解释
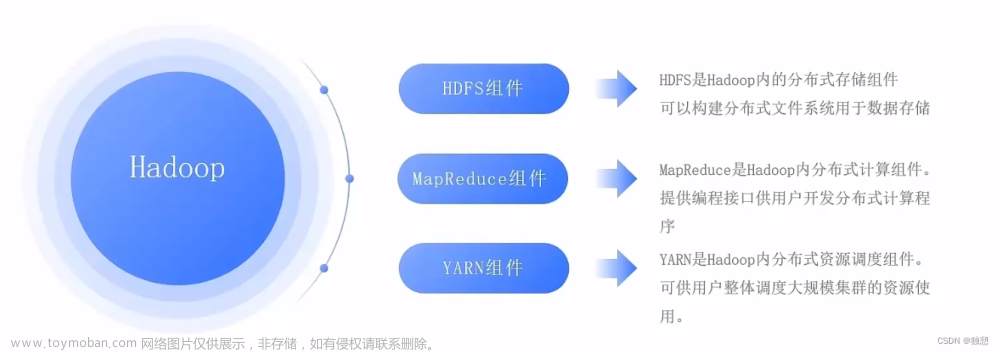
viewfs:// 是 Hadoop 中的一个特殊文件系统 URI,用于访问 Hadoop 的视图文件系统(ViewFS)。
ViewFS 是 Hadoop 提供的一种虚拟文件系统,它可以将来自多个底层文件系统的文件统一管理和访问。
通过 ViewFS,你可以在不知道底层真实文件系统细节的情况下,对文件进行读取和写入操作。
要使用 viewfs://,你需要了解以下几个步骤:
配置 ViewFS:在 Hadoop 集群中的配置文件(如 core-site.xml)中,需要设置 ViewFS 相关的属性,包括视图文件系统的名称空间和底层真实文件系统的映射关系。
使用Java
创建 ViewFS 实例:在代码中,你可以使用 Hadoop 的 API 来创建 ViewFS 的实例,以便进行文件操作。以下是一个 Java 示例代码:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
...
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "viewfs://<viewfs-namespace>/");
FileSystem fs = FileSystem.get(conf);
// 使用 fs 进行文件操作,例如读取或写入文件等
Path filePath = new Path("/path/to/file");
fs.open(filePath);
...
其中, 是视图文件系统的命名空间,你需要替换为你实际配置的值。
使用 ViewFS 进行文件操作:通过获取到的 ViewFS 实例,你可以使用 Hadoop 提供的文件系统 API,如 FileSystem 类的方法(如 open()、create()、delete() 等),来对文件进行读取和写入操作。
需要注意的是,使用 ViewFS 需要正确配置底层真实文件系统的权限和访问控制,以确保文件操作的安全性和正确性。
总之,viewfs:// 是 Hadoop 中用于访问视图文件系统的 URI,通过配置和使用 Hadoop 的 API,你可以使用 ViewFS 对多个底层文件系统进行统一管理和访问。
使用Shell
在 shell 脚本中,你可以使用 Hadoop 提供的命令行工具来操作 ViewFS。以下是一些常用的命令及其示例:
查看 ViewFS 中的文件列表:
hadoop fs -ls viewfs://<viewfs-namespace>/
其中, 是你实际配置的视图文件系统的命名空间。
从 ViewFS 中拷贝文件到本地:
hadoop fs -copyToLocal
viewfs://<viewfs-namespace>/path/to/source
/path/to/destination
其中,path/to/source 是 ViewFS 中要拷贝的文件路径,/path/to/destination 是本地目标路径。
在 ViewFS 中创建目录:
hadoop fs -mkdir viewfs://<viewfs-namespace>/path/to/new/directory
其中,path/to/new/directory 是你要创建的目录路径,如果需要递归创建多级目录,可以使用 -p 参数。
在 ViewFS 中删除文件:
hadoop fs -rm viewfs://<viewfs-namespace>/path/to/file
其中,path/to/file 是要删除的文件路径,如果需要删除目录及其中的所有文件和子目录,可以使用 -r 参数。文章来源:https://www.toymoban.com/news/detail-738664.html
需要注意的是,在 shell 脚本中使用 ViewFS 命令时,需要确保 ViewFS 已经正确配置,并且相关的 Hadoop 环境变量已经设置(例如 HADOOP_HOME、HADOOP_CONF_DIR 等)。文章来源地址https://www.toymoban.com/news/detail-738664.html
基本操作
- 判断目录是否存在
if ! hadoop fs -test -d viewfs://<viewfs-namespace>/path/to/directory; then
hadoop fs -mkdir viewfs://<viewfs-namespace>/path/to/directory
fi
- 判断文件是否存在
if ! hadoop fs -test -e viewfs://<viewfs-namespace>/path/to/file; then
hadoop fs -touchz viewfs://<viewfs-namespace>/path/to/file
fi
- 改名
hadoop fs -mv
viewfs://<viewfs-namespace>/path/to/oldfile
viewfs://<viewfs-namespace>/path/to/newfile
到了这里,关于viewfs://为Hadoop 中的一个特殊文件系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!