在本篇文章中,我们全面而深入地探讨了强化学习(Reinforcement Learning)的基础概念、主流算法和实战步骤。从马尔可夫决策过程(MDP)到高级算法如PPO,文章旨在为读者提供一套全面的理论框架和实用工具。同时,我们还专门探讨了强化学习在多个领域,如游戏、金融、医疗和自动驾驶等的具体应用场景。每个部分都提供了详细的Python和PyTorch代码示例,以助于更好地理解和应用这些概念。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、引言

强化学习(Reinforcement Learning, RL)是人工智能(AI)和机器学习(ML)领域的一个重要子领域,与监督学习和无监督学习并列。它模仿了生物体通过与环境交互来学习最优行为的过程。与传统的监督学习不同,强化学习没有事先标记好的数据集来训练模型。相反,它依靠智能体(Agent)通过不断尝试、失败、适应和优化来学习如何在给定环境中实现特定目标。
强化学习的核心组成
强化学习的框架主要由以下几个核心组成:
-
状态(State):反映环境或系统当前的情况。
-
动作(Action):智能体在特定状态下可以采取的操作。
-
奖励(Reward):一个数值反馈,用于量化智能体采取某一动作后环境的反应。
-
策略(Policy):一个映射函数,指导智能体在特定状态下应采取哪一动作。
这四个元素共同构成了马尔可夫决策过程(Markov Decision Process, MDP),这是强化学习最核心的数学模型。
为什么强化学习重要?

实用性与广泛应用
强化学习的重要性首先体现在其广泛的应用价值。从自动驾驶、游戏AI、到量化交易、工业自动化,以及近年来在自然语言处理、推荐系统等方面的突破,强化学习都发挥着不可或缺的角色。
自适应与优化
传统的算法往往是静态的,即它们没有能力去适应不断变化的环境或参数。而强化学习算法则可以不断地适应和优化,这使它们能在更加复杂和动态的环境中表现出色。
推动AI研究前沿
强化学习也在推动人工智能的研究前沿,特别是在解决一些需要长期规划和决策的复杂问题上。例如,强化学习已成功地应用于围棋算法AlphaGo中,击败了人类世界冠军,这标志着AI在执行复杂任务方面取得了重大突破。
引领伦理与社会思考
随着强化学习在自动决策系统中的应用越来越广泛,如何设计公平、透明和可解释的算法也引发了众多伦理和社会问题,这需要我们更加深入地去探索和理解强化学习的各个方面。

二、强化学习基础
强化学习的核心是建模决策问题,并通过与环境的交互来学习最佳决策方案。这一过程常常是通过马尔可夫决策过程(Markov Decision Process, MDP)来描述和解决的。在本节中,我们将详细地探讨马尔可夫决策过程以及其核心组件:奖励、状态、动作和策略。
马尔可夫决策过程(MDP)

MDP是用来描述决策问题的数学模型,主要由一个四元组 ( (S, A, R, P) ) 组成。
-
状态空间(S): 表示所有可能状态的集合。
-
动作空间(A): 表示在特定状态下可能采取的所有动作的集合。
-
奖励函数(R): ( R(s, a, s') ) 表示在状态 ( s ) 下采取动作 ( a ) 并转移到状态 ( s' ) 时所获得的即时奖励。
-
转移概率(P): ( P(s' | s, a) ) 表示在状态 ( s ) 下采取动作 ( a ) 转移到状态 ( s' ) 的概率。
状态(State)
在MDP中,状态是用来描述环境或问题的现状。在不同应用中,状态可以有很多种表现形式:
- 在棋类游戏中,状态通常表示棋盘上各个棋子的位置。
- 在自动驾驶中,状态可能包括车辆的速度、位置、以及周围对象的状态等。
动作(Action)
动作是智能体(Agent)在某一状态下可以采取的操作。动作会影响环境,并可能导致状态的转变。
- 在股市交易中,动作通常是“买入”、“卖出”或“持有”。
- 在游戏如“超级马里奥”中,动作可能包括“跳跃”、“下蹲”或“向前移动”等。
奖励(Reward)
奖励是一个数值反馈,用于评估智能体采取某一动作的“好坏”。通常,智能体的目标是最大化累积奖励。
- 在迷宫问题中,到达目的地可能会得到正奖励,而撞到墙壁则可能会得到负奖励。
策略(Policy)
策略是一个从状态到动作的映射函数,用于指导智能体在每一状态下应采取哪一动作。形式上,策略通常表示为 ( \pi(a|s) ),代表在状态 ( s ) 下采取动作 ( a ) 的概率。
- 在游戏如“五子棋”中,策略可能是一个复杂的神经网络,用于评估每一步棋的优劣。
通过优化策略,我们可以使智能体在与环境的交互中获得更高的累积奖励,从而实现更优的性能。
三、常用强化学习算法

