一、滚动查询
参考: 中国开源社区
/**
* 滚动查询, 并批量保存
*
* @param indexName
* @return
*/
public int scrollIndexName(String indexName) {
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.withQuery(QueryBuilders.matchAllQuery()).build();
// 滚动一次数据量为1w
searchQuery.setMaxResults(10000);
// 第一次查询
SearchScrollHits<RawDocDO> searchScrollHits = elasticsearchRestTemplate.searchScrollStart(60000, searchQuery, RawDocDO.class, IndexCoordinates.of(indexName));
String scrollId = searchScrollHits.getScrollId();
List<RawDocDO> rawDocDOList = new ArrayList<>();
for (SearchHit<RawDocDO> searchHit : searchScrollHits.getSearchHits()) {
RawDocDO content = searchHit.getContent();
rawDocDOList.add(content);
}
String replace = indexName.replace("index", "latest");
// 创建索引结构
createIndex(replace, indexName.substring(6, 8));
// 批量插入数据
bulkIndexName(rawDocDOList, replace);
// 批量创建总数
int count = rawDocDOList.size();
Long temp = searchScrollHits.getTotalHits();
temp -= 10000;
List<String> scrollIdList = new ArrayList<>();
scrollIdList.add(scrollId);
// 循环滚动插入
while (temp > 0) {
// 继续滚动
searchScrollHits = elasticsearchRestTemplate.searchScrollContinue(scrollId, 60000, RawDocDO.class, IndexCoordinates.of(indexName));
List<RawDocDO> rawDocDOList2 = new ArrayList<>();
for (SearchHit<RawDocDO> searchHit : searchScrollHits.getSearchHits()) {
RawDocDO content = searchHit.getContent();
rawDocDOList2.add(content);
}
// 批量插入数据
bulkIndexName(rawDocDOList2, replace);
// 累加
count += rawDocDOList2.size();
scrollId = searchScrollHits.getScrollId();
temp -= 10000;
}
logger.info("批量插入{}条数据到{}索引中", rawDocDOList.size(), replace);
scrollIdList.add(scrollId);
// 清除 scroll
elasticsearchRestTemplate.searchScrollClear(scrollIdList);
return count;
}
二、设置权重
- 官方介绍
- ES 的权重排序
- 【Elasticsearch】ElasticSearch 7.8 多字段权重排序
三、动态模板
1、基本概念
- ElasticSearch7.3学习(十三)----定制动态映射(dynamic mapping)
- 【Elasticsearch教程4】Mapping 动态映射
- 【Elasticsearch教程5】Mapping 动态模板 Dynamic templates
2、原生创建动态模板
#删除已有index
DELETE my_index
# 创建dynamic_templates,以is开头的被识别为boolean类型,string类型匹配为keyword类型
PUT my_index
{
"mappings": {
"dynamic_templates": [
{
"strings_as_boolean": {
"match_mapping_type": "string",
"match":"is*",
"mapping": {
"type": "boolean"
}
}
},
{
"strings_as_keywords": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
3、ElasticSearch-data整合springboot创建
注意事项:需要先创建模板,然后添加数据,新增的数据则会按照模板的格式来创建。如果直接设置了索引的mapping,则模板映射会失效,模板是用户添加数据时候自动给属性添加映射类型。
- 在resource目录下新建template-mapping.json
{
"dynamic_templates": [
{
"content": {
"match": "content",
"mapping": {
"analyzer": "standard",
