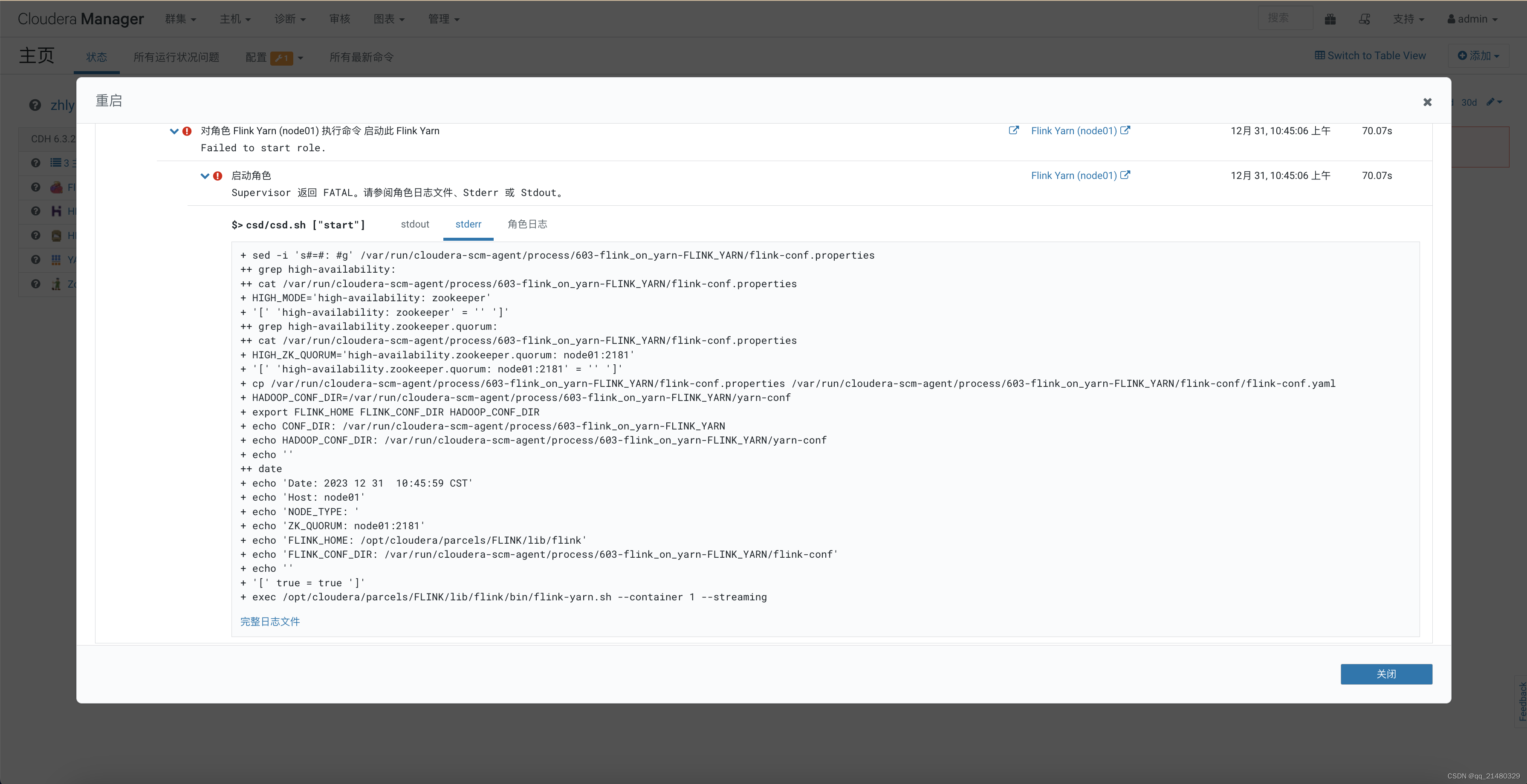
1、kafka环境单点
根据官网版本说明(3.6.0)发布,zookeeper依旧在使用状态,预期在4.0.0大版本的时候彻底抛弃zookeeper使用KRaft(Apache Kafka)官方并给出了zk迁移KR的文档
2、使用docker启动单点kafka
1、首先将kafka启动命令,存储为.service结尾的系统服务文件,并指定存储在/etc/systemd/system/目录下
2、kafk.service文件
[Unit]
Description=kafka
After=docker.service
Requires=docker.service
[Service]
TimeoutStartSec=0
ExecStartPre=-/usr/bin/docker rm kafka
ExecStart=/usr/bin/
docker run \
--name kafka \
-v /etc/localtime:/etc/localtime:ro \
--log-driver=none \
-e HOSTNAME=kafka \
-p 9092:9092 \
-e KAFKA_BROKER_ID=1 \
-e KAFKA_CFG_LISTENERS=PLAINTEXT://:9092 \
-e KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 \
-e KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181 \
-e ALLOW_PLAINTEXT_LISTENER=yes \
wurstmeister/kafka #kafka版本哦
ExecStop=/usr/bin/docker kill kafka
Restart=always
RestartSec=5
[Install]
WantedBy=multi-user.target3、使用linux系统命令进行启动
systemctl start kafka.service
systemctl logs kafka
systemctl status kafka
systemctl status kafka报错:/etc/systemd/system/kafka.service:14: Missing '='.

2、zookeeper
docker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper
使用idea连接zookeeper:
1、下载zookeeper插件 
2、添加IP和端口

3、flink
docker run -itd --name=jobmanager --publish 8081:8081 --network flink-network --env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" flink:1.13.5-scala_2.12 jobmanager
docker run -itd --name=taskmanager --network flink-network --env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" flink:1.13.5-scala_2.12 taskmanager文章来源:https://www.toymoban.com/news/detail-739827.html
外部访问:xxx.xxx.xxx.xxx:8081文章来源地址https://www.toymoban.com/news/detail-739827.html
到了这里,关于kafka、zookeeper、flink测试环境、docker的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!