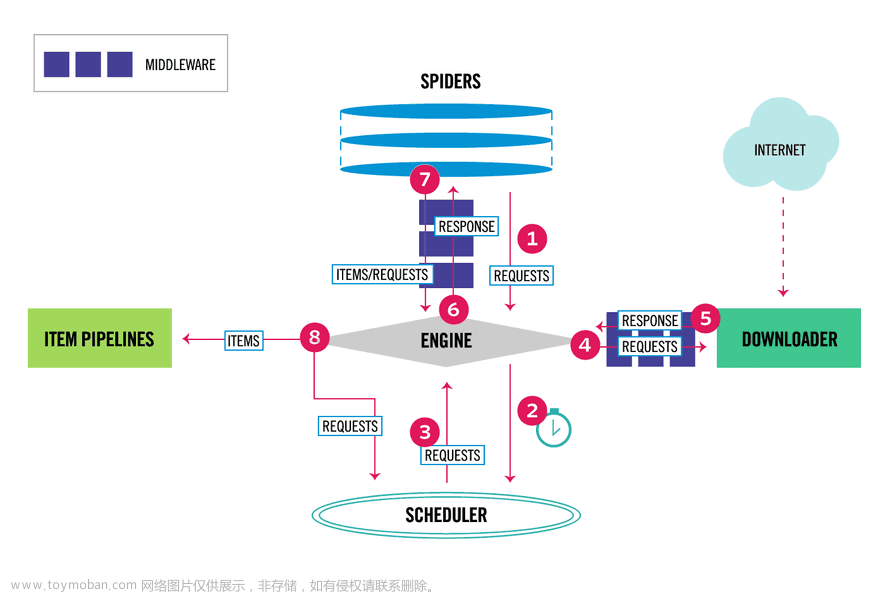
1 异步加载的html页面,页面源代码数据xpath是找不到的
1.0 网站分析
#淘宝搜索页网址:https://s.taobao.com/search?q=手机
#搜索列表页分析:
第一页:https://s.taobao.com/search?q=手机
第二页:都是ajax请求生成
最后一页:都是ajax请求生成
请求方式get
返回数据为html
1.1 创建项目
scrapy startproject taobaoSpider
cd ssqSpider
scrapy genspider taobao taobao.com
1.2 创建爬虫
scrapy genspider taobao "taobao.com"
1.3 添加工具函数模块utils.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.common import exceptions
import json
def create_chrome_driver(headless=False):
options=webdriver.ChromeOptions()
if headless:
options.add_argument('--headless')
#去掉chrome正在受到测试软件的控制的提示条
options.add_experimental_option('excludeSwitches',['enable-automation'])
options.add_experimental_option('useAutomationExtension',False)
options.add_argument("--disable-blink-features=AutomationControlled")
# 定义chrome驱动去地址
service = Service('chromedriver.exe')
# service=Service(r'E:\项目区\项目2023-编程项目教程\ssq_caipiao_pachong\taobaoSpider\chromedriver.exe')
browser=webdriver.Chrome(service=service,options=options)
#反爬,修改为navigator.webdriver=undefined
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source':'Object.defineProperty(navigator,"webdriver",{get:()=>undefined})'})
return browser
def add_cookies(browser,cookie_file):
with open(cookie_file,'r') as file:
cookies_list=json.load(file)
for cookie_dict in cookies_list:
if cookie_dict['secure']:
try:
browser.add_cookie(cookie_dict)
except exceptions.InvalidCookieDomainException as e:
print(e.msg)
def test():
print("ggggggg")
1.4 测试淘宝页面反爬机制
1.4.1 taobao_login.py模拟登陆生成cookies.json
from utils import create_chrome_driver,add_cookies,test
import json
import time
from selenium.webdriver.common.by import By
browser=create_chrome_driver()
time.sleep(1)
# browser.get('https://taobao.com')
# time.sleep(1)
# el=browser.find_element(by=By.XPATH,value='//*[@id="q"]')
# el.send_keys('手机')
# time.sleep(1)
# el=browser.find_element(by=By.XPATH,value='//*[@id="J_TSearchForm"]/div[1]/button')
# el.click()
# time.sleep(1)
# # #滚动到底部
# # js="window.scrollTo(0,450);"
# # driver.execute_script(js)
# # sleep(3)
# # 或者
# js = "var q=document.documentElement.scrollTop=4514"
# browser.execute_script(js)
# time.sleep(1)
# # 点击下一页
# el=browser.find_element(by=By.XPATH,value='//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/button[2]')
# el.click()
# time.sleep(1)
# browser.get('https://s.taobao.com/search?commend=all&ie=utf8&initiative_id=tbindexz_20170306&q=%E6%89%8B%E6%9C%BA&search_type=item&sourceId=tb.index&spm=a21bo.jianhua.201856-taobao-item.2&ssid=s5-e')
#进入登陆页面
browser.get('https://login.taobao.com/member/login.jhtml')
time.sleep(1)
el=browser.find_element(by=By.XPATH,value='//*[@id="fm-login-id"]')
el.send_keys('123@qq.com')
el=browser.find_element(by=By.XPATH,value='//*[@id="fm-login-password"]')
el.send_keys('123456')
el=browser.find_element(by=By.XPATH,value='//*[@id="login-form"]/div[4]/button')
el.click()
time.sleep(6)
#保存cookie
with open('taobao_cookie.json','w') as file:
json.dump(browser.get_cookies(), file)
time.sleep(1)
# print(browser.page_source)
browser.get('https://s.taobao.com/search?q=手机')
