背景:
最近笔者所在的公司在调研使用flink,因为公司只有笔者一个大数据开发,笔者有幸主导了此次调研,但是我们也属于新手上路,之后也会将过程中遇到的一些坑和大家分享。当然了目前我们还在DataStream Api阶段挣扎,争取早日将flink sql上线,这次的错误是在开发过程中消费kafka时遇到。特此记录一下备忘,也希望对大家有帮助,下面我们看下错误。
现象与分析
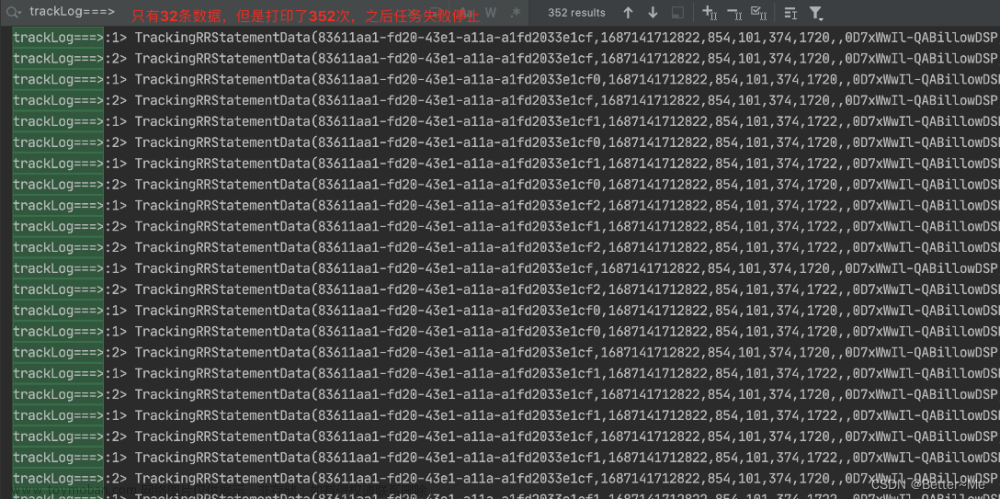
我们这里数据任务看到的现象是任务一直没有新的数据产生,排查TaskManager和JobManager日志发现taskmanager日志中报如下错误:
Caused by: akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@xxx.xxx.xxx.xxx:6123/user/rpc/jobmanager_2#360860634]] after [10000 ms].
Message of type [org.apache.flink.runtime.rpc.messages.RemoteFencedMessage].
A typical reason for `AskTimeoutException` is that the recipient actor didn't send a reply.
2023-05-22 15:56:36,474 INFO org.apache.flink.runtime.taskexecutor.TaskExecutor []
- Cannot find task to fail for execution d0748c664c42f1de87b6785c9b37cf49_687d766627c4a5a1e88148795d8315c0_0_1 with exception:
java.util.concurrent.TimeoutException: Invocation of
[RemoteRpcInvocation(JobMasterGateway.updateTaskExecutionState(TaskExecutionState))] at recipient [akka.tcp://flink@xxx.xxx.xxx.xxx:6123/user/rpc/jobmanager_2] timed out.
This is usually caused by:
1) Akka failed sending the message silently, due to problems like oversized payload or serialization failures. In that case, you should find detailed error information in the logs.
2) The recipient needs more time for responding, due to problems like slow machines or network jitters. In that case, you can try to increase akka.ask.timeout.