"search_analyzer": "english"
}
}
},
{
"title": {
"match": "title",
"mapping": {
"analyzer": "standard",
"search_analyzer": "english"
}
}
},
{
"summary": {
"match": "summary",
"mapping": {
"analyzer": "standard",
"search_analyzer": "english"
}
}
}
]
}
- 定义实体对象
package com.tmxbase.psas.dal.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.*;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
@Document(indexName = "#{@esAttribute.indexName}", replicas = 0, shards = 5)
//@Mapping(mappingPath = "/raw-doc-mapping.json")
//@DynamicTemplates(mappingPath = "/raw-doc-templates.json")
@Setting(settingPath = "/rawDoc-setting.json")
public class RawDocDO implements Serializable {
// 字段
public static final String ENTRY_ID_FIELD = "_id";
@Id
private String docId; // 数据id
@Field(type = FieldType.Text, analyzer = "ik_smart", termVector = TermVector.with_positions_offsets, similarity = Similarity.BM25, fielddata = true)
private String summary; // 文章摘要
@Field(type = FieldType.Text, analyzer = "ik_smart", termVector = TermVector.with_positions_offsets, similarity = Similarity.BM25, fielddata = true)
private String content; // 文章内容
@Field(type = FieldType.Text, analyzer = "ik_smart", termVector = TermVector.with_positions_offsets, similarity = Similarity.BM25, fielddata = true)
private String title; // 文章标题
@Field(type = FieldType.Keyword)
private String media; // 媒体类型
@Field(type = FieldType.Byte)
private byte emotion; // 文章情感类型 positive=3 neutral=2 negative=1
private String lan; // 文章所属语言
@Field(type = FieldType.Keyword, index = false)
private String href; // 文章来源页
@Field(type = FieldType.Keyword)
private String country; // 文章来源国家
@Field(type = FieldType.Date, format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
private String time; // 文章发布时间
}
四、分词器
- Lucene中常用的几个分词器
- ES之分词以及各大分词器
- ES-文本分析(analysis)
- Elasticsearch分词器简介与使用(一)
1、内置的分词器
(1)ES的内置分词器如下:
| 分词器 | 描述 |
|---|---|
| Standard Analyzer | ES的标准分词器,主要用于英文分词 |
| Simple Analyzer | 简单分词器,按非英文字母进行分词,同时转化成小写字母 |
| Whitespace Analyzer | 空格分词器,按空格分词 |
| Stop Analyzer | 类似于Simple Analyzer,但是增加了停顿词功能 |
| Keyword Analyzer | 关键词分词器 |
| Pattern Analyzer | 正则分词器,支持停顿词 |
| Language Analyzer | 针对特定语言的分词器 |
| Fingerprint Analyzer | 指纹分词器,通过创建标记进行重复检测 |
内置的分词器一般用于简单的测试,或者简单常规要求的英文文档索引。
(2)内置分词器设置禁用词
- 在elasticSearch配置文件config目录下,添加stopWord.txt文件。
- 在添加索引setting时候,加入配置

2、IK分词器使用
ES如果需要索引中文内容,则使用最多的分词器就是IK分词器了。github地址:https://github.com/medcl/elasticsearch-analysis-ik
IK_smart设置禁用词

ik分词器设置禁用词与默认的分词器设置有所不同。
-
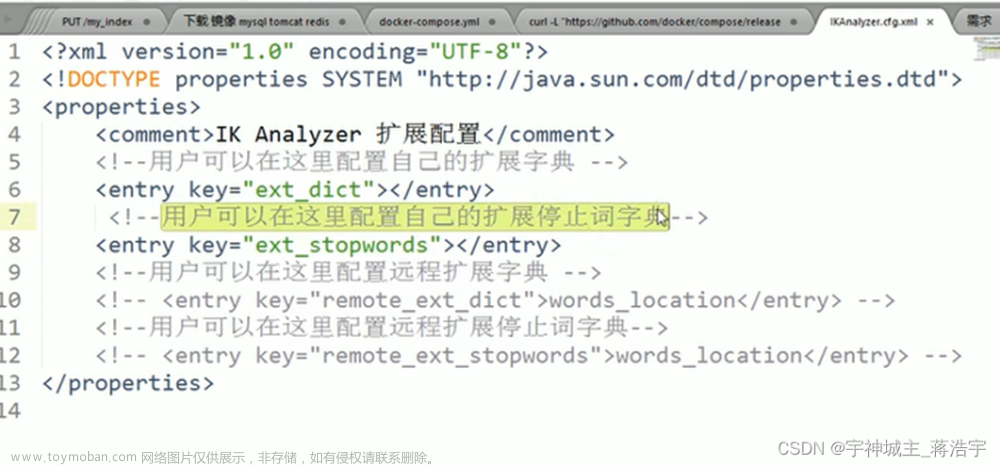
