
到了这里,关于【KMP】从原理上详解next数组和nextval数组的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[数据结构] 串与KMP算法详解](https://imgs.yssmx.com/Uploads/2024/02/825350-1.png)