安装新版本gawk
awk有很多种版本,例如nawk、gawk。gawk是GNU awk,它的功能很丰富。
本教程采用的是gawk 4.2.0版本,4.2.0版本的gawk是一个比较大的改版,新支持的一些特性非常好用,而在低于4.2.0版本时这些语法可能会报错。所以,请先安装4.2.0版本或更高版本的gawk。
查看awk版本
awk --version
这里以安装gawk 4.2.0为例。
# 1.下载
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/gnu/gawk/gawk-4.2.0.tar.gz
# 2.解压、进入解压后目录
tar xf gawk-4.2.0.tar.gz
cd gawk-4.2.0/
# 3.编译,并执行安装目录为/usr/local/gawk4.2
./configure --prefix=/usr/local/gawk4.2 && make && make install
# 4.创建一个软链接:让awk指向刚新装的gawk版本
ln -fs /usr/local/gawk4.2/bin/gawk /usr/bin/awk
# 此时,调用awk将调用新版本的gawk,调用gawk将调用旧版本的gawk
awk --version
gawk --version
本系列的awk教程中,将大量使用到如下示例文件a.txt。
ID name gender age email phone
1 Bob male 28 abc@qq.com 18023394012
2 Alice female 24 def@gmail.com 18084925203
3 Tony male 21 aaa@163.com 17048792503
4 Kevin male 21 bbb@189.com 17023929033
5 Alex male 18 ccc@xyz.com 18185904230
6 Andy female 22 ddd@139.com 18923902352
7 Jerry female 25 exdsa@189.com 18785234906
8 Peter male 20 bax@qq.com 17729348758
9 Steven female 23 bc@sohu.com 15947893212
10 Bruce female 27 bcbd@139.com 13942943905
读取文件的几种方式
读取文件有如下几种常见的方式:
- 按字符数量读取:每一次可以读取一个字符,或者多个字符,直到把整个文件读取完
- 按照分隔符进行读取:一直读取直到遇到了分隔符才停止,下次继续从分隔的位置处向后读取,直到读完整个文件
-
按行读取:每次读取一行,直到把整个文件读完
- 它是按照分隔符读取的一种特殊情况:将分隔符指定为了换行符
\n
- 它是按照分隔符读取的一种特殊情况:将分隔符指定为了换行符
-
一次性读取整个文件
- 是按字符数量读取的特殊情况
- 也是按分隔符读取的特殊情况
- 按字节数量读取:一次读取指定数量的字节数据,直到把文件读完
下面使用Shell的read命令来演示前4种读取文件的方式(第五种按字节数读取的方式read不支持)。
按字符数量读取
read的-n选项和-N选项可以指定一次性读取多少个字符。
# 只读一个字符
read -n 1 data <a.txt
# 读100个字符,但如果不足100字符时遇到换行符则停止读取
read -n 100 data < a.txt
# 强制读取100字符,遇到换行符也不停止
read -N 100 data < a.txt
如果按照字符数量读取,直到把文件读完,则使用while循环,且将文件放在while结构的后面,而不能放在while循环的条件位置:
# 正确
while read -N 3 data;do
echo "$data"
done <a.txt
# 错误
while read -N 3 data < a.txt;do
echo "$data"
done
按分隔符读取
read命令的-d选项可以指定读取文件时的分隔符。
# 一直读取,直到遇到字符m才停止,并将读取的数据保存到data变量中
read -d "m" data <a.txt
如果要按分隔符读取并读完整个文件,则使用while循环:
while read -d "m" data ;do
echo "$data"
done <a.txt
按行读取
read默认情况下就是按行读取的,一次读取一行。
# 从a.txt中读取第一行保存到变量data中
read line <a.txt
如果要求按行读取完整个文件,则使用while循环:
while read line;do
echo "$line"
done <a.txt
一次性读整个文件
要一次性读取完整个文件,有两种方式:
- 按照字符数量读取,且指定的字符数要大于文件的总大小
- 按分隔符读取,且指定的分隔符是文件中不存在的字符,这样的话会一直读取,因为找不到分隔符而读完整个文件
# 指定超出文件大小的字符数量
read -N 1000000 data <a.txt
echo "$data"
# 指定文件中不存在的字符作为分隔符
read -d "_" data <a.txt
echo "$data"
awk用法入门
awk 'awk_program' a.txt
- a.txt是awk要读取的文件,可以是0个文件或一个文件,也可以多个文件
- 如果不给定任何文件,但又需要读取文件,则表示从标准输入中读取
-
单引号包围的是awk代码,也称为awk程序
- 尽量使用单引号,因为在awk中经常使用
$符号,而$符号在Shell是变量符号,如果使用双引号包围awk代码,则$符号会被Shell解析成Shell变量,然后进行Shell变量替换。使用单引号包围awk代码,则$会脱离Shell的魔掌,使得$符号留给了awk去解析
- 尽量使用单引号,因为在awk中经常使用
- awk程序中,大量使用大括号,大括号表示代码块,代码块中间可以之间连用,代码块内部的多个语句需使用分号";"分隔
awk示例:
# 输出a.txt中的每一行
awk '{print $0}' a.txt
# 多个代码块,代码块中多个语句
# 输出每行之后还输出两行:hello行和world行
awk '{print $0}{print "hello";print "world"}' a.txt
对于awk '{print $0}' a.txt,它类似于shell的while循环while read line;do echo "$line";done <a.txt。awk隐藏了读取每一行的while循环,它会自动读取每一行,其中的{print $0}对应于Shell的while循环体echo "$line"部分。
下面再分析该awk命令的执行过程:

BEGIN和END语句块
awk的所有代码(目前这么认为)都是写在语句块中的。
例如:
awk '{print $0}' a.txt
awk '{print $0}{print $0;print $0}' a.txt
每个语句块前面可以有pattern,所以格式为:
pattern1{statement1}pattern2{statement3;statement4;...}
语句块可分为3类:BEGIN语句块、END语句块和main语句块。其中BEGIN语句块和END语句块都是的格式分别为BEGIN{...}和END{...},而main语句块是一种统称,它的pattern部分没有固定格式,也可以省略,main代码块是在读取文件的每一行的时候都执行的代码块。
分析下面三个awk命令的执行结果:
awk 'BEGIN{print "我在前面"}{print $0}' a.txt
awk 'END{print "我在后面"}{print $0}' a.txt
awk 'BEGIN{print "我在前面"}{print $0}END{print "我在后面"}' a.txt
根据上面3行命令的执行结果,可总结出如下有关于BEGIN、END和main代码块的特性:

awk命令行结构和语法结构
awk命令行结构
awk [ -- ] program-text file ... (1)
awk -f program-file [ -- ] file ... (2)
awk -e program-text [ -- ] file ... (3)
其中:

awk语法结构
awk语法结构即awk代码部分的结构。
awk的语法充斥着pattern{action}的模式,它们称为awk rule。
例如:
awk '
BEGIN{n=3}
/^[0-9]/{$1>5{$1=333;print $1}
/Alice/{print "Alice"}
END{print "hello"}
' a.txt
# 等价的单行式:
awk 'BEGIN{n=3} /^[0-9]/{$1>5{$1=333;print $1} /Alice/{print "Alice"} END{print "hello"}' a.txt
上面示例中,有BEGIN语句块,有END语句块,还有2个main代码块,两个main代码块都使用了正则表达式作为pattern。
关于awk的语法:
- 多个
pattern{action}可以直接连接连用 - action中多个语句如果写在同一行,则需使用分号分隔
- pattern部分用于筛选行,action表示在筛选通过后执行的操作
- pattern和action都可以省略,其中:

pattern和action
对于pattern{action}语句结构(都称之为语句块),其中的pattern部分可以使用下面列出的模式:
# 特殊pattern
BEGIN
END
# 布尔代码块
/regular expression/ # 正则匹配成功与否 /a.*ef/{action}
relational expression # 即等值比较、大小比较 3>2{action}
pattern && pattern # 逻辑与 3>2 && 3>1 {action}
pattern || pattern # 逻辑或 3>2 || 3<1 {action}
! pattern # 逻辑取反 !/a.*ef/{action}
(pattern) # 改变优先级
pattern ? pattern : pattern # 三目运算符决定的布尔值
# 范围pattern,非布尔代码块
pattern1, pattern2 # 范围,pat1打开、pat2关闭,即flip,flop模式
action部分,可以是任何语句,例如print。
详细分析awk如何读取文件
awk读取输入文件时,每次读取一条记录(record)(默认情况下按行读取,所以此时记录就是行)。每读取一条记录,将其保存到$0中,然后执行一次main代码段。
awk '{print $0}' a.txt
如果是空文件,则因为无法读取到任何一条记录,将导致直接关闭文件,而不会进入main代码段。
touch x.log # 创建一个空文件
awk '{print "hello world"}' x.log
可设置表示输入记录分隔符的预定义变量RS(Record Separator)来改变每次读取的记录模式。
# RS="\n" 、 RS="m"
awk 'BEGIN{RS="\n"}{print $0}' a.txt
awk 'BEGIN{RS="m"}{print $0}' a.txt
RS通常设置在BEGIN代码块中,因为要先于读取文件就确定好RS分隔符。
RS指定输入记录分隔符时,所读取的记录中是不包含分隔符字符的。例如
RS="a",则$0中一定不可能出现字符a。
RS两种可能情况:
- RS为单个字符:直接使用该字符来分割记录
- RS为多个字符:将其当做正则表达式,只要匹配正则表达式的符号,都用来分割记录
- 设置预定义变量IGNORECASE为非零值,正则匹配时表示忽略大小写
- 兼容模式下,只有首字符才生效,不会使用正则模式去分割记录
特殊的RS值用来解决特殊读取需求:

示例:
# 按段落读取:RS=''
$ awk 'BEGIN{RS=""}{print $0"------"}' a.txt
# 一次性读取所有数据:RS='\0' RS="^$"
$ awk 'BEGIN{RS="\0"}{print $0"------"}' a.txt
$ awk 'BEGIN{RS="^$"}{print $0"------"}' a.txt
# 忽略空行:RS='\n+'
$ awk 'BEGIN{RS="\n+"}{print $0"------"}' a.txt
# 忽略大小写:预定义变量IGNORECASE设置为非0值
$ awk 'BEGIN{IGNORECASE=1}{print $0"------"}' RS='[ab]' a.txt
预定义变量RT:
在awk每次读完一条记录时,会设置一个称为RT的预定义变量,表示Record Termination。
当RS为单个字符时,RT的值和RS的值是相同的。
当RS为多个字符(正则表达式)时,则RT设置为正则匹配到记录分隔符之后,真正用于划分记录时的字符。
当无法匹配到记录分隔符时,RT设置为控制空字符串(即默认的初始值)。
awk 'BEGIN{RS="(fe)?male"}{print RT}' a.txt
两种行号:NR和FNR
在读取每条记录之后,将其赋值给$0,同时还会设置NR、FNR、RT。
- NR:所有文件的行号计数器
- FNR:是各个文件的行号计数器
awk '{print NR}' a.txt a.txt
awk '{print FNR}' a.txt a.txt
详细分析awk字段分割
awk读取每一条记录之后,会将其赋值给$0,同时还会对这条记录按照预定义变量FS划分字段,将划分好的各个字段分别赋值给$1 $2 $3 $4...$N,同时将划分的字段数量赋值给预定义变量NF。
引用字段的方式
$N引用字段:
-
N=0:即$0,引用记录本身 -
0<N<=NF:引用对应字段 -
N>NF:表示引用不存在的字段,返回空字符串 -
N<0:报错
可使用变量或计算的方式指定要获取的字段序号。
awk '{n = 5;print $n}' a.txt
awk '{print $(2+2)}' a.txt # 括号必不可少,用于改变优先级
awk '{print $(NF-3)}' a.txt
分割字段的方式
读取record之后,将使用预定义变量FS、FIELDWIDTHS或FPAT中的一种来分割字段。分割完成之后,再进入main代码段(所以,在main中设置FS对本次已经读取的record是没有影响的,但会影响下次读取)。
划分字段方式(一):FS或-F
FS或者-F:字段分隔符

# 字段分隔符指定为单个字符
awk -F":" '{print $1}' /etc/passwd
awk 'BEGIN{FS=":"}{print $1}' /etc/passwd
# 字段分隔符指定为正则表达式
awk 'BEGIN{FS=" +|@"}{print $1,$2,$3,$4,$5,$6}' a.txt
划分字段方式(二):FIELDWIDTHS
指定预定义变量FIELDWIDTHS按字符宽度分割字段,这是gawk提供的高级功能。在处理某字段缺失时非常好用。
用法:
-
FIELDWIDTHS="3 5 6 9"表示第一个字段3字符,第二字段5字符... -
FIELDWIDTHS = "8 1:5 6 2:33"表示:- 第一个字段读8个字符
- 然后跳过1个字符再读5个字符作为第二个字段
- 然后读6个字符作为第三个字段
- 然后跳过2个字符在读33个字符作为第四个字段(如果不足33个字符,则读到结尾)
-
FIELDWIDTHS="2 3 *":- 第一个字段2个字符
- 第二个字段3个字符
- 第三个字段剩余所有字符
- 星号只能放在最后,且只能单独使用,表示剩余所有
示例1:
# 没取完的字符串DDD被丢弃,且NF=3
$ awk 'BEGIN{FIELDWIDTHS="2 3 2"}{print $1,$2,$3,$4}' <<<"AABBBCCDDDD"
AA BBB CC
# 字符串不够长度时无视
$ awk 'BEGIN{FIELDWIDTHS="2 3 2 100"}{print $1,$2,$3,$4"-"}' <<<"AABBBCCDDDD"
AA BBB CC DDDD-
# *号取剩余所有,NF=3
$ awk 'BEGIN{FIELDWIDTHS="2 3 *"}{print $1,$2,$3}' <<<"AABBBCCDDDD"
AA BBB CCDDDD
# 字段数多了,则取完字符串即可,NF=2
$ awk 'BEGIN{FIELDWIDTHS="2 30 *"}{print $1,$2,NF}' <<<"AABBBCCDDDD"
AA BBBCCDDDD 2
示例2:处理某些字段缺失的数据。
如果按照常规的FS进行字段分割,则对于缺失字段的行和没有缺失字段的行很难统一处理,但使用FIELDWIDTHS则非常方便。
假设a.txt文本内容如下:
ID name gender age email phone
1 Bob male 28 abc@qq.com 18023394012
2 Alice female 24 def@gmail.com 18084925203
3 Tony male 21 aaa@163.com 17048792503
4 Kevin male 21 bbb@189.com 17023929033
5 Alex male 18 18185904230
6 Andy female 22 ddd@139.com 18923902352
7 Jerry female 25 exdsa@189.com 18785234906
8 Peter male 20 bax@qq.com 17729348758
9 Steven female 23 bc@sohu.com 15947893212
10 Bruce female 27 bcbd@139.com 13942943905
因为email字段有的是空字段,所以直接用FS划分字段不便处理。可使用FIELDWIDTHS。
# 字段1:4字符
# 字段2:8字符
# 字段3:8字符
# 字段4:2字符
# 字段5:先跳过3字符,再读13字符,该字段13字符
# 字段6:先跳过2字符,再读11字符,该字段11字符
awk '
BEGIN{FIELDWIDTHS="4 8 8 2 3:13 2:11"}
NR>1{
print "<"$1">","<"$2">","<"$3">","<"$4">","<"$5">","<"$6">"
}' a.txt
# 如果email为空,则输出它
awk '
BEGIN{FIELDWIDTHS="4 8 8 2 3:13 2:11"}
NR>1{
if($5 ~ /^ +$/){print $0}
}' a.txt
划分字段方式(三):FPAT
FS是指定字段分隔符,来取得除分隔符外的部分作为字段。
FPAT是取得匹配的字符部分作为字段。它是gawk提供的一个高级功能。
FPAT根据指定的正则来全局匹配record,然后将所有匹配成功的部分组成$1、$2...,不会修改$0。
awk 'BEGIN{FPAT="[0-9]+"}{print $3"-"}' a.txt- 之后再设置FS或FPAT,该变量将失效
FPAT常用于字段中包含了字段分隔符的场景。例如,CSV文件中的一行数据如下:
Robbins,Arnold,"1234 A Pretty Street, NE",MyTown,MyState,12345-6789,USA
其中逗号分隔每个字段,但双引号包围的是一个字段整体,即使其中有逗号。
这时使用FPAT来划分各字段比使用FS要方便的多。
echo 'Robbins,Arnold,"1234 A Pretty Street, NE",MyTown,MyState,12345-6789,USA' |\
awk '
BEGIN{FPAT="[^,]*|(\"[^\"]*\")"}
{
for (i=1;i<NF;i++){
print "<"$i">"
}
}
'
最后,patsplit()函数和FPAT的功能一样。
检查字段划分的方式
有FS、FIELDWIDTHS、FPAT三种获取字段的方式,可使用PROCINFO数组来确定本次使用何种方式获得字段。
PROCINFO是一个数组,记录了awk进程工作时的状态信息。
如果:
-
PROCINFO["FS"]=="FS",表示使用FS分割获取字段 -
PROCINFO["FPAT"]=="FPAT",表示使用FPAT匹配获取字段 -
PROCINFO["FIELDWIDTHS"]=="FIELDWIDTHS",表示使用FIELDWIDTHS分割获取字段
例如:
if(PROCINFO["FS"]=="FS"){
...FS spliting...
} else if(PROCINFO["FPAT"]=="FPAT"){
...FPAT spliting...
} else if(PROCINFO["FIELDWIDTHS"]=="FIELDWIDTHS"){
...FIELDWIDTHS spliting...
}
修改字段或NF值的联动效应
注意下面的分割和计算两词:分割表示使用FS(field Separator),计算表示使用预定义变量OFS(Output Field Separator)。

关于$0
当读取一条record之后,将原原本本地被保存到$0当中。
awk '{print $0}' a.txt
但是,只要出现了上面所说的任何一种导致$0重新计算的操作,都会立即使用OFS去重建$0。
换句话说,没有导致$0重建,$0就一直是原原本本的数据,所以指定OFS也无效。
awk 'BEGIN{OFS="-"}{print $0}' a.txt # OFS此处无效
当$0重建后,将自动使用OFS重建,所以即使没有指定OFS,它也会采用默认值(空格)进行重建。
awk '{$1=$1;print $0}' a.txt # 输出时将以空格分隔各字段
awk '{print $0;$1=$1;print $0}' OFS="-" a.txt
如果重建$0之后,再去修改OFS,将对当前行无效,但对之后的行有效。所以如果也要对当前行生效,需要再次重建。
# OFS对第一行无效
awk '{$4+=10;OFS="-";print $0}' a.txt
# 对所有行有效
awk '{$4+=10;OFS="-";$1=$1;print $0}' a.txt
关注$0重建是一个非常有用的技巧。
例如,下面通过重建$0的技巧来实现去除行首行尾空格并压缩中间空格:
$ echo " a b c d " | awk '{$1=$1;print}'
a b c d
$ echo " a b c d " | awk '{$1=$1;print}' OFS="-"
a-b-c-d
awk数据筛选示例
筛选行
# 1.根据行号筛选
awk 'NR==2' a.txt # 筛选出第二行
awk 'NR>=2' a.txt # 输出第2行和之后的行
# 2.根据正则表达式筛选整行
awk '/qq.com/' a.txt # 输出带有qq.com的行
awk '$0 ~ /qq.com/' a.txt # 等价于上面命令
awk '/^[^@]+$/' a.txt # 输出不包含@符号的行
awk '!/@/' a.txt # 输出不包含@符号的行
# 3.根据字段来筛选行
awk '($4+0) > 24{print $0}' a.txt # 输出第4字段大于24的行
awk '$5 ~ /qq.com/' a.txt # 输出第5字段包含qq.com的行
# 4.将多个筛选条件结合起来进行筛选
awk 'NR>=2 && NR<=7' a.txt
awk '$3=="male" && $6 ~ /^170/' a.txt
awk '$3=="male" || $6 ~ /^170/' a.txt
# 5.按照范围进行筛选 flip flop
# pattern1,pattern2{action}
awk 'NR==2,NR==7' a.txt # 输出第2到第7行
awk 'NR==2,$6 ~ /^170/' a.txt
处理字段
修改字段时,一定要注意,可能带来的联动效应:即使用OFS重建$0。
awk 'NR>1{$4=$4+5;print $0}' a.txt
awk 'BEGIN{OFS="-"}NR>1{$4=$4+5;print $0}' a.txt
awk 'NR>1{$6=$6"*";print $0}' a.txt
awk运维面试试题
从ifconfig命令的结果中筛选出除了lo网卡外的所有IPv4地址。
# 1.法一:多条件筛选
ifconfig | awk '/inet / && !($2 ~ /^127/){print $2}'
# 2.法二:按段落读取,然后取IPv4字段
ifconfig | awk 'BEGIN{RS=""}!/lo/{print $6}'
# 3.法三:按段落读取,每行1字段,然后取IPv4字段
ifconfig | awk 'BEGIN{RS="";FS="\n"}!/lo/{$0=$2;FS=" ";$0=$0;print $2}'
awk工作流程
参考自:man awk的"AWK PROGRAM EXECUTION"段。
man --pager='less -p ^"AWK PROGRAM EXECUTION"' awk
执行步骤:

getline用法详解
除了可以从标准输入或非选项型参数所指定的文件中读取数据,还可以使用getline从其它各种渠道获取需要处理的数据,它的用法有很多种。
getline的返回值:
- 如果可以读取到数据,返回1
- 如果遇到了EOF,返回0
- 如果遇到了错误,返回负数。如-1表示文件无法打开,-2表示IO操作需要重试(retry)。在遇到错误的同时,还会设置
ERRNO变量来描述错误
为了健壮性,getline时强烈建议进行判断。例如:
if( (getline) <= 0 ){...}
if((getline) < 0){...}
if((getline) > 0){...}
上面的getline的括号尽量加上,因为getline < 0表示的是输入重定向,而不是和数值0进行小于号的比较。
无参数的getline
getline无参数时,表示从当前正在处理的文件中立即读取下一条记录保存到$0中,并进行字段分割,然后继续执行后续代码逻辑。
此时的getline会设置NF、RT、NR、FNR、$0和$N。
next也可以读取下一行。
-
getline:读取下一行之后,继续执行getline后面的代码
-
next:读取下一行,立即回头awk循环的头部,不会再执行next后面的代码
它们之间的区别用伪代码描述,类似于:
# next
exec 9<> filename
while read -u 9 line;do
...code...
continue # next
...code... # 这部分代码在本轮循环当中不再执行
done
# getline
while read -u 9 line;do
...code...
read -u 9 line # getline
...code...
done
例如,匹配到某行之后,再读一行就退出:
awk '/^1/{print;getline;print;exit}' a.txt
为了更健壮,应当对getline的返回值进行判断。
awk '/^1/{print;if((getline)<=0){exit};print}' a.txt
一个参数的getline
没有参数的getline是读取下一条记录之后将记录保存到$0中,并对该记录进行字段的分割。
一个参数的getline是将读取的记录保存到指定的变量当中,并且不会对其进行分割。
getline var
此时的getline只会设置RT、NR、FNR变量和指定的变量var。因此$0和$N以及NF保持不变。
awk '
/^1/{
if((getline var)<=0){exit}
print var
print $0"--"$2
}' a.txt
awk从指定文件中读取数据
-
getline < filename:从指定文件filename中读取一条记录并保存到$0中- 会进行字段的划分,会设置变量
$0 $N NF,不会设置变量NR FNR
- 会进行字段的划分,会设置变量
-
getline var < filename:从指定文件filename中读取一条记录并保存到指定变量var中- 不会划分字段,不会设置变量
NR FNR NF $0 $N
- 不会划分字段,不会设置变量
filename需使用双引号包围表示文件名字符串,否则会当作变量解析getline < "c.txt"。此外,如果路径是使用变量构建的,则应该使用括号包围路径部分。例如getline < dir "/" filename中使用了两个变量构建路径,这会产生歧义,应当写成getline <(dir "/" filename)。
注意,每次从filename读取之后都会做好位置偏移标记,下次再从该文件读取时将根据这个位置标记继续向后读取。
例如,每次行首以1开头时就读取c.txt文件的所有行。
awk '
/^1/{
print;
while((getline < "c.txt")>0){print};
close("c.txt")
}' a.txt
上面的close("c.txt")表示在while(getline)读取完文件之后关掉,以便后面再次读取,如果不关掉,则文件偏移指针将一直在文件结尾处,使得下次读取时直接遇到EOF。
awk从Shell命令输出结果中读取数据
-
cmd | getline:从Shell命令cmd的输出结果中读取一条记录保存到$0中- 会进行字段划分,设置变量
$0 NF $N RT,不会修改变量NR FNR
- 会进行字段划分,设置变量
-
cmd | getline var:从Shell命令cmd的输出结果中读取数据保存到var中- 除了var和RT,其它变量都不会设置
如果要再次执行cmd并读取其输出数据,则需要close关闭该命令。例如close("seq 1 5"),参见下面的示例。
例如:每次遇到以1开头的行都输出seq命令产生的1 2 3 4 5。
awk '/^1/{print;while(("seq 1 5"|getline)>0){print};close("seq 1 5")}' a.txt
再例如,调用Shell的date命令生成时间,然后保存到awk变量cur_date中:
awk '
/^1/{
print
"date +\"%F %T\""|getline cur_date
print cur_date
close("date +\"%F %T\"")
}' a.txt
可以将cmd保存成一个字符串变量。
awk '
BEGIN{get_date="date +\"%F %T\""}
/^1/{
print
get_date | getline cur_date
print cur_date
close(get_date)
}' a.txt
更为复杂一点的,cmd中可以包含Shell的其它特殊字符,例如管道、重定向符号等:
awk '
/^1/{
print
if(("seq 1 5 | xargs -i echo x{}y 2>/dev/null"|getline) > 0){
print
}
close("seq 1 5 | xargs -i echo x{}y 2>/dev/null")
}' a.txt
awk中的coprocess
awk虽然强大,但是有些数据仍然不方便处理,这时可将数据交给Shell命令去帮助处理,然后再从Shell命令的执行结果中取回处理后的数据继续awk处理。
awk通过|&符号来支持coproc。
awk_print[f] "something" |& Shell_Cmd
Shell_Cmd |& getline [var]
这表示awk通过print输出的数据将传递给Shell的命令Shell_Cmd去执行,然后awk再从Shell_Cmd的执行结果中取回Shell_Cmd产生的数据。
例如,不想使用awk的substr()来取子串,而是使用sed命令来替换。
awk '
BEGIN{
CMD="sed -nr \"s/.*@(.*)$/\\1/p\"";
}
NR>1{
print $5;
print $5 |& CMD;
close(CMD,"to");
CMD |& getline email_domain;
close(CMD);
print email_domain;
}' a.txt
对于awk_print |& cmd; cmd |& getline的使用,须注意的是:

对于那些要求读完所有数据再执行的命令,例如sort命令,它们有可能需要等待数据已经完成后(遇到EOF标记)才开始执行任务,对于这些命令,可以多次向coprocess中写入数据,最后close(CMD,"to")让coprocess运行起来。
例如,对age字段(即$4)使用sort命令按数值大小进行排序:
awk '
BEGIN{
CMD="sort -k4n";
}
# 将所有行都写进管道
NR>1{
print $0 |& CMD;
}
END{
close(CMD,"to"); # 关闭管道通知sort开始排序
while((CMD |& getline)>0){
print;
}
close(CMD);
} ' a.txt
close()
close(filename)
close(cmd,[from | to]) # to参数只用于coprocess的第一个阶段
如果close()关闭的对象不存在,awk不会报错,仅仅只是让其返回一个负数返回值。
close()有两个基本作用:
- 关闭文件,丢弃已有的文件偏移指针
- 下次再读取文件,将只能重新打开文件,重新打开文件会从文件的最开头处开始读取
- 发送EOF标记
awk中任何文件都只会在第一次使用时打开,之后都不会再重新打开。只有关闭之后,再使用才会重新打开。
例如一个需求是只要在a.txt中匹配到1开头的行就输出另一个文件x.log的所有内容,那么在第一次输出x.log文件内容之后,文件偏移指针将在x.log文件的结尾处,如果不关闭该文件,则后续所有读取x.log的文件操作都从结尾处继续读取,但是显然总是得到EOF异常,所以getline返回值为0,而且也读取不到任何数据。所以,必须关闭它才能在下次匹配成功时再次从头读取该文件。
awk '
/^1/{
print;
while((getline var <"x.log")>0){
print var
}
close("x.log")
}' a.txt
在处理Coprocess的时候,close()可以指定第二个参数"from"或"to",它们都针对于coproc而言,from时表示关闭coproc |& getline的管道,使用to时,表示关闭print something |& coproc的管道。
awk '
BEGIN{
CMD="sed -nr \"s/.*@(.*)$/\\1/p\"";
}
NR>1{
print $5;
print $5 |& CMD;
close(CMD,"to"); # 本次close()是必须的
CMD |& getline email_domain;
close(CMD);
print email_domain;
}' a.txt
上面的第一个close是必须的,否则sed会一直阻塞。因为sed一直认为还有数据可读,只有关闭管道发送一个EOF,sed才会开始处理。
执行Shell命令system()
多数时候,使用awk的print cmd | "sh"即可实现调用shell命令的功能。
$ awk 'BEGIN{print "date +\"%s.%N\" | "sh"}'
但也可以使用system()函数来直接执行一个Shell命令,system()的返回值是命令的退出状态码。
$ awk 'BEGIN{system("date +\"%s.%N\"")}'
1572328598.653524342
$ awk 'BEGIN{system("date +\"%s.%N\" >/dev/null")}'
$ awk 'BEGIN{system("date +\"%s.%N\" | cat")}'
1572328631.308807331
system()在开始运行之前会flush gawk的缓冲。特别的,空字符串参数的system(""),它会被gawk特殊对待,它不会去启动一个shell来执行空命令,而是仅执行flush操作。
关于flush的行为,参考下文。
fflush()
gawk会按块缓冲模式来缓冲输出结果,使用fflush()会将缓冲数据刷出。
fflush([filename])
从gawk 4.0.2之后的版本(不包括4.0.2),无参数fflush()将刷出所有缓冲数据。
此外,终端设备是行缓冲模式,此时不需要fflush,而重定向到文件、到管道都是块缓冲模式,此时可能需要fflush()。
此外,system()在运行时也会flush gawk的缓冲。特别的,如果system的参数为空字符串system(""),则它不会去启动一个shell子进程而是仅仅执行flush操作。
没有flush时:
# 在终端输入几行数据,将不会显示,直到按下Ctrl + D
awk '{print "first";print "second"}' | cat
使用fflush():
# 在终端输入几行数据,观察
awk '{print "first";fflush();print "second"}' | cat
使用system()来flush:
# 在终端输入几行数据,观察
awk '{print "first";system("echo system");print "second"}' | cat
awk '{print "first";system("");print "second"}' | cat
也可以使用stdbuf -oL命令来强制gawk按行缓冲而非默认的按块缓冲。
# 在终端输入几行数据,观察
stdbuf -oL awk '{print "first";print "second"}' | cat
fflush()也可以指定文件名或命令,表示只刷出到该文件或该命令的缓冲数据。
# 刷出所有流向到标准输出的缓冲数据
awk '{print "first";fflush("/dev/stdout");print "second"}' | cat
最后注意,fflush()刷出缓冲数据不代表发送EOF标记。
输出操作
awk可以通过print、printf将数据输出到标准输出或重定向到文件。
print elem1,elem2,elem3...
print(elem1,elem2,elem3...)
逗号分隔要打印的字段列表,各字段都会自动转换成字符串格式,然后通过预定义变量OFS(output field separator)的值(其默认值为空格)连接各字段进行输出。
$ awk 'BEGIN{print "hello","world"}'
hello world
$ awk 'BEGIN{OFS="-";print "hello","world"}'
hello-world
print要输出的数据称为输出记录,在print输出时会自动在尾部加上输出记录分隔符,输出记录分隔符的预定义变量为ORS,其默认值为\n。
$ awk 'BEGIN{OFS="-";ORS="_\n";print "hello","world"}'
hello-world_
括号可省略,但如果要打印的元素中包含了特殊符号>,则必须使用括号包围(如print("a" > "A")),因为它是输出重定向符号。
如果省略参数,即print;等价于print $0;。
print输出数值
print在输出数据时,总是会先转换成字符串再输出。
对于数值而言,可以自定义转换成字符串的格式,例如使用sprintf()进行格式化。
print在自动转换数值(专指小数)为字符串的时候,采用预定义变量OFMT(Output format)定义的格式按照sprintf()相同的方式进行格式化。OFMT默认值为%.6g,表示有效位(整数部分加小数部分)最多为6。
$ awk 'BEGIN{print 3.12432623}'
3.12433
可以修改OFMT,来自定义数值转换为字符串时的格式:
$ awk 'BEGIN{OFMT="%.2f";print 3.99989}'
4.00
# 格式化为整数
$ awk 'BEGIN{OFMT="%d";print 3.99989}'
3
$ awk 'BEGIN{OFMT="%.0f";print 3.99989}'
4
printf
printf format, item1, item2, ...
格式化字符:

修饰符:均放在格式化字符的前面
N$ N是正整数。默认情况下,printf的字段列表顺序和格式化字符
串中的%号顺序是一一对应的,使用N$可以自行指定顺序。
printf "%2$s %1$s","world","hello"输出hello world
N$可以重复指定,例如"%1$s %1$s"将取两次第一个字段
宽度 指定该字段占用的字符数量,不足宽度默认使用空格填充,超出宽度将无视。
printf "%5s","ni"输出"___ni",下划线表示空格
- 表示左对齐。默认是右对齐的。
printf "%5s","ni"输出"___ni"
printf "%-5s","ni"输出"ni___"
空格 针对于数值。对于正数,在其前添加一个空格,对于负数,无视
printf "% d,% d",3,-2输出"_3,-2",下划线表示空格
+ 针对于数值。对于正数,在其前添加一个+号,对于负数,无视
printf "%+d,%+d",3,-2输出"+3,-2",下划线表示空格
# 可变的数值前缀。对于%o,将添加前缀0,对于%x或%X,将添加前缀0x或0X
0 只对数值有效。使用0而非默认的空格填充在左边,对于左对齐的数值无效
printf "%05d","3"输出00003
printf "%-05d","3"输出3
printf "%05s",3输出____3
' 单引号,表示对数值加上千分位逗号,只对支持千分位表示的locale有效
$ awk "BEGIN{printf \"%'d\n\",123457890}"
123,457,890
$ LC_ALL=C awk "BEGIN{printf \"%'d\n\",123457890}"
123457890
.prec 指定精度。在不同格式化字符下,精度含义不同
%d,%i,%o,%u,%x,%X 的精度表示最大数字字符数量
%e,%E,%f,%F 的精度表示小数点后几位数
%s 的精度表示最长字符数量,printf "%.3s","foob"输出foo
%g,%G 的精度表示表示最大有效位数,即整数加小数位的总数量
sprintf()
sprintf()采用和printf相同的方式格式化字符串,但是它不会输出格式化后的字符串,而是返回格式化后的字符串。所以,可以将格式化后的字符串赋值给某个变量。
awk '
BEGIN{
a = sprintf("%03d", 12.34)
print a # 012
}
'
重定向输出

print[f] something | Shell_Cmd时,awk将创建一个管道,然后启动Shell命令,print[f]产生的数据放入管道,而命令将从管道中读取数据。
# 例1:
awk '
NR>1{
print $2 >"name.unsort"
cmd = "sort >name.sort"
print $2 | cmd
#print $2 | "sort >name.sort"
}
END{close(cmd)}
' a.txt
# 例2:awk中构建Shell命令,通过管道交给shell执行
awk 'BEGIN{printf "seq 1 5" | "bash"}'
print[f] something |& Shell_Cmd时,print[f]产生的数据交给Coprocess。之后,awk再从Coprocess中取回数据。这里的|&有点类似于能够让Shell_Cmd后台异步运行的管道。
stdin、stdout、stderr
awk重定向时可以直接使用/dev/stdin、/dev/stdout和/dev/stderr。还可以直接使用某个已打开的文件描述符/dev/fd/N。
例如:
awk 'BEGIN{print "something OK" > "/dev/stdout"}'
awk 'BEGIN{print "something wrong" > "/dev/stderr"}'
awk 'BEGIN{print "something wrong" | "cat >&2"}'
awk 'BEGIN{getline < "/dev/stdin";print $0}'
$ exec 4<> a.txt
$ awk 'BEGIN{while((getline < "/dev/fd/4")>0){print $0}}'
awk变量
awk的变量是动态变量,在使用时声明。
所以awk变量有3种状态:
- 未声明状态:称为untyped类型
- 引用过但未赋值状态:unassigned类型
- 已赋值状态
引用未赋值的变量,其默认初始值为空字符串或数值0。
在awk中未声明的变量称为untyped,声明了但未赋值(只要引用了就声明了)的变量其类型为unassigned。
gawk 4.2版提供了typeof()函数,可以测试变量的数据类型,包括测试变量是否声明。
awk 'BEGIN{
print(typeof(a)) # untyped
if(b==0){print(typeof(b))} # unassigned
}'
除了typeof(),还可以使用下面的技巧进行检测:
awk 'BEGIN{
if(a=="" && a==0){ # 未赋值时,两个都true
print "untyped or unassigned"
} else {
print "assigned"
}
}'
变量赋值
awk中的变量赋值语句也可以看作是一个有返回值的表达式。
例如,a=3赋值完成后返回3,同时变量a也被设置为3。
基于这个特点,有两点用法:
- 可以
x=y=z=5,等价于z=5 y=5 x=5 - 可以将赋值语句放在任意允许使用表达式的地方
x != (y = 1)awk 'BEGIN{print (a=4);print a}'
问题:a=1;arr[a+=2] = (a=a+6)是怎么赋值的,对应元素结果等于?arr[3]=7。但不要这么做,因为不同awk的赋值语句左右两边的评估顺序有可能不同。
awk中声明变量的位置