看到报错我们肯定多少也知道Flink其实是使用了akka这个通信的框架进行异步通信的。于是我们首先选择直接重启任务,发现任务到了某个时间节点之后任务就直接报错。我们知道其实早在Flink 0.9版本就采用的Akka作为分布式通信的实现。Flink有了Akka,所有的远程过程调用(RPC)被实现成异步消息。这主要影响了JobManager、TaskManager和JobClient三个组件。所以这里分析是任务的JobManager与TaskManager进行数据通信时超时,阅读报错信息告诉我们错误通常是由于:
- 由于负载过大或序列化失败等问题,Akka无法以静默方式发送消息。在这种情况下,您应该在日志中找到详细的错误信息。
- 由于机器速度慢或网络抖动等问题,收件人需要更多的时间来响应。在这种情况下,您可以尝试增加akka.ask.timeout。
经过分析,发现我们大约流量1000条/min,数据流量特别小,所以不太可能是负载高的问题,而且除了这些报错外,并没有发现其他的报错。所以这里我们将思路放在调整akka.ask.timeout参数上。
我们查看官网参数介绍找到关于akka的部分找到了该参数:![Flink消费kafka报akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@xxx]]after x,Flink,flink,kafka,akka](https://imgs.yssmx.com/Uploads/2023/11/737140-1.png)
分析到这里笔者先给大家隐藏答案,大家先自己思考该如何解决
解决方案
我们发现参数默认为10s,因为我们使用的是Flinkonk8s这种方式,于是我们直接在job中配置相关的参数:
akka.ask.timeout: 60 s
如果是其他的方式,可以在$FLINK_HOME/conf/flink-conf.yaml中修改。
如果你使用的是Flink1.9以下的版本还需要修改如下参数:
web.timeout="1000000"
因为在flink1.8版本发现flink默认web.timeout只有10s![Flink消费kafka报akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@xxx]]after x,Flink,flink,kafka,akka](https://imgs.yssmx.com/Uploads/2023/11/737140-2.png)
我们在查看flink1.9版本发现默认web.timeout只有600s![Flink消费kafka报akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@xxx]]after x,Flink,flink,kafka,akka](https://imgs.yssmx.com/Uploads/2023/11/737140-3.png)
总结:
我们在使用flink的时候还是得多了解底层原理才行。
拓展
一个actor是一个自身状态和行为的容器。它的actor线程连续处理收到的消息。这减轻了用户编写易出错的锁和线程管理任务,因为每个actor每一时刻只有一个线程是活动的。然而,必须保证一个actor的内部状态只被这个actor线程访问。一个actor的行为由一个接收函数定义,这个函数包含一个收到每条消息时被执行的逻辑。
Flink系统由三个分布式通信组件组成:JobClient、JobManager、TaskManager。JobClient接收一个来自用户的Flink作业并提交给JobManager。JobManager然后负责协调作业的执行。首先,它分配需要的资源。这主要包括TaskManagers上的运行slots。资源分配后,JobManager部署作业的各个tasks到各个TaskManagers。一收到task,TaskManager创建一个执行该task的线程。如果状态发生改变,例如开始计算或完成计算,被发送回JobManager。JobManager就会基于状态更新控制作业执行直到完成。一旦作业完成,结果将被发送到JobClient,由它告知用户运行结果。![Flink消费kafka报akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@xxx]]after x,Flink,flink,kafka,akka](https://imgs.yssmx.com/Uploads/2023/11/737140-4.png)
-
JobManager & TaskManager
JobManager是负责执行一个Flink作业的中央控制单元。同样地,它管理资源分配、任务调度和状态报告。在任何Flink作业可以被执行前,一个JobManager和至少一个TaskManager必须被启动。然后TaskManager发送一个RegisterTaskManager消息到JobManager注册自己。JobManager发送一条注册成功的确认消息。如果TaskManager已经在JobManager注册过了,因为有多条RegisterTaskManager消息被发送,JobManager返回一条AlreadyRegistered消息。如果注册被拒绝,JobManager将发送一条RefuseRegistration消息。
