
摘要
大型语言模型(LLM)在自然语言处理领域展现出了令人印象深刻的影响,但它们仍然在几个方面存在问题,例如完整性、及时性、忠实度和适应性。尽管最近的研究工作集中在将LLM与外部知识源进行连接,但知识库(KB)的整合仍然研究不足且面临多个挑战。
本文介绍了KnowledGPT,这是一个全面的框架,用于将LLM与各种知识库连接起来,促进知识的检索和存储。
检索过程采用了思维启发程序,它以代码格式生成用于KB的搜索语言,并具有预定义的KB操作功能。
除了检索,KnowledGPT还提供了将知识存储在个性化知识库中的能力,以满足个体用户的需求。
通过广泛的实验证明,通过将LLM与KB整合,KnowledGPT能够比纯粹的LLM更好地回答需要世界知识的更广泛的问题,利用广为人知的知识库中已有的知识以及提取到个性化知识库中的知识
引言
大型语言模型(LLMs)在各种自然语言处理(NLP)任务中取得了重大影响,如翻译,摘要和问答,同时还处理了来自现实世界用户的各种请求。它们卓越的能力源于不断增加的参数和训练数据,这使得它们具有庞大的知识和新兴能力,如思维链推理和上下文学习。然而,LLMs在处理事实知识方面仍然存在困难,包括完整性、及时性、忠实性和适应性等问题。
- LLMs在及时更新和领域专业知识方面存在局限性。
- 这些模型可能生成不忠实或“幻觉”知识,引发可靠性和伦理方面的担忧。
- 由于成本和可访问性等限制,LLMs几乎无法通过持续训练来纳入新知识,这妨碍了调整这些模型以适应特定知识需求的能力。
因此,这些知识需求鼓励对将LLMs与外部知识源进行整合的全面研究。
为解决这个问题,最近已经做出了一些努力,使LLMs能够访问插拔式知识源,如知识库(KBs),搜索引擎,文档记忆和数据库,以为LLMs提供世界知识,通常通过LLM生成的API调用。本文专注于知识库(KBs),这是一种特殊形式的知识源,具有以实体为中心的知识,如关系三元组和实体描述。
一方面,已经构建了各种知识库,以实现其在应用程序中的实际有效性以及其表示的简洁性、表达性、可解释性和可见性。另一方面,以前的方法主要集中在文档语料库上,但在应用于知识图谱时显示出一些缺陷,如图1所示(从文档语料库和知识库中检索结果的比较。在这种情况下,从语料库中检索的文档没有提供足够的知识来回答查询,而从知识库中可以检索到足够相关的知识)。
因此,将LLMs与知识库连接起来具有重要意义,但仍然未经充分探索。
最近,一些工作尝试将LLMs与知识库连接起来。Toolformer查询维基百科以获取感兴趣实体的描述信息以回答相关问题。Graph-Toolformer和ToolkenGPT使LLMs对知识图谱(如Freebase)进行推理。RET-LLM通过从过去的对话中提取的关系三元组构建个性化的知识图谱内存,供将来使用,与LangChain的KG Index和Llama Index的实际工作并行进行。
然而,在这个方向上仍然存在许多挑战,如图2所示。
- LLMs在复杂和各种问题中浏览知识库的过程仍然是一个问题,特别是对于需要跨多个和嵌套的KB条目获取信息的多跳问题而言。
- 在知识库中将实体和关系与文本提及对齐是一项具有挑战性的任务,因为它们需要映射到广泛的自然语言表达,并考虑到知识库中的严重歧义。
- 虽然基于三元组的知识图谱表示整洁且可解释,但与自然语言相比,它只涵盖有限的信息,这表明需要新的知识库表示形式来供LLMs使用。
在这篇论文中提出了一个全面的框架——KnowledGPT,有效地将LLMs与各种知识库连接起来,提高处理复杂问题、消歧和知识表示的能力。KnowledGPT实现了一个统一的访问接口,用于在不同的知识库上进行操作,包括广泛使用的公共知识库和个性化知识库存储。KnowledGPT访问以实体为导向的知识,包括实体描述和关系三元组。
对于给定的查询,KnowledGPT通过三个步骤进行知识库搜索:
- 搜索代码生成、
