数据库设计实操(含ER模型)
1. ER模型
1.1 概述
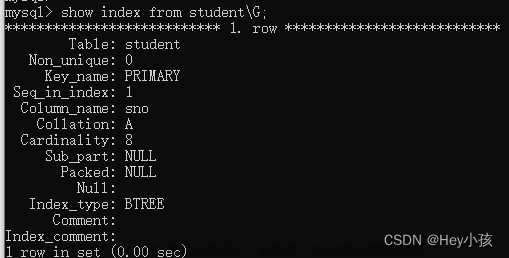
ER 模型中有三个要素,分别是实体、属性和关系
实体 ,可以看做是数据对象,往往对应于现实生活中的真实存在的个体。在 ER 模型中,用 矩形 来表示。实体分为两类,分别是 强实体 和 弱实体 。强实体是指不依赖于其他实体的实体;弱实体是指对另一个实体有很强的依赖关系的实体。
属性 ,则是指实体的特性。比如超市的地址、联系电话、员工数等。在 ER 模型中用 椭圆形 来表示。
关系 ,则是指实体之间的联系。比如超市把商品卖给顾客,就是一种超市与顾客之间的联系。在 ER 模型中用 菱形 来表示。关系又可以分为 3 种类型,分别是一对一、一对多、多对多。
1.2 建模分析
ER 模型看起来比较麻烦,但是对我们把控项目整体非常重要。如果你只是开发一个小应用,或许简单设计几个表够用了,一旦要设计有一定规模的应用,在项目的初始阶段,建立完整的 ER 模型就非常关键了。开发应用项目的实质,其实就是 建模 。
这里以 电商业务 设计为案例,由于电商业务太过庞大且复杂,所以我们做了业务简化,比如针对SKU(StockKeepingUnit,库存量单位)和SPU(Standard Product Unit,标准化产品单元)的含义上,我们直接使用了SKU,并没有提及SPU的概念。本次电商业务设计总共有8个实体,如下所示。
- 地址实体
- 用户实体
- 购物车实体
- 评论实体
- 商品实体
- 商品分类实体
- 订单实体
- 订单详情实体
其中, 用户 和 商品分类 是强实体,因为它们不需要依赖其他任何实体。而其他属于弱实体,因为它们虽然都可以独立存在,但是它们都依赖用户这个实体,因此都是弱实体。知道了这些要素,我们就可以从强实体 用户 开始给电商业务创建 ER 模型了,如图:

1.3 ER 模型的细化
有了这个 ER 模型,我们就可以从整体上 理解 电商的业务了。刚刚的 ER 模型展示了电商业务的框架,但是只包括了订单,地址,用户,购物车,评论,商品,商品分类和订单详情这八个实体,以及它们之间的关系,还不能对应到具体的表,以及表与表之间的关联。我们需要把 属性加上 ,用 椭圆 来表示,这样我们得到的 ER 模型就更加完整了。
因此,我们需要进一步去设计一下这个 ER 模型的各个局部,也就是细化下电商的具体业务流程,然后把它们综合到一起,形成一个完整的 ER 模型。这样可以帮助我们理清数据库的设计思路。
接下来,我们再分析一下各个实体都有哪些属性,如下所示:
-
地址实体包括用户编号、省、市、地区、收件人、联系电话、是否是默认地址 -
用户实体包括用户编号、用户名称、昵称、用户密码、手机号、邮箱、头像、用户级别 -
购物车实体包括购物车编号、用户编号、商品编号、商品数量、图片文件url -
订单实体包括订单编号、收货人、收件人电话、总金额、用户编号、付款方式、送货地址、下单时间 -
订单详情实体包括订单详情编号、订单编号、商品名称、商品编号、商品数量 -
商品实体包括商品编号、价格、商品名称、分类编号、是否销售,规格、颜色 -
评论实体包括评论id、评论内容、评论时间、用户编号、商品编号 -
商品分类实体包括类别编号、类别名称、父类别编号
这样细分之后,我们就可以重新设计电商业务了,ER 模型如图:

1.4 ER 模型图转换成数据表
通过绘制 ER 模型,我们已经理清了业务逻辑,现在,我们就要进行非常重要的一步了:把绘制好的 ER模型,转换成具体的数据表,下面介绍下转换的原则:
- 一个
实体通常转换成一个数据表; - 一个
多对多的关系 ,通常也转换成一个数据表; - 一个
1 对 1,或者1 对多的关系,往往通过表的外键来表达,而不是设计一个新的数据表; -
属性转换成表的字段
1. 一个实体转换成一个数据库表
首先看强实体转换成数据表
用户实体转换成用户表
CREATE TABLE
user_info
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号',
user_name VARCHAR(200) COMMENT '用户名称',
nick_name VARCHAR(200) COMMENT '用户昵称',
password VARCHAR(200) COMMENT '用户密码',
phone_num VARCHAR(20) COMMENT '手机号',