awk中使用Shell变量
要在awk中使用Shell变量,有三种方式:
1.在-v选项中将Shell变量赋值给awk变量
num=$(cat a.txt | wc -l)
awk -v n=$num 'BEGIN{print n}'
-v选项是在awk工作流程的第一阶段解析的,所以-v选项声明的变量在BEGIN{}、END{}和main代码段中都能直接使用。
2.在非选项型参数位置处使用var=value格式将Shell变量赋值给awk变量
num=$(cat a.txt | wc -l)
awk '{print n}' n=$num a.txt
非选项型参数设置的变量不能在BEGIN代码段中使用。
3.直接在awk代码部分暴露Shell变量,交给Shell解析进行Shell的变量替换
num=$(cat a.txt | wc -l)
awk 'BEGIN{print '"$num"'}'
这种方式最灵活,但可读性最差,可能会出现大量的引号。
数据类型
gawk有两种基本的数据类型:数值和字符串。在gawk 4.2.0版本中,还支持第三种基本的数据类型:正则表达式类型。
数据是什么类型在使用它的上下文中决定:在字符串操作环境下将转换为字符串,在数值操作环境下将转换为数值。这和自然语言中的一个词语、一个单词在不同句子内的不同语义是一样的。
隐式转换:
- 算术加0操作可转换为数值类型
-
"123" + 0返回数值123 -
" 123abc" + 0转换为数值时为123 - 无效字符串将转换成0,例如
"abc"+3返回3
-
- 连接空字符串可转换为字符串类型
-
123""转换为字符串"123"
-
awk 'BEGIN{a="123";print typeof(a+0)}' # number
awk 'BEGIN{a=123;print typeof(a"")}' # string
awk 'BEGIN{a=2;b=3;print(a b)+4}' # 27
显式转换:
- 数值->字符串:
- CONVFMT或sprintf():功能等价。都是指定数值转换为字符串时的格式
awk 'BEGIN{a=123.4567;CONVFMT="%.2f";print a""}' #123.46
awk 'BEGIN{a=123.4567;print sprintf("%.2f", a)}' #123.46
awk 'BEGIN{a=123.4567;printf("%.2f",a)}'
- 字符串->数值:strtonum()
gawk 'BEGIN{a="123.4567";print strtonum(a)}' # 123.457
awk字面量
awk中有3种字面量:字符串字面量、数值字面量和正则表达式字面量。
数值字面量
- 整数、浮点数、科学计数
- 105、105.0、1.05e+2、1050e-1
- awk内部总是使用浮点数方式保存所有数值,但用户在使用可以转换成整数的数值时总会去掉小数点
- 数值12.0面向用户的值为12,12面向awk内部的值是12.0000000...0
# 结果是123而非123.0
awk 'BEGIN{a=123.0;print a}'
算术运算
++ -- 自增、自减,支持i++和++i或--i或i--
^ 幂运算(**也用于幂运算)
+ - 一元运算符(正负数符号)
* / % 乘除取模运算
+ - 加减法运算
# 注:
# 1.++和--既可以当作独立语句,也可以作为表达式,如:
# awk 'BEGIN{a=3;a++;a=++a;print a}'
# 2.**或^幂运算是从右向左计算的:print 2**1**3得到2而不是8
赋值操作(优先级最低):
= += -= *= /= %= ^= **=
疑惑:b = 6;print b += b++输出结果?可能是12或13。不同的awk的实现在评估顺序上不同,所以不要用这种可能产生歧义的语句。
字符串字面量
awk中的字符串都以双引号包围,不能以单引号包围。
"abc"""-
"\0"、"\n"
字符串连接(串联):awk没有为字符串的串联操作提供运算符,可以直接连接或使用空格连接。
awk 'BEGIN{print ("one" "two")}' # "onetwo"
awk 'BEGIN{print ("one""two")}'
awk 'BEGIN{a="one";b="two";print (a b)}'
注意:字符串串联虽然方便,但是要考虑串联的优先级。例如下面的:
# 下面第一个串联成功,第二个串联失败,
# 因为串联优先级低于加减运算,等价于`12 (" " -23)`
# 即:先转为数值0-23,再转为字符串12-23
$ awk 'BEGIN{a="one";b="two";print (12 " " 23)}'
12 23
$ awk 'BEGIN{a="one";b="two";print (12 " " -23)}'
12-23
正则表达式字面量
普通正则:
/[0-9]+/- 匹配方式:
"str" ~ /pattern/或"str" !~ /pattern/ - 匹配结果返回值为0(匹配失败)或1(匹配成功)
- 任何单独出现的
/pattern/都等价于$0 ~ /pattern/-
if(/pattern/)等价于if($0 ~ /pattern/) - 坑1:
a=/pattern/等价于将$0 ~ /pattern/的匹配返回值(0或1)赋值给a - 坑2:
/pattern/ ~ $1等价于$0 ~ /pattern/ ~ $1,表示用$1去匹配0或1 - 坑3:
/pattern/作为参数传给函数时,传递的是$0~/pat/的结果0或1 - 坑4.坑5.坑6...
-
强类型的正则字面量(gawk 4.2.0才支持):

gawk支持的正则
. # 匹配任意字符,包括换行符
^
$
[...]
[^...]
|
+
*
?
()
{m}
{m,}
{m,n}
{,n}
[:lower:]
[:upper:]
[:alpha:]
[:digit:]
[:alnum:]
[:xdigit:]
[:blank:]
[:space:]
[:punct:]
[:graph:]
[:print:]
[:cntrl:]
以下是gawk支持的:
\y 匹配单词左右边界部分的空字符位置 "hello world"
\B 和\y相反,匹配单词内部的空字符位置,例如"crate" ~ `/c\Brat\Be/`成功
\< 匹配单词左边界
\> 匹配单词右边界
\s 匹配空白字符
\S 匹配非空白字符
\w 匹配单词组成字符(大小写字母、数字、下划线)
\W 匹配非单词组成字符
\` 匹配字符串的绝对行首 "abc\ndef"
\' 匹配字符串的绝对行尾
gawk不支持正则修饰符,所以无法直接指定忽略大小写的匹配。
如果想要实现忽略大小写匹配,则可以将字符串先转换为大写、小写再进行匹配。或者设置预定义变量IGNORECASE为非0值。
# 转换为小写
awk 'tolower($0) ~ /bob/{print $0}' a.txt
# 设置IGNORECASE
awk '/BOB/{print $0}' IGNORECASE=1 a.txt
awk布尔值
在awk中,没有像其它语言一样专门提供true、false这样的关键字。
但它的布尔值逻辑非常简单:

awk '
BEGIN{
if(1){print "haha"}
if("0"){print "hehe"}
if(a=3){print "hoho"} # if(3){print "hoho"}
if(a==3){print "aoao"}
if(/root/){print "heihei"} # $0 ~ /root/
}'
awk中比较操作
strnum类型
awk最基本的数据类型只有string和number(gawk 4.2.0版本之后支持正则表达式类型)。但是,对于用户输入数据(例如从文件中读取的各个字段值),它们理应属于string类型,但有时候它们看上去可能像是数值(例如$2=37),而有时候有需要这些值是数值类型。