- 搜索执行
- 答案生成。
KnowledGPT采用了“思维程序”(PoT)提示的方式,通过生成委托搜索步骤并执行的Python代码与知识库交互。该代码封装了用于访问知识库的函数,例如实体链接。之后,KnowledGPT整合检索到的知识生成响应。如果KnowledGPT判断问题不需要来自知识库的知识,或者检索到的知识不足或不存在,问题将由LLM直接回答。此外,KnowledGPT还可以从以各种形式表示的非结构化文本中提取知识,以丰富个性化知识库。
总的来说,本文的贡献可以总结如下:
- 提出了KnowledGPT,一个全面的框架,使LLMs能够从知识库中检索知识。它在处理复杂搜索和消歧等重要实际挑战方面显著推进了LLMs和知识库之间的协作。
- 提出了使用个性化知识库作为LLMs的符号记忆,将以实体为导向的知识封装成三种形式的表示。与仅包含三元组的知识库相比,这扩大了符号记忆中的知识范围。
- 通过实验证明了我们提出的方法的有效性。结果突出了将知识库作为LLMs的符号记忆的实用性和潜力。
2 相关研究
LLMs的外部知识和记忆 大型语言模型(LLMs),如GPT-4和LLaMA,在各种应用中展示了令人印象深刻的性能。然而,它们在考虑完整性、及时性、真实性和适应性方面仍然存在困难。因此,最近的许多工作都致力于为LLMs提供外部知识。互联网增强语言模型,以及新的Bing和ChatGPT“Browse with Bing”插件,允许LLMs通过搜索引擎或网络浏览器访问最新信息。像REALM这样的检索增强方法,,RAG通过文档语料库增强LLMs,这也越来越多地被最近流行的LLMs(如ChatGPT)采用作为记忆单元。ChatDB通过数据库作为符号记忆来增强LLMs。
LLMs的知识库 一些最近的研究致力于通过外部KB增强LLMs的知识,或者将KB作为符号记忆使用,通常是通过让LLMs生成KB操作的API调用。Toolformer训练LLMs搜索维基百科中的实体文本。Graph-Toolformer使LLMs能够在知识图谱上进行推理。然而,它跳过了实体链接步骤,因此需要实体id(如/m/053yx)作为输入,而不是它们的名称。ToolkenGPT保持LLMs冻结,并为KB中的关系训练工具嵌入以支持关系查询。RETTLLM与LangChain和Llama-Index的KG记忆类似,从用户输入中提取关系三元组并将其存储在符号KG记忆中。与以前的工作相比,KnowledGPT支持各种知识表示以及公共和私有知识库,如表1所示。
基于知识的问答(KBQA) 是针对特定KG的自然语言查询搜索答案实体或关系。现有的KBQA系统主要基于语义解析或信息抽取,其中越来越多地涉及语言模型。语义解析方法利用语义解析器将自然语言查询转换为中间逻辑形式,如SPARQL和程序,然后在知识库上执行这些形式以获取答案。然而,生成的逻辑形式通常是不可执行的,因此无法得到正确的答案。Pangu训练了一个语言模型鉴别器来评估候选计划的概率。信息抽取方法通常结合检索和推理。这些方法在处理单跳检索方面表现出有效性。然而,它们在处理多跳检索时面临存储和计算成本的挑战,其中每个添加的跳数关系数量呈指数增长。
KnowledGPT与KBQA方法在两个方面不同。
1)许多KBQA方法是专为关于知识图谱中关系三元组的特定查询而设计的,而KnowledGPT通过从知识库中以各种形式增强LLMs来响应各种用户查询。
2)KBQA方法通常在特定的数据集和知识图谱上进行训练,而KnowledGPT不需要训练,并且可以轻松适应不同的LLMs和知识库。
3方法
本节介绍了KnowledGPT,这是一个将LLMs与知识库集成的综合框架。首先给出了KnowledGPT的两个任务的定义,即知识检索和知识存储(第3.1节)。然后,详细介绍了KnowledGPT的检索过程(第3.2节)和存储过程(第3.3节)的细节。
3.1 任务定义
