接上文
https://editor.csdn.net/md/?articleId=133988963
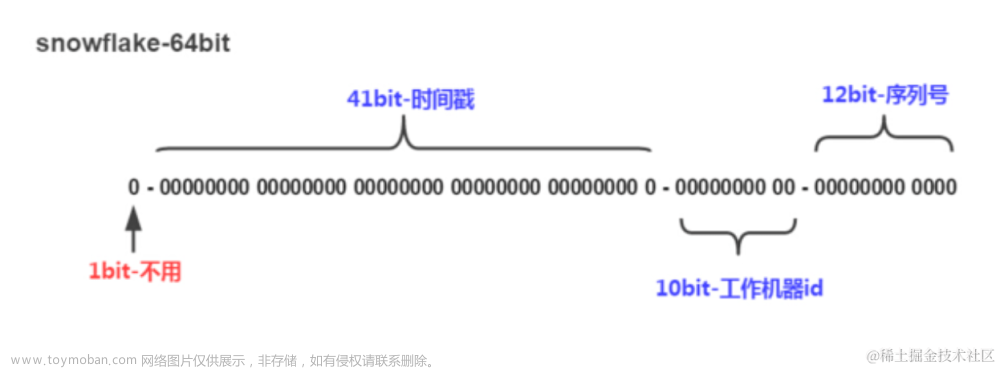
类snowFlake 方案
- 应用举例 mongoDB ObjectID 就是一个典型的实现。
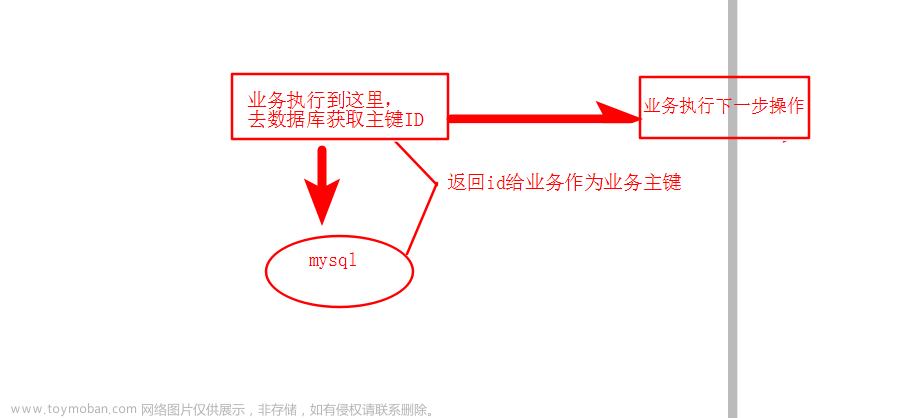
数据库生成
以MySQL举例 利用给字段设置AUTO-INCREMENT来保证ID自增,每次业务使用SQL拿到MySQL的ID
这种方案的优缺点:
- 优点
1 简单。利用数据库实现 成本小,有专业的DBA维护
2 ID单调递增。用来实现一些对于ID有特殊要求的业务 - 缺点
1 强依赖DB,当整个DB异常整个系统不可用,属于致命问题
2 ID发号性能瓶颈在于单台DB的读写性能
对于MySQL的性能问题,可以考虑多部署几台机器。然后设置不同的初始值,步数长和机器数相等。
Flickr论文
但是这玩意看起来能满足。但是存在的问题:
- 系统基本属于无法水平拓展。因为你定义好了步长 都写死了。如果后续发现性能不够要加机器 怎么处理?
- ID没有单调递增。只能趋势递增。当然对于一般业务也没什么。可以忍受
- 数据库压力大。毕竟都读写一次DB
- 当然也可以用redis 但是还是一样的问题
id-service 方案
id-service-segment数据库方案
第一种id-service-segment 方案:
-
在使用数据库的方案上 做如下改变:
每次获取ID读写DB -> 获取一个segment大小的数据量 用完之后再去获取新的 可以大大减少数据库压力。
各个业务用biz_tag区分 每个biz-tag的Id获取相互隔离。后续再扩容优点:
1 id-service可以方便的线性扩展。性能满足大多数业务场景
2 ID是递增的 满足PK的要求
3 容灾好。id-service有缓存 即使DB宕机也不影响业务 不过不能太久
缺点:
1 ID号码不够随机,能够泄漏发号数量的信息,不安全。
2 因为也是获取segment 容易出现尖刺
3 DB宕机的问题
双buffer优化
对于第二个缺点,id-service-segment做了一些优化。
在取号段的时间是在号段消耗完之后进行。也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
为此,我们希望DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的延迟指标文章来源:https://www.toymoban.com/news/detail-741262.html
id-service高可用容灾
预算足够选择主从复制即可。如果预算不够。。。单点吧就文章来源地址https://www.toymoban.com/news/detail-741262.html
到了这里,关于分布式ID系统设计(2)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!