email VARCHAR(200) COMMENT '邮箱',
head_img VARCHAR(200) COMMENT '头像',
user_level VARCHAR(200) COMMENT '用户级别',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci COMMENT='用户表';
商品分类实体 转换成商品分类表 (base_category) ,由于商品分类可以有一级分类和二级分类,比如一级分类有家居、手机等等分类,二级分类可以根据手机的一级分类分为手机配件,运营商等,这里我们把商品分类实体规划为两张表,分别是 一级分类表 和 二级分类表,之所以这么规划是因为一级分类和二级分类都是有限的,存储为两张表业务结构更加清晰。
CREATE TABLE
base_category1
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号',
name VARCHAR(100) NOT NULL COMMENT '分类名称',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci COMMENT='一级分类表';
CREATE TABLE
base_category2
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号',
name VARCHAR(100) NOT NULL COMMENT '二级分类名称',
category1_id bigint COMMENT '一级分类编号',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci COMMENT='二级分类表';
再把弱实体转换为数据表
地址实体 转换成地址表 (user_address)
CREATE TABLE
user_address
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号',
province VARCHAR(255) COMMENT '省',
city VARCHAR(255) COMMENT '市',
user_address VARCHAR(255) COMMENT '详细地址',
user_id bigint UNSIGNED COMMENT '用户id',
consignee VARCHAR(50) COMMENT '收件人',
telephone VARCHAR(20) COMMENT '联系方式',
default_mark TINYINT COMMENT '是否默认(1:是 0:否)',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci;
订单实体 转换成订单表 (order_info)
CREATE TABLE
order_info
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号',
consignee VARCHAR(50) COMMENT '收件人',
consignee_tel VARCHAR(20) COMMENT '联系方式',
total_amount DECIMAL(10,2) COMMENT '总金额',
user_id bigint UNSIGNED COMMENT '用户id',
payment_way VARCHAR(20) COMMENT '付款方式',
delivery_address VARCHAR(255) COMMENT '送货地址',
create_time DATETIME COMMENT '下单时间',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci COMMENT='订单表';
订单详情实体 转换成订单详情表 (order_detail) ,如下所示。(用于体现多对多关系的,见下节)
CREATE TABLE
order_detail
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '订单详情编号',
order_id bigint UNSIGNED COMMENT '订单编号',