KnowledGPT通过各种知识库(包括个性化知识库作为可写入的符号记忆)为LLMs提供外部知识。给定一个自然语言的用户输入,KnowledGPT承担两个主要任务,即知识检索和知识存储。在知识检索任务中,模型通过提供的知识库搜索相关知识来回答用户查询。在知识存储任务中,模型从用户输入中提取知识并将其插入个性化知识库。
3.2 知识检索
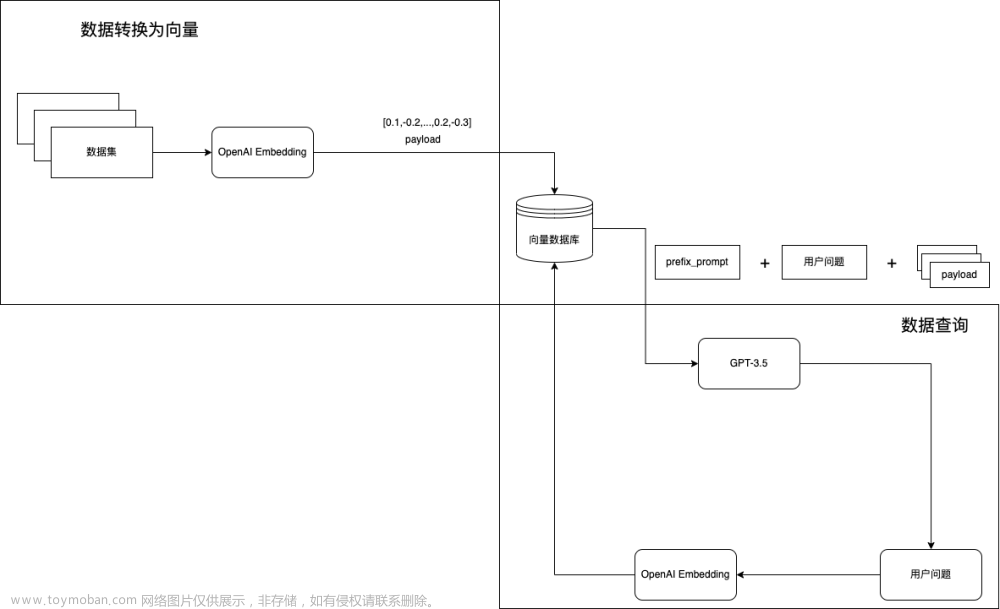
KnowledGPT采用了一个三步骤的过程来利用知识库中的知识回答用户查询,如图3所示。首先,它生成一段查询特定知识库访问的搜索代码作为逻辑形式。然后,执行搜索代码以检索相关知识。最后,KnowledGPT读取检索到的知识并回答查询。
采用了思维程序(PoT)提示方法,它使用由LLMs生成的Python代码作为搜索语言。在本文中,使用GPT-4作为LLMs。代码被封装在一个搜索函数中,如图3中的黄色部分所示,其中包括内置的Python函数和三个自定义的KB函数,用于促进LLMs与知识库的交互:
- get_entity_info:接受一个实体作为输入,并返回其百科描述。
- find_entity_or_value:接受一个由实体和关系组成的查询作为输入,并输出相应实体或值的列表。
- find_relationship:接受两个实体作为输入,并返回它们之间的关系列表。
特别地,每个实体或关系都表示为候选别名的列表,而不是单个名称,以有效处理同义词。除了上述输出之外,这些KB函数还返回一个记录函数调用和结果的消息。然后,搜索函数的整体输出是通过连接各个KB函数调用的消息获得的。在第7节中显示了提示信息。
然后,执行搜索函数以从知识库中检索所需的知识。在执行之前,代码可能会进行装饰,例如添加try-except语句和特定于知识库的访问器对象,这在第3.2.1节中详细说明。分别为每个知识库执行搜索函数,并将它们的结果连接起来。
最后,将检索到的知识提供给LLMs,并要求LLMs根据检索到的知识回答用户的查询。在LLMs判断问题不需要外部知识或检索到的知识不足以回答查询的情况下,LLMs将忽略检索到的信息并独立回答用户查询。
3.2.1 代码实现
接下来,介绍执行生成代码的KB函数的实现。在两个级别上实现这些函数:统一级别和KB特定级别。
统一级别的函数提供了对不同KB的操作的统一接口。这些函数包括LLMs直接生成的三个KB函数(get_entity_info、find_entity_or_value、find_relationship),以及一个entity_linking函数,用于将LLMs生成的实体别名与KB中的实体对齐。
在KB特定级别上的函数通过调用相应的API对每个特定的KB执行操作。基本上,只需要为每个KB实现三个函数:_get_entity_info、_entity_linking和_get_entity_triples。在本文中,用下划线在这些函数前面表示。
在执行之前,对生成的代码进行装饰。用try-except语句包装代码,这样如果代码在后续步骤中出现故障,搜索函数仍然可以返回成功步骤中的有价值的结果。此外,将用户查询作为全局变量传递给搜索函数。
3.2.2 实体链接
实体链接是将自然语言中的实体提及与知识库中的实体对齐的重要步骤,对于将 LLMs 与知识库集成起来是必不可少的。这是至关重要的,因为一个实体可能会被不同的提及方式所引用(例如,Donald Trump 和 President Trump),而一个名词短语也可以指代不同的实体(例如,the fruit apple 和 the tech company Apple)。
entity_linking函数包括三个步骤,如图4所示。
首先,调用KB特定的_entity_linking函数来获取候选实体。它基本上以查询和实体别名作为输入,并利用对应KB提供的实体链接API(同时包含实体名称和上下文)和搜索API(仅包含实体名称)来进行操作。