JobClient通过发送一条附带相应JobGraph的SubmitJob消息提交一个作业给JobManager。一收到JobGraph,JobManager基于JobGraph创建一个ExecutionGraph,它是分布式执行的逻辑表示。ExecutionGraph包含了会被部署到TaskManagers执行的tasks的相关信息。
JobManager的调度器负责在可用的TaskManagers上分配运行slots。在一个TaskManager上分配一个运行slot后,一条附带所有执行task必要信息的SubmitTask消息被发送到该TaskManager。TaskManager发送一条TaskOperationResult消息确认task部署成功。一旦已提交作业的源码被部署和执行,则作业提交成功。JobManager发送一条附带相应作业Id的Success消息通知JobClient作业提交成功。
运行在TaskManagers上的每个task的状态更新通过UpdateTaskExecutionState消息发送回JobManager。有了这些更新消息,ExecutionGraph可以被更新以反映执行的当前状态。
JobManager也作为数据源的输入分片器(input split assigner)。它负责向所有TaskMangers分配任务,以便尽可能保证数据本地性(data locality)。为了动态平衡负载,tasks处理完上一个数据分片(input split)后请求一个新的数据分片。这个请求通过发送一条RequestNextInputSplit给JobManager实现。JobManager返回一条NextInputSplit消息响应。如果没有更多的数据分片,包含在JobManager返回消息中的数据分片为null。
tasks被延迟部署在TaskManagers上。这意味着消费数据的tasks会在它的一个数据生产者(producer)产生数据后被部署。一旦生产者产生数据完成,它发送一条ScheduleOrUpdateConsumers消息给JobManager。这条消息表明消费者(consumer)现在可以读取新产生的数据。如果消费数据的task还没有启动,它将被部署到一个TaskManager上。
-
JobClient
JobClient代表分布式系统中面向用户的组件。它用于和JobManager通信,并且负责提交Flink作业、查询已提交作业的状态和接收运行中作业的状态信息。
JobClient也是一个通过消息通信的actor。存在两种和作业提交相关的消息:SubmitJobDetached和SubmitJobWait。第一个消息提交一个作业并且取消用于接收任何状态消息和最终作业结果的注册。如果你想以一种发送并忽略(fire and forget)的方式提交你的作业到Flink集群, 分离模式(detached mode)很有用。第二种消息提交一个作业并注册以接收这个作业的状态消息。在内部,这通过创建一个helper actor作为状态消息的接收者而实现。一旦作业终止,JobManager发送一个附带运行时长和累计结果的JobResultSuccess消息给helper actor。当收到这个消息的时候,helper actor将这个消息转发给发送SubmitJobWait消息的JobClient,然后终止。
-
Asynchronous VS. Synchronous Messages
在可能的情况下,Flink试图使用异步消息并将响应作为Futures处理。Futures和很少已存的阻塞调用有一个timeout,在timeout之后的操作被认为失败。这避免了在一条消息丢失或一个分布式组件崩溃的情况下系统产生死锁。然而,如果你正好有一个很大的集群或一个很慢的网络,timeouts或许会被错误的触发。因此,这些操作的timeout可以修改在配置
“akka.ask.timeout”中修改。在一个actor可以和另一个actor通信前,它必须查找(retrieve)得到一个ActorRef。这个操作的查找也需要一个timeout。如果一个actor没有启动,为了使系统快速失败,查找的timeout被设置成一个比常规timeout更小的值。在查找timeout的情况下,你可以在配置
“akka.lookup.timeout”中增加查找timeout。Akka的另一个特点是设置了一个它可发送消息大小的最大值限制。原因是它保留了一个同样大小的序列化buffer并且它不想浪费内存。如果你遇到一个消息超出最大值的传输错误,你可以在配置“akka.framesize”中增大帧大小(framesize)。
-
Failure Detection
一个分布式系统中失败检测对于它的鲁棒性(robustness)很重要。当在一个商用集群上运行的时候,分布式系统总会遇到一些组件失败或者不可达。这样一个失败的原因是多种多样的,可以是从硬件故障到网络中断。一个健壮的(robust)分布式系统应当能够检测失败组件并恢复它。
Flink通过Akka的DeathWatch机制检测失败组件。DeathWatch允许actors监视其他actors,即使它们不受这个actor监督或者甚至它们属于另一个actor系统。一旦一个被监视的actor死掉或是不可达,一个终止消息会被发送给这个actor的监视者。因此,一收到这个消息,系统可以对这个actor采取相应措施。在内部,DeathWatch被实现成心跳(heartbeat)和一个基于心跳间隔、心跳暂停、心跳阈值的失败检测器,它判断一个actor什么时候很可能是dead。心跳间隔可以在配置