sku_id bigint COMMENT 'sku_id',
sku_name VARCHAR(200) COMMENT 'sku名称',
sku_num INT COMMENT '购买个数',
create_time DATETIME COMMENT '操作时间',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci COMMENT='订单明细表';
购物车实体 转换成购物车表 (cart_info)
CREATE TABLE
cart_info
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号',
user_id bigint UNSIGNED NOT NULL COMMENT '用户id',
sku_id bigint UNSIGNED COMMENT 'skuid',
sku_num INT COMMENT '数量',
img_url VARCHAR(255) COMMENT '图片链接',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci COMMENT='购物车表';
评论实体 转换成评论表 (sku_comment)
CREATE TABLE
sku_comment
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号',
user_id bigint UNSIGNED NOT NULL COMMENT '用户编号',
sku_id bigint UNSIGNED NOT NULL COMMENT '商品编号',
COMMENT VARCHAR(255) COMMENT '评论内容',
create_time DATETIME COMMENT '评论时间',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci COMMENT='商品评论表';
商品实体转换成商品表(sku_info)
CREATE TABLE
sku_info
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '商品编号',
price DECIMAL(10,2) COMMENT '价格',
sku_name VARCHAR(255) COMMENT '商品名称',
sku_desc VARCHAR(2000) COMMENT '商品描述',
category3_id bigint UNSIGNED COMMENT '三级分类id(冗余)',
color VARCHAR(50) COMMENT '颜色',
sale_mark TINYINT COMMENT '是否销售(1:是 0:否)',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci;
2. 一个多对多的关系转换成一个数据表
这个ER 模型中的多对多的关系有1 个,即 商品 和 订单 之间的关系,同品类的商品可以出现在不同的订单中,不同的订单也可以包含同一类型的商品,所以它们之间的关系是多对多。针对这种情况需要设计一个独立的表来表示,这种表一般称为 中间表。
我们可以设计一个独立的 订单详情表,来代表商品和订单之间的包含关系。这个表关联到 2个实体,分别是订单、商品。所以,表中必须要包括这 2个实体转换成的表的主键。除此之外,我们还要包括该关系自有的属性商品数量,商品下单价格以及商品名称。即上面已经创建的订单详情表order_detail,这里再看一遍
CREATE TABLE
order_detail
(
id bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '订单详情编号',
order_id bigint UNSIGNED COMMENT '订单编号',
sku_id bigint COMMENT 'sku_id',
sku_name VARCHAR(200) COMMENT 'sku名称',
sku_num INT COMMENT '购买个数',
create_time DATETIME COMMENT '操作时间',
PRIMARY KEY (id)
)
ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 DEFAULT COLLATE=utf8mb4_general_ci COMMENT='订单明细表';
3. 通过外键来表达1对多的关系
如商品评论表中,user_id和sku_id定义为外键。注意,一般不在数据库层面设置外键约束,因为外键会导致性能下降,对性能影响是负面的。而是通过应用层做数据的 一致性检查来使得数据满足外键功能。
4. 把属性转换成表的字段
1.5 小结
任何一个基于数据库的应用项目,都可以通过这种 先建立 ER 模型 ,再 转换成数据表 的方式,完成数据库的设计工作。创建 ER 模型不是目的,目的是把业务逻辑梳理清楚,设计出优秀的数据库。不要为了建模而建模,要利用创建 ER 模型的过程来整理思路,这样创建 ER 模型才有意义。
 文章来源:https://www.toymoban.com/news/detail-736763.html
文章来源:https://www.toymoban.com/news/detail-736763.html
2. 数据库表的设计原则
- 数据表的个数越少越好
- 数据表中的字段个数越少越好
- 数据表中联合主键的字段个数越少越好
- 使用主键和外键越多越好
注意:这个原则并不是绝对的,有时候我们需要牺牲数据的冗余度来换取数据处理的效率文章来源地址https://www.toymoban.com/news/detail-736763.html
3. 数据库对象编写建议
3.1 关于库
- 【强制】库的名称必须控制在32个字符以内,只能使用英文字母、数字和下划线,建议以英文字母开头。
- 【强制】库名中英文
一律小写,不同单词采用下划线分割。须见名知意。 - 【强制】库的名称格式:业务系统名称_子系统名。
- 【强制】库名禁止使用关键字(如type,order等)。
- 【强制】创建数据库时必须
显式指定字符集,并且字符集只能是utf8或者utf8mb4。
创建数据库SQL举例:CREATE DATABASE crm_fund DEFAULT CHARACTER SET ‘utf8’ ; - 【建议】对于程序连接数据库账号,遵循
权限最小原则
使用数据库账号只能在一个DB下使用,不准跨库。程序使用的账号 原则上不准有drop权限 。 - 【建议】临时库以 tmp_ 为前缀,并以日期为后缀;
备份库以 bak_ 为前缀,并以日期为后缀。
3.2 关于表、列
- 【强制】表和列的名称必须控制在32个字符以内,表名只能使用英文字母、数字和下划线,建议以
英文字母开头 。 - 【强制】 表名、列名一律小写 ,不同单词采用下划线分割。须见名知意。
- 【强制】表名要求有模块名强相关,同一模块的表名尽量使用 统一前缀 。比如:crm_fund_item
- 【强制】创建表时必须 显式指定字符集 为utf8或utf8mb4。
- 【强制】表名、列名禁止使用关键字(如type,order等)。
- 【强制】创建表时必须 显式指定表存储引擎 类型。如无特殊需求,一律为InnoDB。
- 【强制】建表必须有comment。
- 【强制】字段命名应尽可能使用表达实际含义的英文单词或
缩写。如:公司 ID,不要使用corporation_id, 而用corp_id 即可。 - 【强制】布尔值类型的字段命名为 is_描述 。如member表上表示是否为enabled的会员的字段命名为 is_enabled。
- 【强制】禁止在数据库中存储图片、文件等大的二进制数据通常文件很大,短时间内造成数据量快速增长,数据库进行数据库读取时,通常会进行大量的随
机IO操作,文件很大时,IO操作很耗时。通常存储于文件服务器,数据库只存储文件地址信息。 - 【建议】建表时关于主键: 表必须有主键
- 强制要求主键为id,类型为int或bigint,且为auto_increment 建议使用unsigned无符号型。
- 标识表里每一行主体的字段不要设为主键,建议设为其他字段如user_id,order_id等,并建立unique key索引。因为如果设为主键且主键值为随机插入,则会导致innodb内部页分裂和大量随机I/O,性能下降。
- 【建议】核心表(如用户表)必须有行数据的 创建时间字段 (create_time)和 最后更新时间字段(update_time),便于查问题。
- 【建议】表中所有字段尽量都是 NOT NULL 属性,业务可以根据需要定义 DEFAULT值 。 因为使用NULL值会存在每一行都会占用额外存储空间、数据迁移容易出错、聚合函数计算结果偏差等问题。