其次,调用_get_entity_info函数(在第3.2.3节中介绍)来收集候选实体的信息。每个实体信息将被截断为最大长度。
最后,向LLMs提供函数输入(包括查询、实体和关系的别名)以及候选实体及其信息,并让LLMs确定最合适的实体。
3.2.3 获取实体信息
get_entity_info函数用于检索特定实体的信息。它首先使用entity_linking函数将实体别名链接到KB中的实体。随后,它调用KB特定的_get_entity_info函数,该函数返回KB中给定实体的信息,包括实体描述和三元组信息。调用_get_entity_triples函数来收集它的三元组信息。KB特定的_get_entity_info函数嵌套在entity_linking函数中,使其成为统一级别所有KB函数的一个组成部分。
3.2.4 查找实体或值

给定一个由实体和关系组成的查询,find_entity_or_value函数旨在检索相应的实体或属性值。该函数经历了几个步骤,如算法1所示。它首先调用entity_linking函数将实体别名与KB中的相应实体关联起来。然后,它调用内部的_find_entity_or_value函数,其中包括一个KB特定的_get_entity_triples函数,用于检索与实体相关的所有三元组。随后,根据它们与输入关系别名的相似性对这些三元组中的关系进行排序。在这里,我们使用句子嵌入的余弦相似度来衡量相似性,而不是使用符号度量,这考虑了关系的同义词。然后,我们选择具有最高相似度分数的关系,并从所有相应的三元组中返回实体或属性值。为了提高我们方法的鲁棒性,如果找不到三元组,我们将在实体描述中进一步搜索关系。如果描述中存在该关系,我们返回相应的句子。否则,我们返回整个描述,该描述可能仍然提供LLMs所需的相关细节。
3.2.5 查找关系
给定一个由两个实体组成的查询,find_relationship函数旨在检索它们之间的关系。这个函数类似于find_entity_or_value。不同之处在于,在检索第一个实体的三元组或实体信息后,find_relationship函数继续搜索第二个实体,而不是关系。如果这次初始搜索失败,函数会交换第一个实体和第二个实体,并再次进行搜索。与关系相似度不同,我们通过Levenshitein距离d来衡量实体的相似性。如果两个实体名称有单词重叠,实体相似性计算为100 - d,否则为0。
3.3 知识存储
虽然公共知识库提供了丰富的世界知识,但仍无法涵盖用户感兴趣的所有知识。为了满足用户的个人知识需求,KnowledGPT引入了个性化知识库 (PKB),作为LLMs的符号记忆,使用户能够存储和访问专业知识。PKB中的知识是从用户提供的文档中提取的。当用户想要将知识添加到PKB中时,我们提示LLMs从提供的文档中提取知识,提示如Sec A所示。
考虑三种形式的知识表示,包括实体描述、关系三元组和实体-方面信息,如图2所示。这与RET-LLM 、LangChain的KG-Index 和Llama Index中仅提取三元组的方法不同。实体描述和关系三元组在维基百科和维基数据等知识库中得到了广泛采用,但它们只代表了知识的一小部分。例如,当想要了解苏格拉底作为一名士兵的经历时,苏格拉底的维基百科页面上的大部分内容几乎没有帮助,也几乎无法表示为三元组。因此,提出了额外的知识表示方法,称为实体-方面信息,用于LLMs的符号记忆。它是三元组的变体,其中对象是一段长文本,描述了一个实体和一个方面,可以通过实体和方面进行检索。例如,一个记录可能以(“苏格拉底”,“军事服务”)索引,并对应于描述"苏格拉底曾担任希腊重装步兵…"。以这种形式表示的知识也可以通过 get_entity_or_value 函数进行检索。
考虑到PKB与公共知识库相比规模较小,采用了不同的实体链接策略。主要有三个差异。