“akka.watch.heartbeat.interval”中设置。可接受的心跳暂停可以通过配置“akka.watch.heartbeat.pause”确定。心跳暂停应当是心跳间隔的几倍,否则一个丢失的心跳会直接触发DeathWatch。失败(心跳)阈值可以通过配置“akka.watch.threshold”确定,并且它有效地控制失败检测器的敏感度。更多关于DeathWatch机制和失败检测器的细节可以参阅这里。在Flink中,JobManager监视所有已注册的TaskManagers并且所有的TaskManagers监视JobManager。这样,两类组件都知道什么时候另一个组件是不可达的。某个TaskManager不可达的时候,JobManager会将这个不能部署tasks的TaskManager标记为dead。另外,JobManager使运行在这个TaskManager上的所有tasks失败,并且在另一个TaskManager上重新调度执行这些tasks。TaskManager在由于临时连接丢失而被标记为dead的情况下,当连接重新建立的时候,它可以向JobManager重新注册自己。TaskManager也监视JobManager。这个监视允许TaskManager检测到JobManager失败的时候通过使所有正在运行的tasks失败而进入一个清洁的(clean)状态。另外,在只是由于网络拥塞或连接丢失而触发的death情况下,TaskManager将试图重新连接JobManager。
-
Future Development
当前只有三个组件:JobClient、JobManager和TaskManager被实现成actor。为了更好的实现并发性以提高伸缩性,可以将更多的组件实现成actors。一个有希望的候选者是ExecutionGraph,它的ExecutionVertices或者其相关联的Execution对象也可以实现成一个actor。这样一个细粒度的Actor模型将有利于状态更新直接发送各自的Execution对象。这样的话,JobManger将显著地从作为单一的通信节点中解放出来。
-
Configuration
akka.ask.timeout:用于所有Futures和阻塞的Akka调用的timeout。如果Flink由于timeouts而失败,那么你应该增大这个值。timeouts可以由运行慢的机器或者拥塞的网络造成。timeout值需要时间单元标识符(ms/s/min/h/d) ( 默认:10s )
akka.lookup.timeout:用于JobManager查找的timeout。timeout值需要时间单元区分符(ms/s/min/h/d)( 默认:10s ),一般情况下需要设置小于
akka.ask.timeout的值。akka.framesize: JobManager和TaskManager之间发送的消息大小的最大值。如果Flink由于消息大小超出这个限制而失败,那么你应该增大这个值。消息大小需要消息单元标识符。( 默认:10485760 b )
akka.watch.heartbeat.interval:Akka检测dead TaskManager的DeathWatch机制的时间间隔。如果TaskManagers由于丢失或延迟的心跳消息而错误地被标记为dead,那么你应该增大这个值。一个关于Akka的DeathWatch的详细介绍可以在这里找到。(默认:akka.ask.timeout/10)
akka.watch.heartbeat.pause:Akka的DeathWatch机制可接受的心跳暂停值。一个较低的值不允许一个无规律的心跳。一个关于Akka的DeathWatch机制的详细介绍可以在这里找到。(默认:akka.ask.timeout)
akka.watch.threshold:DeathWatch失败检测器的阈值。一个较低的值容易产生错误的判断,反之,一个较大的值增加了检测到dead TaskManager的时间。一个关于Akka的DeathWatch机制的详细介绍可以在这里找到。(默认:12)
注意:参数随着版本都可能变化,请以官网为主。文章来源:https://www.toymoban.com/news/detail-737140.html
参考
[1]【Akka系列】之 Akka和Actors在Flink中的应用
[2]【Akka系列】之 Akka and Actors文章来源地址https://www.toymoban.com/news/detail-737140.html
到了这里,关于Flink消费kafka报akka.pattern.AskTimeoutException: Ask timed out on [Actor[akka.tcp://flink@xxx]]after x的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![流批一体计算引擎-4-[Flink]消费kafka实时数据](https://imgs.yssmx.com/Uploads/2024/02/455176-1.png)