- 【建议】所有存储相同数据的 列名和列类型必须一致 (一般作为关联列,如果查询时关联列类型不一致会自动进行数据类型隐式转换,会造成列上的索引失效,导致查询效率降低)。
- 【建议】中间表(或临时表)用于保留中间结果集,名称以 tmp_ 开头。
备份表用于备份或抓取源表快照,名称以 bak_ 开头。中间表和备份表定期清理。 - 【建议】创建表时,可以使用可视化工具。这样可以确保表、字段相关的约定都能设置上。实际上,我们通常很少自己写 DDL 语句,可以使用一些可视化工具来创建和操作数据库和数据表。可视化工具除了方便,还能直接帮我们将数据库的结构定义转化成 SQL 语言,方便数据库和数据表结构的导出和导入
3.3 关于索引
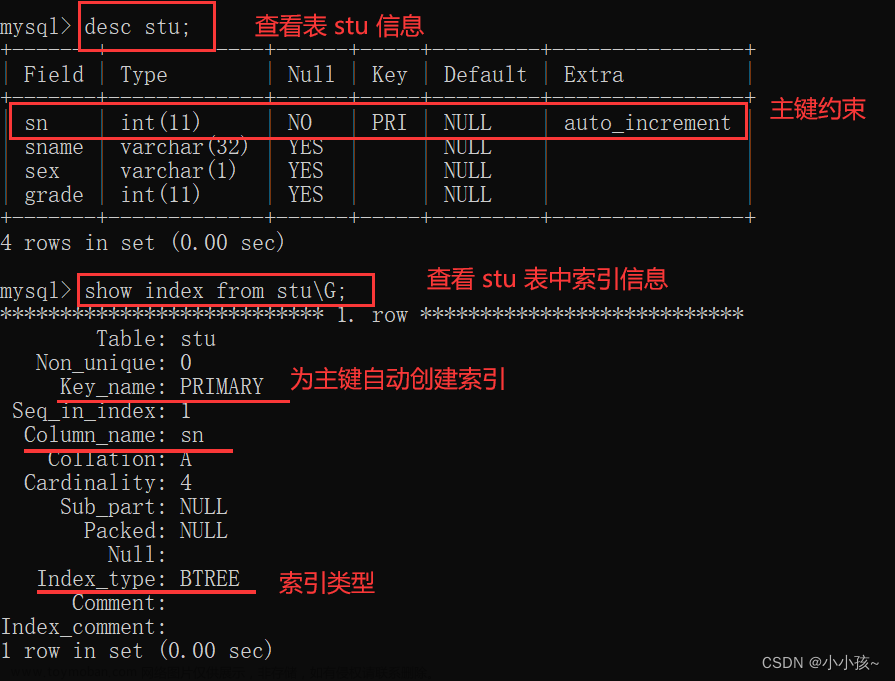
- 【强制】InnoDB表必须主键为id int/bigint auto_increment,且主键值 禁止被更新 。
- 【强制】InnoDB和MyISAM存储引擎表,索引类型必须为 BTREE 。
- 【建议】主键的名称以 pk_ 开头,唯一键以 uni_ 或 uk_ 开头,普通索引以 idx_ 开头,一律使用小写格式,以字段的名称或缩写作为后缀。
- 【建议】多单词组成的columnname,取前几个单词首字母,加末单词组成column_name。如:sample 表 member_id 上的索引:idx_sample_mid。
- 【建议】单个表上的索引个数 不能超过6个 。
- 【建议】在建立索引时,多考虑建立 联合索引 ,并把区分度最高的字段放在最前面。
- 【建议】在多表 JOIN 的SQL里,保证被驱动表的连接列上有索引,这样JOIN 执行效率最高。
- 【建议】建表或加索引时,保证表里互相不存在
冗余索引。 比如:如果表里已经存在key(a,b),则key(a)为冗余索引,需要删除。
3.4 SQL编写
- 【强制】程序端SELECT语句必须指定具体字段名称,禁止写成 *。
- 【建议】程序端insert语句指定具体字段名称,不要写成INSERT INTO t1 VALUES(…)。
- 【建议】除静态表或小表(100行以内),DML语句必须有WHERE条件,且使用索引查找。
- 【建议】INSERT INTO…VALUES(XX),(XX),(XX)… 这里XX的值不要超过5000个。 值过多虽然上线很快,但会引起主从同步延迟。
- 【建议】SELECT语句不要使用UNION,推荐使用UNION ALL,并且UNION子句个数限制在5个以内。
- 【建议】线上环境,多表 JOIN 不要超过5个表。
- 【建议】减少使用ORDER BY,和业务沟通能不排序就不排序,或将排序放到程序端去做。ORDERBY、GROUP BY、DISTINCT 这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。
- 【建议】包含了ORDER BY、GROUP BY、DISTINCT 这些查询的语句,WHERE 条件过滤出来的结果集请保持在1000行以内,否则SQL会很慢。
- 【建议】对单表的多次alter操作必须合并为一次对于超过100W行的大表进行alter table,必须经过DBA审核,并在业务低峰期执行,多个alter需整
合在一起。 因为alter table会产生表锁,期间阻塞对于该表的所有写入,对于业务可能会产生极大影响。 - 【建议】批量操作数据时,需要控制事务处理间隔时间,进行必要的sleep。
- 【建议】事务里包含SQL不超过5个。因为过长的事务会导致锁数据较久,MySQL内部缓存、连接消耗过多等问题。
- 【建议】事务里更新语句尽量基于主键或UNIQUE KEY,如UPDATE… WHERE id=XX;否则会产生间隙锁,内部扩大锁定范围,导致系统性能下降,产生死锁。
到了这里,关于【MySQL索引与优化篇】数据库设计实操(含ER模型)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[架构之路-172]-《软考-系统分析师》-5-数据库系统-5- 数据库设计与建模(逻辑设计-实体关系图ER图-关系图、物理设计)](https://imgs.yssmx.com/Uploads/2024/02/421480-1.png)