1)基于精确匹配和嵌入相似度定义了PKB的实体搜索API。嵌入相似度有助于识别广为人知的实体别名,例如Chanelle Scott Calica和Shystie。
2)在提取过程中,提取的实体提及不会与PKB中的实体对齐。因此,一个实体可能在不同的文档中被提取为不同的提及。因此,对于实体链接,KnowledGPT返回多个匹配的实体。
3)一个实体将被提取为一个别名列表,该列表将提供给LLMs进行实体链接。
对于 get_entity_or_value 函数,由于一个关系也可以被提取为不同的表达方式,选择检索相似度得分高于阈值的关系,而不是选择得分最高的关系。
4 实验
在本节中,对KnowledGPT在不同设置下进行了实验,包括在流行的知识库上手工创建多样化的查询(第4.2节),基于知识的问答(第4.3节)以及将个性化知识库作为LLM的记忆(第4.4节)。
4.1 实验设置
知识库
KnowledGPT可以通过其统一的知识库操作接口访问各种知识库。在本文中,我们主要考虑以下知识库:
Wikipedia和Wikidata:Wikipedia提供了由全球志愿者维护的关于世界实体的丰富百科知识。Wikidata是对Wikipedia的补充,它以关系三元组的形式结构化和组织这些百科知识。
CN-DBPedia:CN-DBPedia是一个大规模的、不断更新的中文知识库,从包括中文维基百科和百度百科在内的多个来源中提取而来。CN-DBPedia既包含类似Wikipedia的实体描述,也包含类似Wikidata的关系三元组。
个性化知识库:个性化知识库被设计为LLM的可写入符号性记忆,用于存储从用户输入中提取的即将到来的知识。
NLPCC 2016 KBQA知识库:这个知识库是为了评估模型在基于知识的问答任务方面而广泛采用的。它包含4300万个三元组。这个知识库仅在第4.3节中使用。
在实际场景中,我们通过确定用户查询的语言来启动处理过程。对于英文查询,我们使用Wikipedia、Wikidata和个性化知识库。对于中文查询,我们将CN-DBPedia与个性化知识库结合使用。我们的方法也可以轻松扩展到更多语言,并使用相应语言的知识库。
语言模型
在本文中,默认使用强大的LLM GPT-4,通过OpenAI API进行访问。我们通过指令、要求和上下文示例来提示LLM,并要求LLM以json格式输出。详细的提示信息在附录A中展示。对于句子嵌入,我们使用OpenAI的GPT text-embedding-ada-002模型。
4.2 流行知识库上的查询
为了评估KnowledGPT在涉及外部知识的真实用户多样化查询方面的性能,针对CN-DBPedia的知识设计了11个问题。这些问题涵盖了各种类型,包括单跳和多跳关系查询、关系预测、多样化指令、混合查询和值比较。这些问题涉及流行实体和长尾实体。具体示例请参见附录B。使用GPT-4和ChatGPT作为基础LLM对KnowledGPT进行实验,并以直接回答问题、生成代码、实体链接和KnowledGPT答案的成功生成率进行评估。
结果如表2所示。详细的生成内容请参见附录B。可以观察到:
- (1) GPT-4和ChatGPT本身在回答关于知名实体的查询方面表现良好,但对于不常见的实体,它们经常会产生幻觉。
- (2) 使用GPT-4的KnowledGPT在代码生成和实体链接等任务上表现出色,并最终用正确的知识回答用户查询,相比于GPT-4的普通回答有了显著改进。
- (3) 然而,对于ChatGPT来说,中间步骤的成功率仍有待提高,这限制了KnowledGPT整体的效力。在代码生成步骤中,ChatGPT有时会生成质量较差的关系别名,尤其是对于多样化或复杂的查询。
这个比较表明,GPT-4在复杂指令理解、任务分解和代码生成等方面明显优于ChatGPT。虽然还尝试了像Llama-2-Chat-13B这样的较小开源LLM,但它们难以直接提供准确的答案,也无法生成格式良好的代码并以JSON格式回应,这是KnowledGPT框架所要求的。
