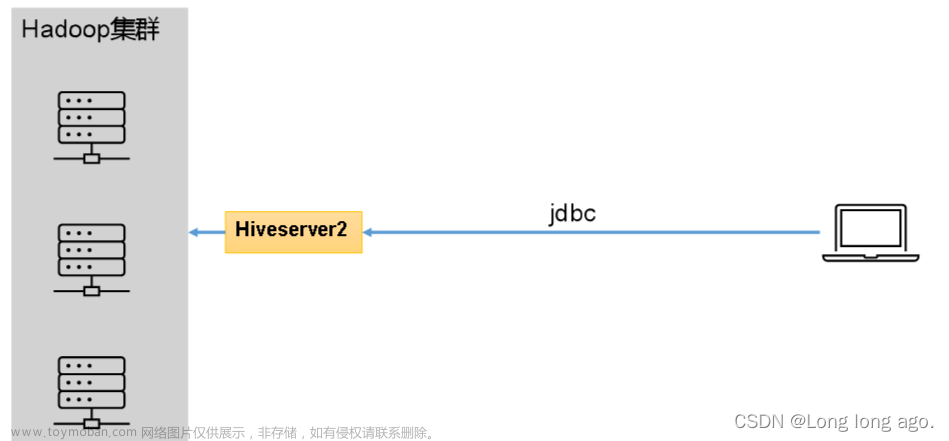
有多个HiveServer2服务时,可以借助Zookeeper服务实现访问HiveServer2的负载均衡,将HiveServer2的压力分担到多个节点上去。本文详细介绍HiveServer2负载均衡的配置及使用方法,请根据EMR集群(普通集群和Kerberos集群)的实际情况进行选择。
hive.server2.support.dynamic.service.discovery
设置为ture
在zooperker要创建相应的zooKeeperNamespace并赋权
create /hiveserver2 world:anyone:cdrwa
还有一些其他的配置参数:
编辑hive-site.xml
<property>
<name>spark.deploy.recoveryMode</name>
<value>ZOOKEEPER</value>
</property-->
<!--设置hiveserve支持动态-->
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<!--设置hiveserver2的命名空间-->
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<!--设置zk集群的客户端地址-->
<property>
<name>hive.zookeeper.quorum</name>
<value>node5:2181,node4:2181,node3:2181</value>
</property>
<!--指定zk的端口,这个是否可以去掉,因为上一步已经配置了端口,由于时间关系,我没有做测试,有兴趣可以测试一下-->
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<!--指定hive.server2.thrift.bind.host-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value> //两个HiveServer2实例的端口号要一致
</property>
重启hive服务文章来源:https://www.toymoban.com/news/detail-739334.html
就可以去进行连接连接的测试
beeline -u ‘jdbc:hive2://master-1-1:2181,master-1-2:2181,master-1-3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2’文章来源地址https://www.toymoban.com/news/detail-739334.html
到了这里,关于HiveServer2负载均衡的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!