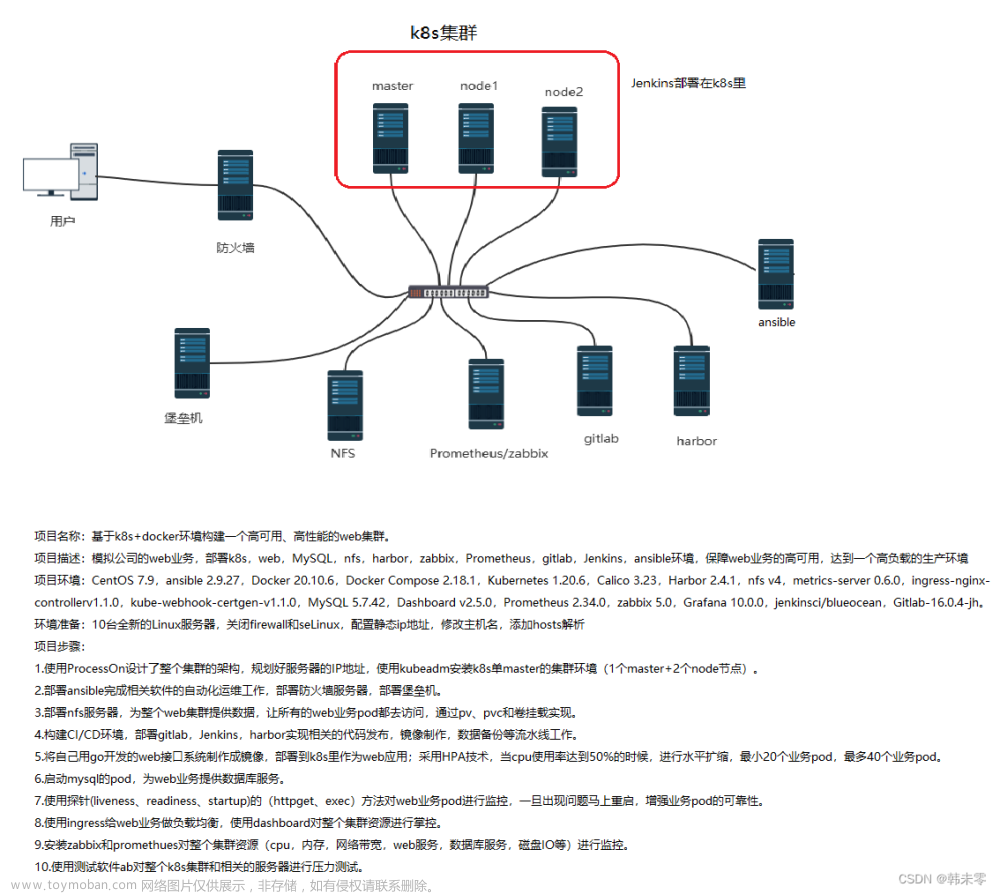
1、创建Headless Service服务
Headless 服务类型并不分配容器云虚拟 IP,而是直接暴露所属 Pod 的 DNS 记录。没有默认负载均衡器,可直接访问 Pod IP 地址。因此,当我们需要与集群内真实的 Pod IP 地址进行直接交互时,Headless 服务就很有用。
其中Service的关键配置如下:clusterIP: None,不让其获取clusterIP , DNS解析的时候直接走pod。
---
kind: Service
apiVersion: v1
metadata:
name: ecc-spark-service
namespace: ecc-spark-cluster
spec:
clusterIP: None
ports:
- port: 7077
protocol: TCP
targetPort: 7077
name: spark
- port: 10000
protocol: TCP
targetPort: 10000
name: thrift-server-tcp
- port: 8080
targetPort: 8080
name: http
- port: 45970
protocol: TCP
targetPort: 45970
name: thrift-server-driver-tcp
- port: 45980
protocol: TCP
targetPort: 45980
name: thrift-server-blockmanager-tcp
- port: 4040
protocol: TCP
targetPort: 4040
name: thrift-server-tasks-tcp
selector:
app: ecc-spark-service
EOF
Service的完全域名: ecc-spark-service.ecc-spark-cluster.svc.cluster.local
headless service的完全域名: headless-service.ecc-spark-cluster.svc.cluster.local
在容器里面ping 完全域名, service解析出的地址是clusterIP,headless service 解析出来的地址是 pod IP。
2、构建spark集群
2.1 、创建spark master
spark master分为两个部分,一个是类型为ReplicationController的主体,命名为ecc-spark-master.yaml,另一部分为一个service,暴露master的7077端口给slave使用。
#如下是把thriftserver部署在master节点,则需要暴露thriftserver端口、driver端口、
#blockmanager端口服务,以提供worker节点executor与driver交互.