time.sleep(1)
time.sleep(600)
1.4.2 taobao_login_after.py淘宝登陆后测试
from utils import create_chrome_driver,add_cookies,test
import json
import time
from selenium.webdriver.common.by import By
browser=create_chrome_driver()
time.sleep(1)
# 先访问下页面再设置cookie,否则报错
browser.get('https://taobao.com')
time.sleep(1)
add_cookies(browser,'taobao_cookie.json')
time.sleep(1)
browser.get('https://s.taobao.com/search?q=手机')
time.sleep(1)
time.sleep(600)
1.5 修改下载中间件
from scrapy import signals
from scrapy.http import HtmlResponse
import time
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
from utils import create_chrome_driver,add_cookies
from taobaoSpider.spiders.taobao import TaobaoSpider
class TaobaospiderDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def __init__(self):
self.browser=create_chrome_driver()
self.browser.get('https://www.taobao.com')
add_cookies(self.browser, 'taobao_cookie.json')
def __del__(self):
self.browser.close()
pass
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
if not isinstance(spider, TaobaoSpider):
return None
else:
self.browser.get(request.url)
time.sleep(2)
# # #滚动到底部
# js="window.scrollTo(0,450);"
# self.browser.execute_script(js)
# sleep(3)
# # 或者
# js = "var q=document.documentElement.scrollTop=4514"
# self.browser.execute_script(js)
# time.sleep(2)
# 慢慢滚动
for i in range(45,4514,400):
js = f"var q=document.documentElement.scrollTop={i}"
self.browser.execute_script(js)
time.sleep(0.5)
# # 点击下一页
# el=browser.find_element(by=By.XPATH,value='//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/button[2]')
# el.click()
# time.sleep(1)
return HtmlResponse(url=request.url,body=self.browser.page_source,
request=request,encoding='utf-8')
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info("Spider opened: %s" % spider.name)
修改下载中间件配置文章来源地址https://www.toymoban.com/news/detail-736105.html
DOWNLOADER_MIDDLEWARES = {
"taobaoSpider.middlewares.TaobaospiderDownloaderMiddleware": 543,
}
1.6 修改爬虫代码
1.6.1 添加数据模型
import scrapy
class TaobaospiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
pass
1.6.2 修改爬虫代码
import scrapy
from scrapy import Request
from scrapy.http import HtmlResponse
from taobaoSpider.items import TaobaospiderItem
class TaobaoSpider(scrapy.Spider):
name = "taobao"
allowed_domains = ["taobao.com"]
# start_urls = ["https://taobao.com"]
def start_requests(self):
keywords=['手机','笔记本电脑','键鼠套装']
keywords=['手机']
for keyword in keywords:
for page in range(1):
url=f'https://s.taobao.com/search?q={keyword}&s={page*48}'
yield Request(url)
def parse(self, response:HtmlResponse):
# print(response.text)
cssitem_list=response.xpath('//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[3]/div/div')
# print(len(cssitem_list))
for cssitem in cssitem_list:
item=TaobaospiderItem()
item['title']=cssitem.xpath('./a/div/div[1]/div[2]/div/span/text()').extract()
yield item
pass
1.6.3 测试运行爬虫
scrapy crawl taobao #正式运行
或者
scrapy crawl taobao -o taobao.csv
文章来源:https://www.toymoban.com/news/detail-736105.html
到了这里,关于04 python38的scrapy和selenium处理异步加载的动态html页面的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!