1.摘要
在本文中,我首先对网站常用的反爬虫和反自动化技术做了一个梳理, 并对可能能够绕过这些反爬技术的开源库chromedp所使用的技术分拆做一个介绍, 最后利用chromedp库对一个测试网站做了爬虫测试, 并利用chromedp库绕开了爬虫限制,成功通过程序自动获取到信息。在测试过程中,顺便对chromedp库经常使用的一些API做了一些调用尝试。
2.反爬虫和反自动化技术手段
网站常见的反爬虫和反自动化技术主要包括:
-
用户代理检查 - 主要检查User-Agent字符串,如果不是正常浏览器的则拒绝访问。
-
IP限频 - 同一个IP地址访问过于频繁则会被限制或封禁。
-
缺失字段检测 - 例如使用程序爬取可能会缺失必要的Referer字段,有些网站会检查Referer字段防爬虫。
-
Cookies与会话验证 - 需要验证Cookies或会话信息才能访问。
-
Js执行检测 - 注入各种JavaScript代码检测执行环境。
-
滑动验证码 - 需要用户滑动验证码才能继续操作。
-
Cloudflare防护 - 使用Cloudflare对访问进行监控和风控。
-
动态渲染 - 重要内容使用JS动态渲染,不能直接爬取。
-
监测DOM变化 - 通过MutationObserver监测DOM变化判断是否为自动化程序。
-
加密和反反编译 - 使用加密、混淆代码防止逆向。
-
机器学习检测 - 训练模型检测访问行为是否为Bot。
-
欺骗点击 - 设置假的网页元素迷惑爬虫点击。
-
验证码识别 - 使用验证码技术防止自动提交。
由于每个网站使用的技术可能是以上技术的一种或多种, 有的甚至是自定义的复杂混合检测逻辑, 因此想要绕过反爬,需要动态调整策略。
3.chromedp开源库介绍
Chromedp是一个用Go语言编写的Chrome DevTools Protocol客户端库,用于通过Chrome DevTools Protocol与Chrome/Chromeium进行交互自动化。
Chromedp开源库地址为: https#github.com/chromedp/chromedp (将#替换为://)
Chromed拥有的能力包括:
-
网页自动化 - 可以用来编写爬虫,进行网页数据抓取和提取。
-
UI测试 - 可以基于Chromedp对网页应用进行自动化的UI测试。
-
性能分析 - 利用Chrome的profile和tracing工具做性能分析。
-
调试支持 - 通过devtools协议调试JavaScript、CSS等。
-
截屏和PDF - 可以利用headless chrome进行网页截图和生成PDF。
-
模拟各种用户场景 - 可以模拟不同的用户操作,如:点击、输入、触发事件等。
-
支持移动端 - 可以测试移动网页应用。
-
支持扩展开发 - 可以开发Chrome扩展并进行调试。
Chromedp工作模式是首先在后台启动一个Chrome浏览器实例,并可以选择headless(无头)模式。启动后通过Chrome DevTools Protocol
Headless模式是浏览器的一种运行模式,意为"无头"模式。在这种模式下,浏览器不会有可见的界面,但是内核和所有功能都还存在。浏览器后台以命令行的形式运行,通过代码控制模拟执行各种操作。Headless模式主要特征和优势主要包括: (1).不需要可视化界面,启动时间更快,资源占用更小。 (2).可以在服务器环境无界面运行。 (3).适合用来做自动化测试、爬虫等需要程序化控制浏览器的场景。 (4).测试或爬取的过程不会弹出可见窗口影响使用。 (5).可以方便的集成到持续集成和部署环境中。 (6).支持完整的浏览器功能和兼容性,因为使用的是完整的浏览器内核。 目前流行的Chrome、Firefox、Safari等浏览器都支持Headless模式,在自动化测试和爬虫领域,Headless浏览器已经成为标准工具。
协议与浏览器建立连接, 利用协议中的DOM,Network,Page等域,chromedp可以模拟浏览器的各种行为。例如通过DOM域修改页面DOM;Network域拦截请求;Page域控制页面导航等。当Chrome浏览器接收到chromedp发来的命令后,利用自身浏览器内核(Blink)对页面进行渲染, 渲染后的结果再通过DevTools协议返回给chromedp, chromedp便可以从返回的数据中提取需要的信息, 整个过程与真实用户操作浏览器一致,可以绕过多种反爬手段。同时利用Chrome强大的渲染引擎,可以处理各种复杂页面。
4.使用chromedp测试
我这里通过chromedp解决的问题是一个yml格式的资源, 在chrome浏览器中直接请求该资源可以正常返回内容,如图:

接着我使用Go语言的标准库来请求该URL, Go语言HTTP请求的方式主要有两种:
第一: 直接使用http.Get(url)
从实际的返回中可以发现, 请求目标URL超时了, 报了"dial tcp xxx:443 I/O timeout"错误, 如图:

第二: 使用http.NewRequest和Do()的组合
从实际返回中可以发现,和上面错误一样:

第三: 使用chromedp库测试
使用chromedp库,首先启动一个无头Chrome浏览器实例:
ctx, cancel := chromedp.NewContext(context.Background())
defer cancel()然后调用方法打开指定的网页:
var content string
err = chromedp.Run(ctx,
chromedp.Navigate(interfaceUrl),
chromedp.WaitVisible(`body`, chromedp.ByQuery),
chromedp.OuterHTML(`html`, &content, chromedp.ByQuery),
)其中, content变量中保存了爬取后获取的页面内容。
由于获取到的内容格式是一个完整的html页面格式,例如:
<html><body>页面内容</body></html>因此要获取到页面内容,需要对内容进行提取,以下是我根据返回的具体内容写的提取方法:
idx1 := strings.Index(content, "<body><pre style=\"word-wrap: break-word; white-space: pre-wrap;\">")
idx2 := strings.Index(content, "</body>")
yamlContent := content[idx1+len("<body><pre style=\"word-wrap: break-word; white-space: pre-wrap;\">") : idx2]
var data map[string]interface{}
err = yaml.Unmarshal([]byte(yamlContent), &data)
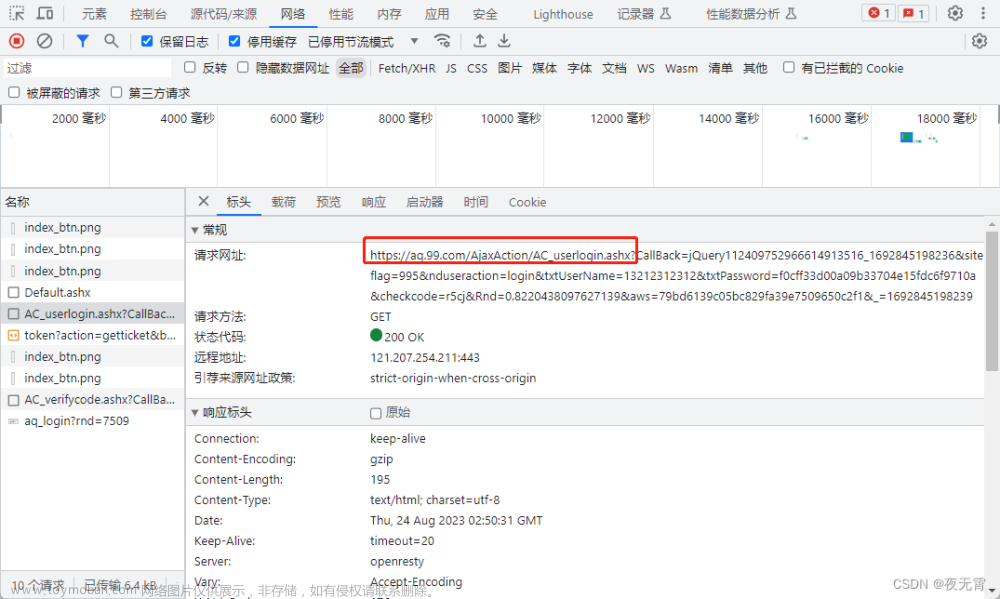
freeNodes := data["proxies"].([]interface{})上面的变量yamlContent就是过滤后获取到的真正内容, 然后就可以放心的将该内容反序列化到map,以下是我通过chromedp成功获取到内容的调试界面:文章来源:https://www.toymoban.com/news/detail-737506.html
 文章来源地址https://www.toymoban.com/news/detail-737506.html
文章来源地址https://www.toymoban.com/news/detail-737506.html
到了这里,关于绕开网站反爬虫原理及实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!




![[爬虫]解决机票网站文本混淆问题-实战讲解](https://imgs.yssmx.com/Uploads/2024/02/528622-1.png)