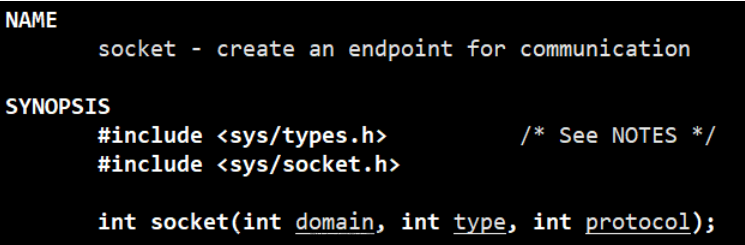
关于UDP的介绍:
UDP(User Datagram Protocol,用户数据报协议)是一种面向无连接的、不可靠的传输协议,它在网络编程中也起着重要的作用。
1. 低延迟:相比于TCP,UDP没有建立连接和拥塞控制的开销,因此传输延迟较低。这使得UDP适用于实时通信应用,如音视频传输和在线游戏。
2. 简单性:UDP的协议头相对较小,不需要维护连接状态,因此实现起来比TCP简单。
3. 广播和多播:UDP支持向多个目标地址发送数据,可以用于广播和多播通信。
4. 无拥塞控制:UDP没有拥塞控制机制,发送方不会根据网络状况调整发送速率,可能导致数据包丢失或乱序。因此,在应用层需要自己实现数据包的丢失和乱序处理。
5. 适用于短消息和小数据量传输:由于UDP没有拥塞控制和可靠性保证,它适用于传输短消息和小数据量的场景,如DNS查询、SNMP等。
总之,UDP在网络编程中提供了低延迟、简单性和广播多播等功能,适用于实时通信和短消息传输等场景,但不提供可靠性和拥塞控制。
提问:sendto函数和recvfrom函数的最后一个参数为什么要保存结构体变量长度的变量地址啊?作用是什么呢
在使用sendto函数和recvfrom函数发送和接收数据时,最后一个参数是用来指定目标地址的结构体变量的长度。这个参数的作用是告诉函数目标地址结构体的大小,以便函数能够正确地处理数据。
具体来说,sendto函数用于发送数据到指定的目标地址,而recvfrom函数用于从指定的源地址接收数据。这两个函数需要知道目标地址和源地址的大小,以便在进行数据传输时能够正确地处理地址信息。
在调用sendto函数时,最后一个参数是一个指向整数变量的指针,用于保存目标地址结构体的大小。函数会将目标地址结构体的大小写入该变量中,以便函数能够正确地发送数据。
在调用recvfrom函数时,最后一个参数也是一个指向整数变量的指针,用于保存源地址结构体的大小。函数会将源地址结构体的大小写入该变量中,以便函数能够正确地接收数据,并将源地址信息写入到指定的结构体变量中。
这样做的目的是为了确保函数能够正确地处理地址信息,以便进行数据的正确发送和接收。通过传递地址结构体的大小,函数可以根据实际的地址大小进行内存操作,避免越界访问和数据损坏的问题。
总之,保存结构体变量长度的变量地址作为sendto函数和recvfrom函数的最后一个参数,是为了确保函数能够正确地处理地址信息,以便进行数据的正确发送和接收。
再来对比read函数和write函数:
对于read函数和write函数,最后一个参数通常是用来指定要读取或写入的数据的大小。这个参数的作用是告诉函数要读取或写入多少字节的数据,以便函数能够正确地处理数据。
具体来说,read函数用于从文件描述符中读取数据,而write函数用于向文件描述符中写入数据。这两个函数需要知道要读取或写入的数据的大小,以便在进行数据传输时能够正确地处理数据。
在调用read函数时,最后一个参数是一个整数,用于指定要读取的数据的大小。函数会根据这个参数的值从文件描述符中读取相应大小的数据。
在调用write函数时,最后一个参数也是一个整数,用于指定要写入的数据的大小。函数会根据这个参数的值将相应大小的数据写入到文件描述符中。
这样做的目的是为了确保函数能够正确地读取或写入指定大小的数据,以避免读取或写入过多或过少的数据,从而保证数据的完整性和正确性。
总之,read函数和write函数的最后一个参数是为了指定要读取或写入的数据的大小,以确保函数能够正确地处理数据。
由上面的两个回答可知TCP和UDP传输和接收函数的对比,可是那这样的话sendto函数和recvfrom函数怎么知道读取或写入的多少字节的数据呢?就像read函数和write函数一样:
sendto函数和recvfrom函数在发送和接收数据时,不需要显式地指定要读取或写入的数据的大小。相反,它们通过其他方式来确定要读取或写入的数据的大小。
对于sendto函数,它发送的数据通常是通过参数中的缓冲区指针和指定的大小来确定的。函数会根据指定的大小从缓冲区中读取相应大小的数据,并将其发送到目标地址。
对于recvfrom函数,它接收的数据通常是通过参数中的缓冲区指针和指定的大小来保存的。函数会根据指定的大小从网络中接收相应大小的数据,并将其存储到缓冲区中。
在实际使用中,通常会在调用sendto函数和recvfrom函数之前,根据需要将数据写入缓冲区或从缓冲区中读取数据。然后,通过指定缓冲区的大小来告诉函数要读取或写入多少字节的数据。
总之,sendto函数和recvfrom函数通过缓冲区的大小来确定要读取或写入的数据的大小,而不需要显式地指定。在调用这些函数之前,需要根据需要将数据写入缓冲区或从缓冲区中读取数据,并通过指定缓冲区的大小来告诉函数要读取或写入多少字节的数据。
既然UDP无需注册待传输数据的目标IP和端口号,为什么在编译时还需要加上ip地址和端口号?
解答:
在使用UDP进行通信时,确实不需要在编译时指定目标IP地址和端口号。UDP是一种无连接的协议,它不需要在通信之前建立连接,也不需要事先知道目标IP地址和端口号。
然而,在编写UDP程序时,通常需要指定本地IP地址和端口号,以便程序能够绑定到正确的网络接口,并监听指定的端口。这是因为UDP程序通常需要接收来自其他主机的数据包,或者发送数据到其他主机。
在编译时指定本地IP地址和端口号是为了告诉操作系统在程序运行时将程序绑定到指定的网络接口和端口。这样,程序就可以在指定的网络接口上监听和接收数据,或者发送数据到指定的目标主机。文章来源:https://www.toymoban.com/news/detail-739672.html
需要注意的是,编译时指定的本地IP地址和端口号只是用于绑定程序到指定的网络接口和端口,不会影响程序与其他主机之间的通信。实际的数据传输仍然是通过`sendto`和`recvfrom`等函数来指定目标IP地址和端口号。文章来源地址https://www.toymoban.com/news/detail-739672.html
到了这里,关于网络编程中关于UDP套接字的一些知识点的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!