强化学习拥有多种算法,用于解决不同类型的问题。在本节中,我们将探讨几种常用的强化学习算法,包括他们的工作原理、意义以及应用实例。
值迭代(Value Iteration)
算法描述
值迭代是一种基于动态规划(Dynamic Programming)的方法,用于计算最优策略。主要思想是通过迭代更新状态值函数(Value Function)来找到最优策略。
算法意义
值迭代算法主要用于解决具有完全可观测状态和已知转移概率的MDP问题。它是一种“模型已知”的算法。
应用实例
值迭代经常用于路径规划、游戏(如迷宫问题)等环境中,其中所有状态和转移概率都是已知的。
Q学习(Q-Learning)
算法描述
Q学习是一种基于值函数的“模型无知”算法。它通过更新Q值(状态-动作值函数)来找到最优策略。
算法意义
Q学习算法适用于“模型无知”的场景,也就是说,智能体并不需要知道环境的完整信息。因此,Q学习特别适用于现实世界的问题。
应用实例
Q学习广泛用于机器人导航、电子商务推荐系统以及多玩家游戏等。
Policy Gradients(策略梯度)
算法描述
与基于值函数的方法不同,策略梯度方法直接在策略空间中进行优化。算法通过计算梯度来更新策略参数。
算法意义
策略梯度方法特别适用于处理高维或连续的动作和状态空间,而这些在基于值的方法中通常很难处理。
应用实例
策略梯度方法在自然语言处理(如机器翻译)、连续控制问题(如机器人手臂控制)等方面有广泛应用。
Actor-Critic(演员-评论家)
算法描述
Actor-Critic 结合了值函数方法和策略梯度方法的优点。其中,"Actor" 负责决策,"Critic" 负责评价这些决策。
算法意义
通过结合值函数和策略优化,Actor-Critic 能在各种不同的环境中实现更快和更稳定的学习。
应用实例
在自动驾驶、资源分配和多智能体系统等复杂问题中,Actor-Critic 方法被广泛应用。
四、PPO(Proximal Policy Optimization)算法

PPO是一种高效、可靠的强化学习算法,属于策略梯度家族的一部分。由于其高效和稳定的性质,PPO算法在各种强化学习任务中都有广泛的应用。
与强化学习的关系
PPO是用于解决马尔可夫决策过程(MDP)问题的算法。它通过优化策略(Policy)来让智能体在不同状态下选择最优动作,从而最大化预期的累积奖励。
原理
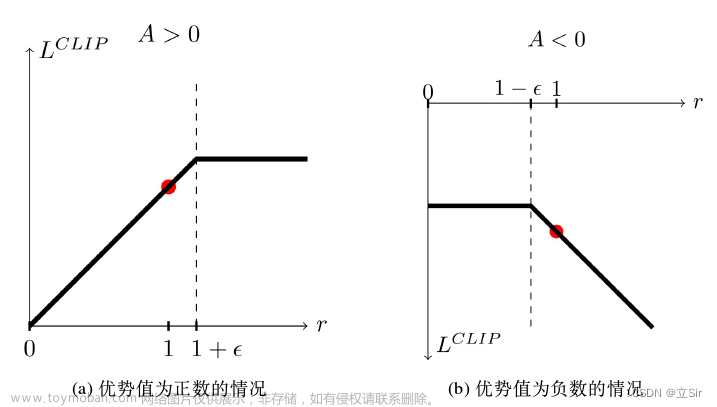
PPO的核心思想是通过限制策略更新的步长来避免太大的性能下降。这是通过引入一种特殊的目标函数实现的,该目标函数包含一个剪辑(Clipping)项来限制策略的改变程度。
具体的目标函数如下:

细节
-
多步优势估计: PPO通常与多步回报(Multi-Step Return)和优势函数(Advantage Function)结合使用,以减少估计误差。
-
自适应学习率: PPO通常使用自适应学习率和高级优化器(如Adam)。
-
并行采样: 由于PPO是一种“样本高效”的算法,通常与并行环境采样结合使用,以进一步提高效率。
代码举例
下面是使用Python和PyTorch实现PPO的简单示例:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义策略网络
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(PolicyNetwork, self).__init__()
self.fc = nn.Linear(state_dim, 128)
self.policy_head = nn.Linear(128, action_dim)
def forward(self, x):
x = torch.relu(self.fc(x))
return torch.softmax(self.policy_head(x), dim=-1)
# 初始化
state_dim = 4 # 状态维度
action_dim = 2 # 动作维度
policy_net = PolicyNetwork(state_dim, action_dim)
optimizer = optim.Adam(policy_net.parameters(), lr=1e-3)
epsilon = 0.2
# 采样数据(这里假设有一批样本数据)
states = torch.rand(10, state_dim)
actions = torch.randint(0, action_dim, (10,))
advantages = torch.rand(10)
# 计算旧策略的动作概率
with torch.no_grad():
old_probs = policy_net(states).gather(1, actions.unsqueeze(-1)).squeeze()
# PPO更新
for i in range(4): # Typically we run multiple epochs
action_probs = policy_net(states).gather(1, actions.unsqueeze(-1)).squeeze()
ratio = action_probs / old_probs
surr1 = ratio * advantages
surr2 = torch.clamp(ratio, 1-epsilon, 1+epsilon) * advantages
loss = -torch.min(surr1, surr2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("PPO Update Done!")
这只是一个非常基础的示例,实际应用中还需要包括更多元素,如状态标准化、网络结构优化等。
五、强化学习实战

