作者:禅与计算机程序设计艺术
1.简介
Apache HBase是一个开源的分布式数据库系统,能够处理超大量的数据。相对于关系型数据库,HBase提供更高的容错性、可扩展性和高性能。本文将从HBase的历史和特性出发,到其最新版本中所增加的新功能以及其在大数据应用中的作用。
Apache HBase简介
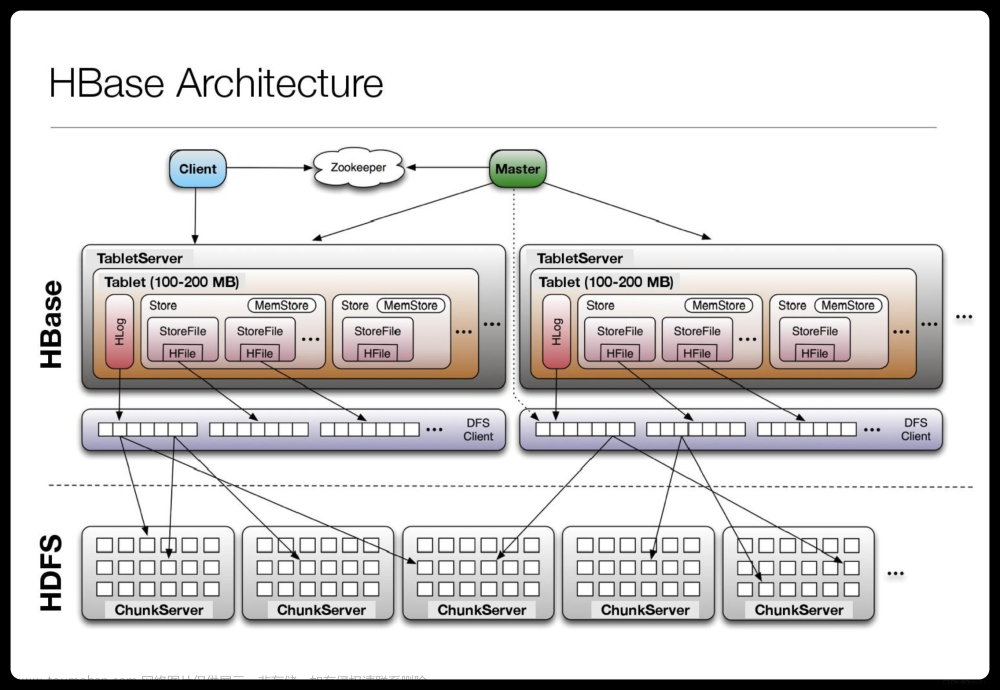
Apache HBase是一个分布式的、面向列的、可伸缩的存储系统,支持随机读写访问和实时分析查询,能够进行海量数据的维护、查询和检索。它最初被设计用于处理BigTable项目开发的海量结构化数据,后来开源并加入了Apache基金会旗下。截止2020年7月,HBase已经成为Apache顶级项目,并持续维护更新。
HBase特性
HBase拥有如下几个主要特征:
-
分布式:HBase采用主/备份模式的架构,其中一个节点充当主节点负责存储所有的数据,另一个节点作为备份进行读取,以防止单点故障。
-
面向列:HBase以行键值对的形式存储数据,但是不是真正的关系型数据库,不支持SQL语句。因此,其对多维数据模型的支持不是很好,只能通过编程的方式实现复杂的查询。不过,HBase支持灵活的Schema设计,可以定义多个列簇,每个列簇都有自己的属性集。
-
可伸缩性:HBase提供自动水平拆分、动态负载均衡、自动故障转移等功能,可以在集群内动态调整数据分布,解决海量数据存储问题。文章来源:https://www.toymoban.com/news/detail-736340.html
-
实时分析查询:HBase提供实时的分析查询能力,支持MapRed文章来源地址https://www.toymoban.com/news/detail-736340.html
到了这里,关于HBase深度解析:HBase在大数据应用中的角色的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!