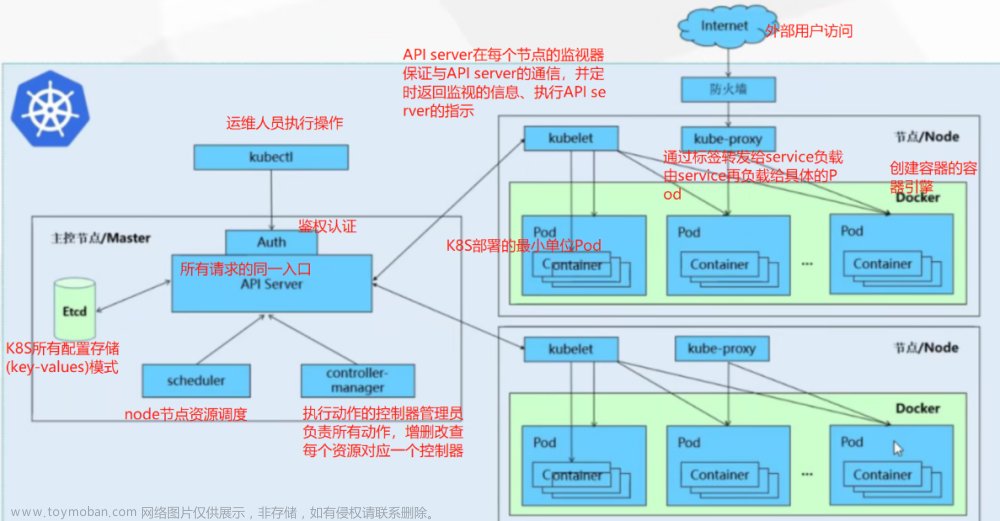
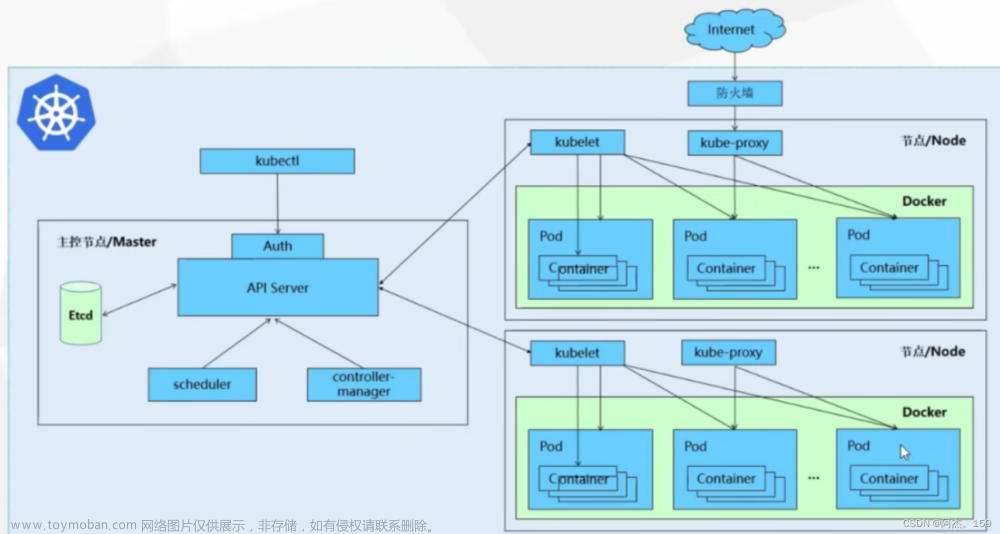
背景
数据服务平台南海容器k8s设置的内存上限2GB,多次容器被OOM killed。
启动命令
java -XX:MaxRAMPercentage=70.0 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/apps/logs/ ***.jar
排查过程
1 当收到实例内存超过95%告警时,把jvm进程堆dump下来后,用visual vm分析堆内存,并未发现内存泄漏。推测进程就需要花较多的内存,是内存分配不够。遂将内存增加到4GB。继续观察
2 南海和顺德docker实例依然OOM killed。 当实例内存超过95%时,dump出堆内存并分析,依然没有发现内存泄漏,比较正常。
3 怀疑是容器内部除了java的其他进程耗用了容器内存。当实例内存超过95%时,对比top显示的的jvm进程内存和ps stats输出的docker实例内存信息,其余进程耗用的内存忽略不计。
4 由于堆内存没有的到达上限,但是整个jvm进程内存超出了容器的内存限制。因此推测是对外内存(本地内存,栈内存等,元数据空间等)耗用较大,执行命令
/****/jcmd 1 VM.native_memory
VM.native_memory特性并未开启。
5 观察到一个现象,docker进程被oom killed之前,java应用堆内存并没有被Full gc。并且堆内存没有用到上限值2.8GB(4 * 0.7)。docker是go语言编写,并没有GC的能力。docker耗用完内存前,堆内存并没有达到上限,于是没有触发老年代GC,内存没有降下去。当堆内存不够的时候,依然会找docker容器申请内存。
6 修改jvm配置,将南海的MaxRAMPercentage降到60, 南海分组的堆内存上限变成2.4GB(4 * 0.6),顺德分组不变。并增加-XX:NativeMemoryTracking=summary配置。8.18日重启所有实例使新增的配置生效。观察一段时间

发现南海分组的full gc更加频繁,继续观察文章来源:https://www.toymoban.com/news/detail-736324.html
结论
如果容器OOM killed,容器里的jvm进程没有Full GC,那么肯定是MaxRAMPercentage参数太高,导致堆内存没有用到上限,无法触发堆内存(老年代)GC。这个情况下就需要把MaxRAMPercentage参数适当调低。文章来源地址https://www.toymoban.com/news/detail-736324.html
到了这里,关于K8S容器OOM killed排查的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!