cat >ecc-spark-master.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:
name: ecc-spark-master
namespace: ecc-spark-cluster
labels:
app: ecc-spark-master
spec:
replicas: 1
selector:
matchLabels:
app: ecc-spark-master
template:
metadata:
labels:
app: ecc-spark-master
spec:
serviceAccountName: spark-cdp
securityContext: {}
dnsPolicy: ClusterFirst
hostname: ecc-spark-master
containers:
- name: ecc-spark-master
image: spark:3.4.1
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args: ["-c","sh /opt/spark/sbin/start-master.sh && tail -f /opt/spark/logs/spark--org.apache.spark.deploy.master.Master-1-*"]
ports:
- containerPort: 7077
- containerPort: 8080
volumeMounts:
- mountPath: /opt/usrjars/
name: ecc-spark-pvc
livenessProbe:
failureThreshold: 9
initialDelaySeconds: 2
periodSeconds: 15
successThreshold: 1
tcpSocket:
port: 8080
timeoutSeconds: 10
resources:
requests:
cpu: "2"
memory: "6Gi"
limits:
cpu: "2"
memory: "6Gi"
- env:
- SPARK_LOCAL_DIRS
value: "/odsdata/sparkdirs/"
volumes:
- name: ecc-spark-pvc
persistentVolumeClaim:
claimName: ecc-spark-pvc-static
2.2、创建spark worker
在启动spark worker脚本中需要传入master的地址,在容器云kubernetes dns且设置了service的缘故,可以通过ecc-spark-master.ecc-spark-cluster.svc.cluster.local:7077访问。
cat >ecc-spark-worker.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:
name: ecc-spark-worker
namespace: ecc-spark-cluster
labels:
app: ecc-spark-worker
spec:
replicas: 1
selector:
matchLabels:
app: ecc-spark-worker
template:
metadata:
labels:
app: ecc-spark-worker
spec:
serviceAccountName: spark-cdp
securityContext: {}
dnsPolicy: ClusterFirst
hostname: ecc-spark-worker
containers:
- name: ecc-spark-worker
image: spark:3.4.1
imagePullPolicy: IfNotPresent
command: ["/bin/sh"]
args: ["-c","sh /opt/spark/sbin/start-worker.sh spark://ecc-spark-master.ecc-spark-cluster.svc.cluster.local:7077;tail -f /opt/spark/logs/spark--org.apache.spark.deploy.worker.Worker*"]
ports:
- containerPort: 8081
volumeMounts:
- mountPath: /opt/usrjars/
name: ecc-spark-pvc
resources:
requests:
cpu: "2"
memory: "2Gi"
limits:
cpu: "2"
memory: "4Gi"
- env:
- SPARK_LOCAL_DIRS
value: "/odsdata/sparkdirs/"
volumes:
- name: ecc-spark-pvc
persistentVolumeClaim:
claimName: ecc-spark-pvc-static
EOF
2.3 构建pyspark提交环境
import json
import flask
from flask import Flask
from concurrent.futures import ThreadPoolExecutor
app = Flask(__name__)
pool = ThreadPoolExecutor(max_workers=8)
@app.route('/')
def hello_world(): # put application's code here
return 'Hello World!'
@app.route('/downloadCode', methods=['post'])
def download_file():
model_id = flask.request.json.get('modelId')
print(model_id)
"""
异步提交任务:pool.submit()
"""
return json.dumps(0, ensure_ascii=False)
@app.route('/modelRun', methods=['post'])
def model_run():
"""
异步提交任务:pool.submit()
"""
return json.dumps(0, ensure_ascii=False)
if __name__ == '__main__':
app.run()
spark@c67e6477b2f1:/opt/spark$ python3
Python 3.8.10 (default, May 26 2023, 14:05:08)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>>
将python的调用整合到:start-master.sh 文件末尾启动调用,便可以通过k8s暴露spark-master的F5端口实现http调用。文章来源:https://www.toymoban.com/news/detail-738765.html
3、使用spark-operator安装spark集群方式
可以参考阿里云文章:搭建Spark应用文章来源地址https://www.toymoban.com/news/detail-738765.html
到了这里,关于基于Headless构建高可用spark+pyspark集群的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!