注意,strnum类型只针对于awk中除数值常量、字符串常量、表达式计算结果外的数据。例如从文件中读取的字段$1、$2、ARGV数组中的元素等等。
$ echo "30" | awk '{print typeof($0) " " typeof($1)}'
strnum strnum
$ echo "+30" | awk '{print typeof($1)}'
strnum
$ echo "30a" | awk '{print typeof($1)}'
string
$ echo "30 a" | awk '{print typeof($0) " " typeof($1)}'
string strnum
$ echo " +30 " | awk '{print typeof($0) " " typeof($1)}'
strnum strnum
大小比较操作
比较操作符:
< > <= >= != == 大小、等值比较
in 数组成员测试
比较规则:
|STRING NUMERIC STRNUM
-------|-----------------------
STRING |string string string
NUMERIC|string numeric numeric
STRNUM |string numeric numeric
简单来说,string优先级最高,只要string类型参与比较,就都按照string的比较方式,所以可能会进行隐式的类型转换。
其它时候都采用num类型比较。
$ echo ' +3.14' | awk '{print typeof($0) " " typeof($1)}' #strnum strnum
$ echo ' +3.14' | awk '{print($0 == " +3.14")}' #1
$ echo ' +3.14' | awk '{print($0 == "+3.14")}' #0
$ echo ' +3.14' | awk '{print($0 == "3.14")}' #0
$ echo ' +3.14' | awk '{print($0 == 3.14)}' #1
$ echo ' +3.14' | awk '{print($1 == 3.14)}' #1
$ echo ' +3.14' | awk '{print($1 == " +3.14")}' #0
$ echo ' +3.14' | awk '{print($1 == "+3.14")}' #1
$ echo ' +3.14' | awk '{print($1 == "3.14")}' #0
$ echo 1e2 3|awk ’{print ($1<$2)?"true":"false"}’ #false
采用字符串比较时需注意,它是逐字符逐字符比较的。
"11" < "9" # true
"ab" < 99 # false
逻辑运算
&& 逻辑与
|| 逻辑或
! 逻辑取反
expr1 && expr2 # 如果expr1为假,则不用计算expr2
expr1 || expr2 # 如果expr1为真,则不用计算expr2
# 注:
# 1. && ||会短路运算
# 2. !优先级高于&&和||
# 所以`! expr1 && expr2`等价于`(! expr1) && expr2`
!可以将数据转换成数值的1或0,取决于数据是布尔真还是布尔假。!!可将数据转换成等价布尔值的1或0。
$ awk 'BEGIN{print(!99)}' # 0
$ awk 'BEGIN{print(!"ab")}' # 0
$ awk 'BEGIN{print(!0)}' # 1
$ awk 'BEGIN{print(!ab)}' # 1,因为ab变量不存在
$ awk 'BEGIN{print(!!99)}' # 1
$ awk 'BEGIN{print(!!"ab")}' # 1
$ awk 'BEGIN{print(!!0)}' # 0
$ awk 'BEGIN{print(!!ab)}' # 0
由于awk中的变量未赋值时默认初始化为空字符串或数值0,也就是布尔假。那么可以直接对一个未赋值的变量执行!操作。
下面是一个非常有意思的awk技巧,它通过多次!对一个flag取反来实现只输出指定范围内的行。
# a.txt
$1==1{flag=!flag;print;next} # 在匹配ID=1的行时,flag=1
flag{print} # 将输出ID=2,3,4,5的行
$1==5{flag=!flag;next} # ID=5时,flag=0
借此,就可以让awk实现一个多行处理模式。例如,将指定范围内的数据保存到一个变量当中去。
$1==1{flag=!flag;next}
flag{multi_line=multi_line$0"\n"}
$1==5{flag=!flag;next}
END{printf multi_line}
运算符优先级
优先级从高到低:man awk
()
$ # $(2+2)
++ --
^ **
+ - ! # 一元运算符
* / %
+ -
space # 这是字符连接操作 `12 " " 23` `12 " " -23`
| |&
< > <= >= != == # 注意>即是大于号,也是print/printf的重定向符号
~ !~
in
&&
||
?:
= += -= *= /= %= ^=
对于相同优先级的运算符,通常都是从左开始运算,但下面2种例外,它们都从右向左运算:
- 赋值运算:如
= += -= *= - 幂运算
a - b + c => (a - b) + c
a = b = c => a =(b = c)
2**2**3 => 2**(2**3)
再者,注意print和printf中出现的>符号,这时候它表示的是重定向符号,不能再出现优先级比它低的运算符,这时可以使用括号改变优先级。例如:
awk 'BEGIN{print "foo" > a < 3 ? 2 : 1)' # 语法错误
awk 'BEGIN{print "foo" > (a < 3 ? 2 : 1)}' # 正确
流程控制语句
注:awk中语句块没有作用域,都是全局变量。
if (condition) statement [ else statement ]
expr1?expr2:expr3
while (condition) statement
do statement while (condition)
for (expr1; expr2; expr3) statement
for (var in array) statement
break
continue
next
nextfile
exit [ expression ]
{ statements }
switch (expression) {
case value|regex : statement
...
[ default: statement ]
}
代码块
{statement}
if...else
# 单独的if
if(cond){
statements
}
# if...else
if(cond1){
statements1
} else {
statements2
}
# if...else if...else
if(cond1){
statements1
} else if(cond2){
statements2
} else if(cond3){
statements3
} else{
statements4
}
搞笑题:妻子告诉程序员老公,去买一斤包子,如果看见卖西瓜的,就买两个。结果是买了两个包子回来。
# 自然语言的语义
买一斤包子
if(有西瓜){
买两个西瓜
}
# 程序员理解的语义
if(没有西瓜){
买一斤包子
}else{
买两个包子
}
awk '
BEGIN{
mark = 999
if (mark >=0 && mark < 60) {
print "学渣"
} else if (mark >= 60 && mark < 90) {
print "还不错"
} else if (mark >= 90 && mark <= 100) {
print "学霸"
} else {
print "错误分数"
}
}
'
三目运算符?:
expr1 ? expr2 : expr3
if(expr1){
expr2
} else {
expr3
}
awk 'BEGIN{a=50;b=(a>60) ? "及格" : "不及格";print(b)}'
awk 'BEGIN{a=50; a>60 ? b="及格" : b="不及格";print(b)}'
switch...case
switch (expression) {
case value1|regex1 : statements1
case value2|regex2 : statements2
case value3|regex3 : statements3
...
[ default: statement ]
}
awk 中的switch分支语句功能较弱,只能进行等值比较或正则匹配。
各分支结尾需使用break来终止。
{
switch($1){
case 1:
print("Monday")
break
case 2:
print("Tuesday")
break
case 3:
print("Wednesday")
break
case 4:
print("Thursday")
break
case 5:
print("Friday")
break
case 6:
print("Saturday")
break
case 7:
print("Sunday")
break
default:
print("What day?")
break
}
}
分支穿透:
{
switch($1){
case 1:
case 2:
case 3:
case 4:
case 5:
print("Weekday")
break
case 6:
case 7:
print("Weekend")
break
default:
print("What day?")
break
}
}
while和do...while
while(condition){
statements
}
do {
statements
} while(condition)
while先判断条件再决定是否执行statements,do...while先执行statements再判断条件决定下次是否再执行statements。
awk 'BEGIN{i=0;while(i<5){print i;i++}}'
awk 'BEGIN{i=0;do {print i;i++} while(i<5)}'
多数时候,while和do...while是等价的,但如果第一次条件判断失败,则do...while和while不同。
awk 'BEGIN{i=0;while(i == 2){print i;i++}}'
awk 'BEGIN{i=0;do {print i;i++} while(i ==2 )}'
所以,while可能一次也不会执行,do...while至少会执行一次。
一般用while,do...while相比while来说,用的频率非常低。
for循环
for (expr1; expr2; expr3) {
statement
}
for (idx in array) {
statement
}
break和continue
break可退出for、while、do...while、switch语句。
continue可让for、while、do...while进入下一轮循环。
awk '
BEGIN{
for(i=0;i<10;i++){
if(i==5){
break
}
print(i)
}
# continue
for(i=0;i<10;i++){
if(i==5)continue
print(i)
}
}'
next和nextfile
next会在当前语句处立即停止后续操作,并读取下一行,进入循环顶部。
例如,输出除第3行外的所有行。
awk 'NR==3{next}{print}' a.txt
awk 'NR==3{getline}{print}' a.txt
nextfile会在当前语句处立即停止后续操作,并直接读取下一个文件,并进入循环顶部。
例如,每个文件只输出前2行:
awk 'FNR==3{nextfile}{print}' a.txt a.txt
exit
exit [exit_code]
直接退出awk程序。
注意,END语句块也是exit操作的一部分,所以在BEGIN或main段中执行exit操作,也会执行END语句块。
如果exit在END语句块中执行,则立即退出。
所以,如果真的想直接退出整个awk,则可以先设置一个flag变量,然后在END语句块的开头检查这个变量再exit。
BEGIN{
...code...
if(cond){
flag=1
exit
}
}
{}
END{
if(flag){
exit
}
...code...
}
awk '
BEGIN{print "begin";flag=1;exit}
{}
END{if(flag){exit};print "end2"}
'
exit可以指定退出状态码,如果触发了两次exit操作,即BEGIN或main中的exit触发了END中的exit,且END中的exit没有指定退出状态码时,则采取前一个退出状态码。
$ awk 'BEGIN{flag=1;exit 2}{}END{if(flag){exit 1}}'
$ echo $?
1
$ awk 'BEGIN{flag=1;exit 2}{}END{if(flag){exit}}'
$ echo $?
2
数组
awk数组特性:
- awk的数组是关联数组(即key/value方式的hash数据结构),索引下标可为数值(甚至是负数、小数等),也可为字符串
- 在内部,awk数组的索引全都是字符串,即使是数值索引在使用时内部也会转换成字符串
- awk的数组元素的顺序和元素插入时的顺序很可能是不相同的
- awk数组支持数组的数组
awk访问、赋值数组元素
arr[idx]
arr[idx] = value
索引可以是整数、负数、0、小数、字符串。如果是数值索引,会按照CONVFMT变量指定的格式先转换成字符串。
例如:
awk '
BEGIN{
arr[1] = 11
arr["1"] = 111
arr["a"] = "aa"
arr[-1] = -11
arr[4.3] = 4.33
# 本文来自骏马金龙:www.junmajinlong.com
print arr[1] # 111
print arr["1"] # 111
print arr["a"] # aa
print arr[-1] # -11
print arr[4.3] # 4.33
}
'
通过索引的方式访问数组中不存在的元素时,会返回空字符串,同时会创建这个元素并将其值设置为空字符串。
awk '
BEGIN{
arr[-1]=3;
print length(arr); # 1
print arr[1];
print length(arr) # 2
}'
awk数组长度
awk提供了length()函数来获取数组的元素个数,它也可以用于获取字符串的字符数量。还可以获取数值转换成字符串后的字符数量。
awk 'BEGIN{arr[1]=1;arr[2]=2;print length(arr);print length("hello")}'
awk删除数组元素
-
delete arr[idx]:删除数组arr[idx]元素- 删除不存在的元素不会报错
-
delete arr:删除数组所有元素
$ awk 'BEGIN{arr[1]=1;arr[2]=2;arr[3]=3;delete arr[2];print length(arr)}'
2
awk检测是否是数组
isarray(arr)可用于检测arr是否是数组,如果是数组则返回1,否则返回0。
typeof(arr)可返回数据类型,如果arr是数组,则其返回"array"。
awk 'BEGIN{
arr[1]=1;
print isarray(arr);
print (typeof(arr) == "array")
}'
awk测试元素是否在数组中
不要使用下面的方式来测试元素是否在数组中:
if(arr["x"] != ""){...}
这有两个问题:
- 如果不存在arr["x"],则会立即创建该元素,并将其值设置为空字符串
- 有些元素的值本身就是空字符串
应当使用数组成员测试操作符in来测试:
# 注意,idx不要使用index,它是一个内置函数
if (idx in arr){...}
它会测试索引idx是否在数组中,如果存在则返回1,不存在则返回0。
awk '
BEGIN{
# 本文来自骏马金龙:www.junmajinlong.com
arr[1]=1;
arr[2]=2;
arr[3]=3;
arr[1]="";
delete arr[2];
print (1 in arr); # 1
print (2 in arr); # 0
}'
awk遍历数组
awk提供了一种for变体来遍历数组:
for(idx in arr){print arr[idx]}
因为awk数组是关联数组,元素是不连续的,也就是说没有顺序。遍历awk数组时,顺序是不可预测的。
例如:
# 本文来自骏马金龙:www.junmajinlong.com
awk '
BEGIN{
arr["one"] = 1
arr["two"] = 2
arr["three"] = 3
arr["four"] = 4
arr["five"] = 5
for(i in arr){
print i " -> " arr[i]
}
}
'
此外,不要随意使用for(i=0;i<length(arr);i++)来遍历数组,因为awk数组是关联数组。但如果已经明确知道数组的所有元素索引都位于某个数值范围内,则可以使用该方式进行遍历。
例如:
# 本文来自骏马金龙:www.junmajinlong.com
awk '
BEGIN{
arr[1] = "one"
arr[2] = "two"
arr[3] = "three"
arr[4] = "four"
arr[5] = "five"
arr[10]= "ten"
for(i=0;i<=10;i++){
if(i in arr){
print arr[i]
}
}
}
'
awk复杂索引的数组
在awk中,很多时候单纯的一个数组只能存放两个信息:一个索引、一个值。但在一些场景下,这样简单的存储能力在处理复杂需求的时候可能会捉襟见肘。
为了存储更多信息,方式之一是将第3份、第4份等信息全部以特殊方式存放到值中,但是这样的方式在实际使用过程中并不方便,每次都需要去分割值从而取出各部分的值。
另一种方式是将第3份、第4份等信息存放在索引中,将多份数据组成一个整体构成一个索引。
gawk中提供了将多份数据信息组合成一个整体当作一个索引的功能。默认方式为arr[x,y],其中x和y是要结合起来构建成一个索引的两部分数据信息。逗号称为下标分隔符,在构建索引时会根据预定义变量SUBSEP的值将多个索引组合起来。所以arr[x,y]其实完全等价于arr[x SUBSEP y]。
例如,如果SUBSEP设置为"@",那么arr[5,12] = 512存储时,其真实索引为5@12,所以要访问该元素需使用arr["5@12"]。
SUBSEP的默认值为\034,它是一个不可打印的字符,几乎不可能会出现在字符串当中。
如果我们愿意的话,我们也可以自己将多份数据组合起来去构建成一个索引,例如arr[x" "y]。但是awk提供了这种更为简便的方式,直接用即可。
为了测试这种复杂数组的索引是否在数组中,可以使用如下方式:
arr["a","b"] = 12
if (("a", "b") in arr){...}
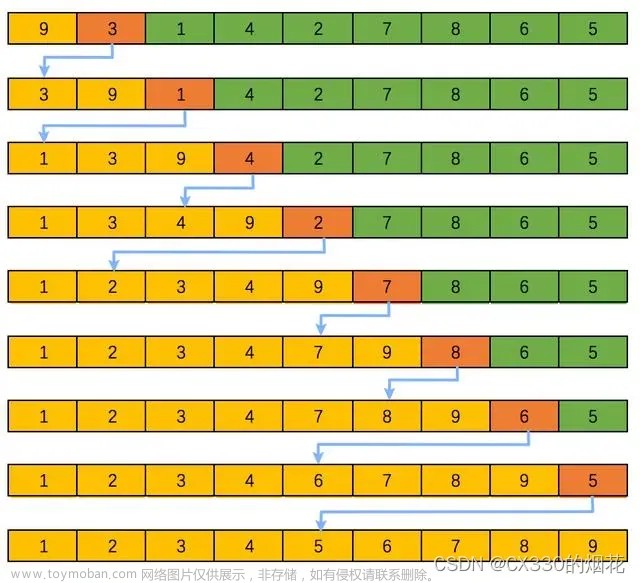
例如,顺时针倒转下列数据:
1 2 3 4 5 6
2 3 4 5 6 1
3 4 5 6 1 2
4 5 6 1 2 3
结果:
4 3 2 1
5 4 3 2
6 5 4 3
1 6 5 4
2 1 6 5
3 2 1 6
{
nf = NF
nr = NR
for(i=1;i<=NF;i++){
arr[NR,i] = $i
}
}
END{
for(i=1;i<=nf;i++){
for(j=nr;j>=1;j--){
if(j%nr == 1){
printf "%s\n", arr[j,i]
}else {
printf "%s ", arr[j,i]
}
}
}
}
awk子数组
子数组是指数组中的元素也是一个数组,即Array of Array,它也称为子数组(subarray)。
awk也支持子数组,在效果上即是嵌套数组或多维数组。
a[1][1] = 11
a[1][2] = 12
a[1][3] = 13
a[2][1] = 21
a[2][2] = 22
a[2][3] = 23
a[2][4][1] = 241
a[2][4][2] = 242
a[2][4][1] = 241
a[2][4][3] = 243
通过如下方式遍历二维数组:

awk指定数组遍历顺序
由于awk数组是关联数组,默认情况下,for(idx in arr)遍历数组时顺序是不可预测的。
但是gawk提供了PROCINFO["sorted_in"]来指定遍历的元素顺序。它可以设置为两种类型的值:
- 设置为用户自定义函数
- 设置为下面这些awk预定义好的值:
-
@unsorted:默认值,遍历时无序 -
@ind_str_asc:索引按字符串比较方式升序遍历 -
@ind_str_desc:索引按字符串比较方式降序遍历 -
@ind_num_asc:索引强制按照数值比较方式升序遍历。所以无法转换为数值的字符串索引将当作数值0进行比较 -
@ind_num_desc:索引强制按照数值比较方式降序遍历。所以无法转换为数值的字符串索引将当作数值0进行比较 -
@val_type_asc:按值升序比较,此外数值类型出现在前面,接着是字符串类型,最后是数组类(即认为num<str<arr) -
@val_type_desc:按值降序比较,此外数组类型出现在前面,接着是字符串类型,最后是数值型(即认为num<str<arr) -
@val_str_asc:按值升序比较,数值转换成字符串再比较,而数组出现在尾部(即认str<arr) -
@val_str_desc:按值降序比较,数值转换成字符串再比较,而数组出现在头部(即认str<arr) -
@val_num_asc:按值升序比较,字符串转换成数值再比较,而数组出现在尾部(即认num<arr) -
@val_num_desc:按值降序比较,字符串转换成数值再比较,而数组出现在头部(即认为num<arr)
-
例如:
awk '
BEGIN{
arr[1] = "one"
arr[2] = "two"
arr[3] = "three"
arr["a"] ="aa"
arr["b"] ="bb"
arr[10]= "ten"
#PROCINFO["sorted_in"] = "@ind_num_asc"
#PROCINFO["sorted_in"] = "@ind_str_asc"
PROCINFO["sorted_in"] = "@val_str_asc"
for(idx in arr){
print idx " -> " arr[idx]
}
}'
a -> aa
b -> bb
1 -> one
2 -> two
3 -> three
10 -> ten
# 本文来自骏马金龙:www.junmajinlong.com
如果指定为用户自定义的排序函数,其函数格式为:
function sort_func(i1,v1,i2,v2){
...
return <0;0;>0
}
其中,i1和i2是每次所取两个元素的索引,v1和v2是这两个索引的对应值。
如果返回值小于0,则表示i1在i2前面,i1先被遍历。如果等于0,则表示i1和i2具有等值关系,它们的遍历顺序不可保证。如果大于0,则表示i2先于i1被遍历。
例如,对数组元素按数值大小比较来决定遍历顺序。
awk '
function cmp_val_num(i1, v1, i2, v2){
if ((v1 - v2) < 0) {
return -1
} else if ((v1 - v2) == 0) {
return 0
} else {
return 1
}
# return (v1-v2)
}
NR > 1 {
arr[$0] = $4
}
END {
PROCINFO["sorted_in"] = "cmp_val_num"
for (i in arr) {
print i
}
}' a.txt
再比如,按数组元素值的字符大小来比较。
function cmp_val_str(i1,v1,i2,v2) {
v1 = v1 ""
v2 = v2 ""
if(v1 < v2){
return -1
} else if(v1 == v2){
return 0
} else {
return 1
}
# return (v1 < v2) ? -1 : (v1 != v2)
}
NR>1{
arr[$0] = $2
}
END{
PROCINFO["sorted_in"] = "cmp_val_str"
for(line in arr)
{
print line
}
}
再比如,对元素值按数值升序比较,且相等时再按第一个字段ID进行数值降序比较。
awk '
function cmp_val_num(i1,v1,i2,v2, a1,a2) {
if (v1<v2) {
return - 1
} else if(v1 == v2){
split(i1, a1, SUBSEP)
split(i2, a2, SUBSEP)
return a2[2] - a1[2]
} else {
return 1
}
}
NR>1{
arr[$0,$1] = $4
}
END{
PROCINFO["sorted_in"] = "cmp_val_num"
for(str in arr){
split(str, a, SUBSEP)
print a[1]
}
}
' a.txt
上面使用的arr[x,y]来存储额外信息,下面使用arr[x][y]多维数组的方式来存储额外信息实现同样的排序功能。
NR>1{
arr[NR][$0] = $4
}
END{
PROCINFO["sorted_in"] = "cmp_val_num"
for(nr in arr){
for(line in arr[nr]){
print line
}
# 本文来自骏马金龙:www.junmajinlong.com
}
}
function cmp_val_num(i1,v1,i2,v2, ii1,ii2){
# 获取v1/v2的索引,即$0的值
for(ii1 in v1){ }
for(ii2 in v2){ }
if(v1[ii1] < v2[ii2]){
return -1
}else if(v1[ii1] > v2[ii2]){
return 1
}else{
return (i2 - i1)
}
}
此外,gawk还提供了两个内置函数asort()和asorti()来对数组进行排序。
awk ARGC和ARGV
预定义变量ARGV是一个数组,包含了所有的命令行参数。该数组使用从0开始的数值作为索引。
预定义变量ARGC初始时是ARGV数组的长度,即命令行参数的数量。
ARGV数组的数量和ARGC的值只有在awk刚开始运行的时候是保证相等的。
$ awk -va=1 -F: '
BEGIN{
print ARGC;
for(i in ARGV){
print "ARGV[" i "]= " ARGV[i]
}
}' b=3 a.txt b.txt
4
ARGV[0]= awk
ARGV[1]= b=3
ARGV[2]= a.txt
ARGV[3]= b.txt
awk读取文件是根据ARGC的值来进行的,有点类似于如下伪代码形式:
while(i=1;i<ARGC;i++){
read from ARGV[i]
}
默认情况下,awk在读完ARGV中的一个文件时,会自动从它的下一个元素开始读取,直到读完所有文件。
直接减小ARGC的值,会导致awk不会读取尾部的一些文件。此外,增减ARGC的值,都不会影响ARGV数组,仅仅只是影响awk读取文件的数量。
# 不会读取b.txt
awk 'BEGIN{ARGC=2}{print}' a.txt b.txt
# 读完b.txt后自动退出
awk 'BEGIN{ARGC=5}{print}' a.txt b.txt
可以将ARGV中某个元素赋值为空字符串"",awk在选择下一个要读取的文件时,会自动忽略ARGV中的空字符串元素。
也可以delete ARGV[i]的方式来删除ARGV中的某元素。
用户手动增、删ARGV元素时,不会自动修改ARGC,而awk读取文件时是根据ARGC值来确定的。所以,在增加ARGV元素之后,要手动的去增加ARGC的值。
# 不会读取b.txt文件
$ awk 'BEGIN{ARGV[2]="b.txt"}{print}' a.txt
# 会读取b.txt文件
$ awk 'BEGIN{ARGV[2]="b.txt";ARGC++}{print}' a.txt
对awk ARGC和ARGV进行操刀
awk判断命令行中给定文件是否可读
awk命令行中可能会给出一些不存在或无权限或其它原因而无法被awk读取的文件名,这时可以判断并从中剔除掉不可读取的文件。
- 排除命令行尾部(非选项型参数)的var=val、-、和/dev/stdin这3种特殊情况
- 如果不可读,则从ARGV中删除该参数
- 剩下的都是可在main代码段正常读取的文件
BEGIN{
for(i=1;i<ARGC;i++){
if(ARGV[i] ~ /[a-zA-Z_][a-zA-Z0-9_]*=.*/ \
|| ARGV[i]=="-" || ARGV[i]=="/dev/stdin"){
continue
} else if((getline var < ARGV[i]) < 0){
delete ARGV[i]
} else{
close(ARGV[i])
}
}
}
awk 自定义函数
可以定义一个函数将多个操作整合在一起。函数定义之后,可以到处多次调用,从而方便复用。
使用function关键字来定义函数:
function func_name([parameters]){
function_body
}
对于gawk来说,也支持func关键字来定义函数。
func func_name(){}
函数可以定义在下面使用下划线的地方:
awk '_ BEGIN{} _ MAIN{} _ END{} _'
无论函数定义在哪里,都能在任何地方调用,因为awk在BEGIN之前,会先编译awk代码为内部格式,在这个阶段会将所有函数都预定义好。
例如:
awk '
BEGIN{
f()
f()
f()
}
function f(){
print "星期一"
print "星期二"
print "星期三"
print "星期四"
print "星期五"
print "星期六"
print "星期日"
}
'
awk 函数的return语句
如果想要让函数有返回值,那么需要在函数中使用return语句。
return语句也可以用来立即结束函数的执行。
例如:
awk '
function add(){
return 40
}
BEGIN{
print add()
res = add()
print res
}
'
如果不使用return或return没有参数,则返回值为空,即空字符串。
awk '
function f1(){ }
function f2(){return }
function f3(){return 3}
BEGIN{
print "-"f1()"-"
print "-"f2()"-"
print "-"f3()"-"
}
'
awk函数参数
为了让函数和调用者能够进行数据的交互,可以使用参数。
awk '
function f(a,b){
print a
print b
return a+b
}
BEGIN{
x=10
y=20
res = f(x,y)
print res
print f(x,y)
}
'
例如,实现一个重复某字符串指定次数的函数:
awk '
function repeat(str,cnt ,res_str){
for(i=0;i<cnt;i++){
res_str = res_str""str
}
return res_str
}
BEGIN{
print repeat("abc",3)
print repeat("-",30)
}
'
调用函数时,实参数量可以比形参数量少,也可以比形参数量多。但是,在多于形参数量时会给出警告信息。
awk '
function f(a,b){
print a
print b
return a+b
}
BEGIN{
x=10
y=20
print "---1----"
print "-"f()"-" # 不传递参数
print "---2----"
print "-"f(30)"-" # 传递1个参数
print "---3----"
print "-"f(10,20,30)"-" # 传递多个参数
}
'
awk函数参数数据类型冲突问题
如果函数内部使用参数的类型和函数外部变量的类型不一致,会出现数据类型不同而导致报错。
awk '
function f(a){
a[1]=30
}
BEGIN{
a="hello world"
f(a) # 报错
f(x)
x=10 # 报错
}
'
函数内部参数对应的是数组,那么外面对应的也必须是数组类型。
awk参数按值传递还是按引用传递
在调用函数时,将数据作为函数参数传递给函数时,有两种传递方式:

