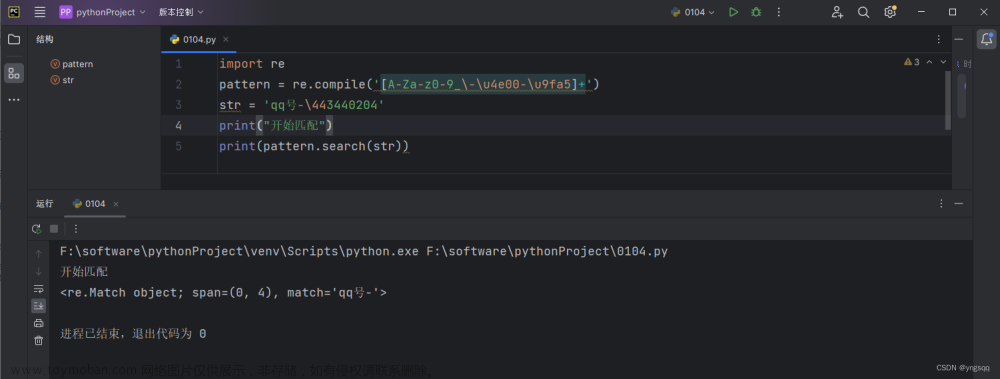
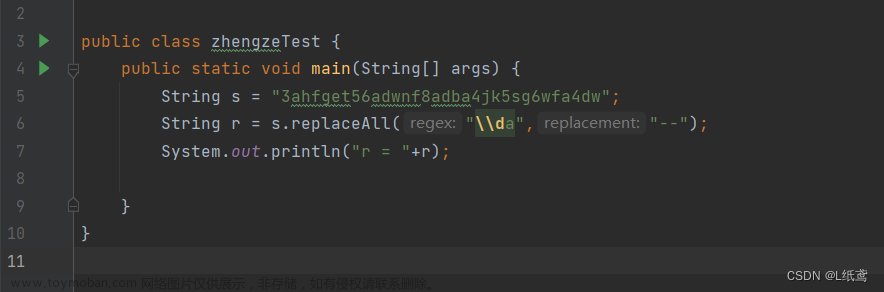
正则表达式: 一种使用表达式的方式对字符串进行匹配的语法规则
可以在如下网站中测试正则表达式
在线正则表达式测试 (oschina.net)
1.常见的正则项匹配符号
①元字符:
. 匹配除换⾏符以外的任意字符
\w 匹配字⺟或数字或下划线
\s 匹配任意的空⽩符
\d 匹配数字
\n 匹配⼀个换⾏符
\t 匹配⼀个制表符
^ 匹配字符串的开始
$ 匹配字符串的结尾
\W 匹配⾮字⺟或数字或下划线
\D 匹配⾮数字
\S 匹配⾮空⽩符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示⼀个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
②量词:控制前面的元字符出现的次数
* 重复零次或更多次
+ 重复⼀次或更多次
? 重复零次或⼀次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
③贪婪匹配和惰性匹配
.* 贪婪匹配(尽可能多)
.*? 惰性匹配(尽可能少)
2.使用语法
import re
# findall: 匹配字符串中所有的符合正则的内容
lst = re.findall(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
print(lst) #['10086', '10010']
# finditer: 匹配字符串中所有的内容[返回的是迭代器], 从迭代器中拿到内容需要.group()
it = re.finditer(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
for i in it:
print(i.group())
# search, 找到一个结果就返回, 返回的结果是match对象. 拿数据需要.group()
s = re.search(r"\d+", "我的电话号是:10086, 我女朋友的电话是:10010")
print(s.group())
# match是从头开始匹配
s = re.match(r"\d+", "10086, 我女朋友的电话是:10010")
print(s.group())
预加载正则表达式(快捷使用)文章来源:https://www.toymoban.com/news/detail-739908.html
# 预加载正则表达式
obj = re.compile(r"\d+") #效果同上面
ret = obj.finditer("我的电话号是:10086, 我女朋友的电话是:10010")
for it in ret:
print(it.group())
ret = obj.findall("呵呵哒, 我就不信你不换我1000000000")
print(ret)
s = """
<div class='jay'><span id='1'>郭麒麟</span></div>
<div class='jj'><span id='2'>宋铁</span></div>
<div class='jolin'><span id='3'>大聪明</span></div>
<div class='sylar'><span id='4'>范思哲</span></div>
<div class='tory'><span id='5'>胡说八道</span></div>
"""
# (?P<分组名字>正则) 可以单独从正则匹配的内容中进一步提取内容
obj = re.compile(r"<div class='.*?'><span id='(?P<id>\d+)'>(?P<wahaha>.*?)</span></div>", re.S) # re.S: 让.能匹配换行符
result = obj.finditer(s)
for it in result:
print(it.group("wahaha"))
print(it.group("id"))文章来源地址https://www.toymoban.com/news/detail-739908.html
到了这里,关于正则表达式 re模块的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!