在 elasticsearch-7.x.x\plugins\ik\config\ 目录下,打开目录可以看到有 stopword.dic 和 extra_stopword.dic 两个文件。stopword.dic 里面的为配置的英文停用词,extra_stopword.dic 里面为配置的中文停用词。
-
默认是使用 stopword.dic 的,想要使用 extra_stopword.dic 的话是需要在 ik 中进行配置的,配置文件为 IKAnalyzer.cfg.xml

(3) 配置完成后重启 elasticsearch,就可以发现停用词已经不再对搜索产生影响了。
3、 安装其他分词器
安装越南语分词器
五、路由Routing
代写…
六、聚合分组查询
待写…
七、动态的为ElasticSearch的@Document指定index
1.在配置文件里设置indexName(只能设置一个indexName)
创建配置Bean:
@Component("esAttribute")
// 指定配置文件
@PropertySource("classpath:application.properties")
public class EsAttribute {
@Value("${index.name}")
private String indexName;
public String getIndexName() {
return indexName;
}
public void setIndexName(String indexName) {
this.indexName = indexName;
}
}
在application.properties中添加:
index.name=tomcat1-*
在ElasticSearch返回的类型中使用:
@Data
@NoArgsConstructor
@Accessors(chain = true)
@Document(indexName = "#{@esAttribute.indexName}", shards = 1, replicas = 0,createIndex = true)
public class AppLogBean implements Serializable {
private static final long serialVersionUID = -729624360020627702L;
@Id
private String id;
@Field(type = FieldType.Keyword)
private String customer_time;
}
在操作过程中可能会报这个错误:java.lang.IllegalArgumentException: Could not resolve placeholder ‘index.name’ in value "${index.name}
原因可能是使用@Value的类上未指定配置文件:@PropertySource("classpath:application.properties")
也可能是你的配置文件是yml类型,而该注解只支持properties文件引入,并不支持yml,至于如何让其可以加载yml文件,自行搜索。
2.在代码中设置indexName(可以根据条件设置不同的indexName)
创建配置Bean:
@Component("esAttribute")
public class EsAttribute {
private String indexName;
public String getIndexName() {
return indexName;
}
public void setIndexName(String indexName) {
this.indexName = indexName;
}
}
在你需要的地方设置indexName:
@Autowired
private EsAttribute esAttribute;
// 动态设置索引名称
esAttribute.setIndexName("tomcat1-*");
logger.info("索引名称indexName:" + esAttribute.getIndexName());
在ElasticSearch返回的类型中使用:文章来源:https://www.toymoban.com/news/detail-738704.html
@Data
@NoArgsConstructor
@Accessors(chain = true)
@Document(indexName = "#{@esAttribute.indexName}", shards = 1, replicas = 0,createIndex = true)
public class AppLogBean implements Serializable {
private static final long serialVersionUID = -729624360020627702L;
@Id
private String id;
@Field(type = FieldType.Keyword)
private String customer_time;
}
八、ES嵌套类型
1、Nested
ES嵌套(Nested)文档使用文章来源地址https://www.toymoban.com/news/detail-738704.html
- ES中 Nested 类型的原理和使用
- Elasticsearch Nested类型及应用【2】
2、父子文档
- ElasticSearch(四):ES nested嵌套文档与父子文档处理
- elasticsearch之嵌套对象、父子文档
到了这里,关于Elastic Search一些用法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!