案例研究
图3展示了使用KnowledGPT回答问题“谁写了《静夜思》?”的完整过程,这需要进行多跳知识检索和推理。GPT-4给出的原始答案包含不真实的信息,这表明需要用精确的外部知识增强LLM。KnowledGPT生成了一段优秀的代码,首先查找《静夜思》的作者,然后搜索作者的作品名称。这展示了使用代码解决多跳知识检索的有效性。执行代码时,它高效地检索相关信息。最后,KnowledGPT整合检索到的知识来正确回答查询。尽管在中间步骤中可能存在噪声,但KnowledGPT能够很好地过滤噪声并给出正确的答案。
图5展示了KnowledGPT中实体链接步骤的三个实例。这些示例清楚地表明,从外部知识库的实体链接和搜索API返回的原始候选实体没有很好的排序,甚至可能不包含正确的实体。因此,仅仅选择排名靠前的实体可能会引入严重的噪声。使用GPT-4从提供了信息的候选实体中进行选择。结果表明,GPT-4能够熟练地识别出查询的正确实体,当没有合适的选项时,也能够拒绝所有选项。
4.3 基于知识的问题回答
在零样本基于知识的问题回答(KBQA)上评估了KnowledGPT。KBQA是一个广泛研究的领域,旨在回答与知识库中特定关系三元组相关的自然语言问题。例如,要回答问题“《理想国》的作者是谁”,KBQA模型应该检索到三元组(《理想国》,作者,柏拉图)并回答柏拉图。
考虑到调用OpenAI API的费用,我们编制了两个简洁的数据集,即NLPCC-100用于单跳查询和NLPCC-MH-59用于多跳查询。NLPCC-100由NLPCC 2016 KBQA数据集(Duan, 2016)的测试集中的100个样本组成,而NLPCC-MH-59由NLPCC-MH(Wang和Zhang, 2019)的测试集中的59个样本组成,后者是一个多跳KBQA数据集。NLPCC-MH是通过扩展NLPCC 2016数据集自动构建的,因此存在某种固有的噪声。我们从NLPCC-MH数据集中手动选择了59个样本,确保它们的质量和知识库中存在支持事实链。此外,我们纠正了这些样本中存在的任何噪声。在NLPCC-100和NLPCC-MH-59中,我们在本实验中仅使用全面的NLPCC 2016 KBQA知识库。
对KnowledGPT进行了几项修改,以适应该数据集和知识库。首先,在提供的知识库中,三元组的尾实体可能包含由特殊符号分隔的多个实体,因此我们调整了搜索代码生成的提示,要求LLMs在生成的代码中包含一个分割机制。其次,为了更好地进行实体链接,由于提供的知识库不包含实体描述,我们修改了_get_entity_information的实现,返回与实体相关的10个三元组,按查询关系与三元组中关系之间的Jaccard相似度排序。第三,我们还修改了实体链接提示,要求LLMs也调整查询关系别名以更好地与知识库中的关系对齐。
将KnowledGPT与以下基线方法进行比较:
基于嵌入相似性的检索 将每个三元组视为一个文档,并使用CoSENT模型进行嵌入。根据嵌入相似性为每个查询检索一个文档。对于多跳问题,将第一次检索的结果添加到查询中以促进第二次检索。
基于BM25的检索。对于每个实体,我们将其所有三元组分组为一个文档。使用BM25算法为每个搜索查询检索最相关的文档,去除停用词。如果检索到的文档包含相应的三元组,则视为成功。对于多跳查询,我们根据关系之间的Jaccard相似度从初始检索的文档中选择一个三元组,并将该三元组整合到后续检索的查询中。
SPE。SPE使用嵌入相似性从简单问题中提取主谓对。它在NLPCC 2016 KBQA任务的比赛中获得第一名。
我们报告了NLPCC-100和NLPCC-MH-59的平均F1值。平均F1是KBQA中广泛采用的度量标准,用于具有多个正确答案和预测的任务。然而,由于我们的数据集中每个样本只有一个答案和一个预测,因此平均F1实际上等同于准确率。