5.1 模型创建
在强化学习实战中,模型创建是第一步也是至关重要的一步。通常,这一阶段包括环境设置、模型架构设计和数据预处理等。以下是一个使用PyTorch实现强化学习模型的示例,这里我们使用一个简单的CartPole环境作为案例。
环境设置
首先,我们需要安装必要的库并设置环境。
pip install gym
pip install torch
接着,我们将导入这些库:
import gym
import torch
import torch.nn as nn
import torch.optim as optim
创建Gym环境
使用OpenAI的Gym库,我们可以方便地创建CartPole环境:
env = gym.make('CartPole-v1')
模型架构
接下来,我们设计一个简单的神经网络来作为策略网络。该网络将接收环境状态作为输入,并输出各个动作的概率。
class PolicyNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, output_dim)
def forward(self, state):
x = torch.relu(self.fc1(state))
action_probs = torch.softmax(self.fc2(x), dim=-1)
return action_probs
初始化模型和优化器
在定义了模型架构之后,我们需要对其进行初始化,并选择一个优化器。
input_dim = env.observation_space.shape[0] # 状态空间维度
output_dim = env.action_space.n # 动作空间大小
policy_net = PolicyNetwork(input_dim, output_dim)
optimizer = optim.Adam(policy_net.parameters(), lr=1e-2)
5.2 模型评估
模型评估通常包括在一系列测试环境下进行模拟运行,以及计算各种性能指标。
测试环境运行
以下代码展示了如何在Gym的CartPole环境中测试训练好的模型:
def evaluate_policy(policy_net, env, episodes=10):
total_rewards = 0
for i in range(episodes):
state = env.reset()
done = False
episode_reward = 0
while not done:
state_tensor = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
action_probs = policy_net(state_tensor)
action = torch.argmax(action_probs).item()
next_state, reward, done, _ = env.step(action)
episode_reward += reward
state = next_state
total_rewards += episode_reward
average_reward = total_rewards / episodes
return average_reward
# 使用上文定义的PolicyNetwork和初始化的env
average_reward = evaluate_policy(policy_net, env)
print(f"Average reward over {episodes} episodes: {average_reward}")
性能指标
性能指标可能包括平均奖励、方差、最大/最小奖励等。这些指标有助于我们了解模型在不同情况下的稳定性和可靠性。
# 在这里,我们已经计算了平均奖励
# 在更复杂的场景中,你可能还需要计算其他指标,如奖励的标准差等。
5.3 模型上线
模型上线通常包括模型的保存、加载和实际环境中的部署。
模型保存和加载
PyTorch提供了非常方便的API来保存和加载模型。
# 保存模型
torch.save(policy_net.state_dict(), 'policy_net_model.pth')
# 加载模型
loaded_policy_net = PolicyNetwork(input_dim, output_dim)
loaded_policy_net.load_state_dict(torch.load('policy_net_model.pth'))
部署到实际环境
模型部署的具体步骤取决于应用场景。在某些在线系统中,可能需要将PyTorch模型转换为ONNX或TensorRT格式以提高推理速度。
# 示例:将PyTorch模型转为ONNX格式
dummy_input = torch.randn(1, input_dim)
torch.onnx.export(policy_net, dummy_input, "policy_net_model.onnx")
总结
强化学习(Reinforcement Learning, RL)是人工智能中最具潜力和挑战性的研究方向之一。通过本篇文章,我们深入探讨了强化学习的核心概念,包括马尔可夫决策过程(Markov Decision Processes, MDP)以及其中的奖励、状态、动作和策略等要素。我们还介绍了多种主流的强化学习算法,如Q-Learning, DQN, 和PPO等,每一种算法都有其独特的优点和应用场景。
在强化学习实战部分,我们以CartPole环境为例,从模型创建到模型评估和上线,全方位地讲解了一个完整的RL项目的实施步骤。我们还提供了详尽的PyTorch代码示例和解释,帮助读者更好地理解和应用这些概念。
强化学习不仅在理论研究中占有重要地位,也在实际应用,如自动驾驶、金融交易和医疗诊断等多个领域有着广泛的应用前景。然而,强化学习也面临多个挑战,包括但不限于数据稀疏性、训练不稳定和环境模拟等。因此,掌握强化学习的基础知识和实战经验,将为解决这些复杂问题提供有力的工具和视角。文章来源:https://www.toymoban.com/news/detail-738713.html
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。文章来源地址https://www.toymoban.com/news/detail-738713.html
到了这里,关于一文读懂强化学习:RL全面解析与Pytorch实战的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!