结果如表3所示,得出以下观察结果:
(1)对于单跳查询,KnowledGPT在检索方法(基于BM25和嵌入相似性)方面表现显著优于,这表明与文档语料库相比,从符号知识库中获取知识相关的问题的检索的有效性。
(2)零样本的KnowledGPT在NLPCC-2016 KBQA数据集的完整训练集上训练的SPE方法(0.92 vs 0.85)表现更好,这表明KnowledGPT具有强大的零样本性能。
(3)对于多跳查询,KnowledGPT也取得了出色的性能,而基于BM25和嵌入相似性的检索方法的性能显著下降。
4.4 作为记忆的知识库
我们进行了一系列实验,研究了当KnowledGPT与一个可修改的个性化知识库(PKB)配对时的有效性。KnowledGPT的任务是从提供的文档中提取知识来构建PKB,并研究是否能够正确回答相关问题。图6展示了一个示例,其中提供了关于苏格拉底的文本。KnowledGPT从文本中提取知识,并通过检索提取的知识来回答相关问题。
我们进一步将KnowledGPT应用于HotpotQA(Yang等,2018),这是一个提供文档的多跳问题回答数据集。我们从HotpotQA开发集(干扰项)中选择了25个问题,包括5个比较问题,如“Mimosa和Cryptocoryne中哪个是灌木?”和20个桥接问题,如“Erik Watts的父亲是什么时候出生的?”每个问题都与10个文档配对,KnowledGPT从这些文档中提取知识来构建PKB。
结果如表4所示。KnowledGPT成功回答了所有的比较问题,以及20个桥接问题中的15个。在未成功回答的案例中,有两个桥接问题无法提取回答问题所需的知识,还有一个桥接问题在实体链接阶段失败。总体而言,这个实验显示了利用PKB作为LLMs的符号记忆的潜在前景。
我们进一步研究了KnowledGPT在HotpotQA中100个文档上的知识提取覆盖率,考虑了不同的LLMs和应用知识表示的多样组合。为了量化覆盖率,我们使用了单词召回率进行计算,计算公式如下:
其中,| · | 表示集合的基数(元素个数)。
Wextracted 和 Wdoc 分别表示经过预处理(包括去除停用词和词形还原,使用NLTK工具包)后提取出的知识和文档中的单词集合。 文章来源:https://www.toymoban.com/news/detail-739482.html
文章来源:https://www.toymoban.com/news/detail-739482.html
结果如表5所示,我们得出以下观察结果:
(1)当仅限制知识表示为三元组时,知识提取覆盖率为0.53,这表明只有很小一部分的知识可以表示为三元组。因此,仅支持三元组的PKB无法充分包含真实用户提供的知识。
(2)通过增加其他知识表示,如实体描述和实体-方面信息,我们观察到知识提取覆盖率显著提高,这表明加入实体描述和实体-方面信息能够使KnowledGPT填充PKB以包含更广泛的知识。
(3)ChatGPT 和 GPT-4 在知识提取方面的表现相似。只有在包含实体-方面信息时,GPT-4 的性能优于 ChatGPT,这可能归因于GPT-4在遵循复杂指令方面的增强能力。文章来源地址https://www.toymoban.com/news/detail-739482.html
到了这里,关于KnowledgeGPT:利用检索和存储访问知识库上增强大型语言模型10.30的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!





![[Unity+文心知识库]使用百度智能云搭建私有知识库,集成知识库API,打造具备知识库的AI二次元姐姐](https://imgs.yssmx.com/Uploads/2024/02/759253-1.png)