# 传递普通变量:按值拷贝
awk '
function modify(a){
a=30
print a
}
BEGIN{
a=40
modify(a)
print a
}
'
# 传递数组:按引用拷贝
awk '
function modify(a){
a[1]=20
}
BEGIN{
a[1]=10
modify(a)
print a[1]
}
'
awk作用域问题
awk只有在函数参数中才是局部变量,其它地方定义的变量均为全局变量。
函数内部新增的变量是全局变量,会影响到全局,所以在函数退出后仍然能访问。例如上面的e变量。
awk '
function f(){
a=30 # 新增的变量,是全局变量
print "in f: " a
}
BEGIN{
a=40
f()
print a # 30
}
'
函数参数会遮掩全局同名变量,所以在函数执行时,无法访问到或操作与参数同名的全局变量,函数退出时会自动撤掉遮掩,这时才能访问全局变量。所以,参数具有局部效果。
awk '
function f(a){
print a # 50,按值拷贝,和全局a已经没有关系
a=40
print a # 40
}
BEGIN{
a=50
f(a)
print a # 50,函数退出,重新访问全局变量
}
'
由于函数内部新增变量均为全局变量,awk也没有提供关键字来修饰一个变量使其成为局部变量。所以,awk只能将本该出现在函数体内的局部变量放在参数列表中,只要调用函数时不要为这些参数传递数据即可,从而实现局部变量的效果。
awk '
function f(a,b ,c,d){
# a,b是参数,调用时需传递两个参数
# c,d是局部变量,调用时不要给c和d传递数据
a=30
b=40
c=50
d=60
e=70 # 全局变量
print a,b,c,d,e # 30 40 50 60 70
}
BEGIN{
a=31
b=41
c=51
d=61
f(a,b) # 调用函数时值传递两个参数
print a,b,c,d,e # 31 41 51 61 70
}
'
所以,awk对函数参数列表做了两类区分:
- arguments:调用函数时传递的参数
- local variables:调用函数时省略的参数

local variables是awk实现真正局部变量的技巧,只是因为函数内部新增的变量都是全局变量,所以退而求其次将其放在参数列表上来实现局部变量。
自定义函数示例
1.一次性读取一个文件所有数据
function readfile(file ,rs_bak,data){
rs_bak=RS
RS="^$"
if ( (getline data < file) < 0 ){
print "read file failed"
exit 1
}
close(file)
RS=rs_bak
return data
}
/^1/{
print $0
content = readfile("c.txt")
print content
}
将RS设置为^$是永远不可能出现的分隔符,除非这个文件为空文件。
2.重读文件
实现一个rewind()功能来重置文件偏移指针,从而模拟实现重读当前文件。
function rewind( i){
# 将当前正在读取的文件添加到ARGV中当前文件的下一个元素
for(i=ARGC;i>ARCIND;i--){
ARGV[i] = ARGV[i-1]
}
# 随着增加ARGC,以便awk能够读取到因ARGV增加元素后的最后一个文件
ARGC++
# 直接进入下一个文件
nextfile
}
要注意可能出现无限递归的场景:
awk -f rewind.awk 'NR==3{rewind()}{print FILENAME, FNR, $0}' a.txt
# 下面这个会无限递归,因为FNR==3很可能每次重读时都会为真
awk -f rewind.awk 'FNR==3{rewind()}{print FILENAME, FNR, $0}' a.txt
3.格式化数组的输出
实现一个a2s()函数。
BEGIN{
arr["zhangsan"]=21
arr["lisi"]=22
arr["wangwu"]=23
print a2s(arr)
}
function a2s(arr ,content,i,cnt){
for(i in arr){
if(cnt){
content=content""(sprintf("\t%s:%s\n",i,arr[i]))
} else {
content=content""(sprintf("\n\t%s:%s\n",i,arr[i]))
}
cnt++
}
return "{"content"}"
}
4.禁用命令行尾部的赋值语句
awk '{}' ./a=b a.txt中,a=b会被awk识别为变量赋值操作。但是,如果用户想要处理的正好是包含了等号的文件名,则应当去禁用该赋值操作。
禁用的方式很简单,只需为其加上一个路径前缀./即可。
为了方便控制,可通过-v设置一个flag类型的选项标记。
function disable_assigns(argc,argv, i){
for(i=1;i<argc;i++){
if(argv[i] ~ /[[:alpha:]_][[:alnum:]_]*=.*/){
argv[i] = ("./"argv[i])
}
}
}
BEGIN{
if(assign_flag){
disable_assigns(ARGC,ARGV)
}
}
那么,调用awk时采用如下方式:
awk -v assign_flag=1 -f assigns.awk '{print}' a=b.txt a.txt
awk选项、内置变量
选项
-e program-text
--source program-text
指定awk程序表达式,可结合-f选项同时使用
在使用了-f选项后,如果不使用-e,awk program是不会执行的,它会被当作ARGV的一个参数
-f program-file
--file program-file
从文件中读取awk源代码来执行,可指定多个-f选项
-F fs
--field-separator fs
指定输入字段分隔符(FS预定义变量也可设置)
-n
--non-decimal-data
识别文件输入中的8进制数(0开头)和16进制数(0x开头)
echo '030' | awk -n '{print $1+0}'
-o [filename]
格式化awk代码。
不指定filename时,则默认保存到awkprof.out
指定为`-`时,表示输出到标准输出
-v var=val
--assign var=val
在BEGIN之前,声明并赋值变量var,变量可在BEGIN中使用
预定义变量
预定义变量分为两类:控制awk工作的变量和携带信息的变量。
第一类:控制AWK工作的预定义变量
-
RS:输入记录分隔符,默认为换行符\n,参考RS -
IGNORECASE:默认值为0,表示所有的正则匹配不忽略大小写。设置为非0值(例如1),之后的匹配将忽略大小写。例如在BEGIN块中将其设置为1,将使FS、RS都以忽略大小写的方式分隔字段或分隔record -
FS:读取记录后,划分为字段的字段分隔符。参考FS -
FIELDWIDTHS:以指定宽度切割字段而非按照FS。参考FIELDWIDTHS -
FPAT:以正则匹配匹配到的结果作为字段,而非按照FS划分。参考FPAT -
OFS:print命令输出各字段列表时的输出字段分隔符,默认为空格" " -
ORS:print命令输出数据时在尾部自动添加的记录分隔符,默认为换行符\n -
CONVFMT:在awk中数值隐式转换为字符串时,将根据CONVFMT的格式按照sprintf()的方式自动转换为字符串。默认值为"%.6g -
OFMT:在print中,数值会根据OFMT的格式按照sprintf()的方式自动转换为字符串。默认值为"%.6g
第二类:携带信息的预定义变量
-
ARGC和ARGV:awk命令行参数的数量、命令参数的数组。参考ARGC和ARGV -
ARGIND:awk当前正在处理的文件在ARGV中的索引位置。所以,如果awk正在处理命令行参数中的某文件,则ARGV[ARGIND] == FILENAME为真 -
FILENAME:awk当前正在处理的文件(命令行中指定的文件),所以在BEGIN中该变量值为空 -
ENVIRON:保存了Shell的环境变量的数组。例如ENVIRON["HOME"]将返回当前用户的家目录 -
NR:当前已读总记录数,多个文件从不会重置为0,所以它是一直叠加的- 可以直接修改NR,下次读取记录时将在此修改值上自增
-
FNR:当前正在读取文件的第几条记录,每次打开新文件会重置为0- 可以直接修改FNR,下次读取记录时将在此修改值上自增
-
NF:当前记录的字段数,参考NF -
RT:在读取记录时真正的记录分隔符,参考RT -
RLENGTH:match()函数正则匹配成功时,所匹配到的字符串长度,如果匹配失败,该变量值为-1 -
RSTART:match()函数匹配成功时,其首字符的索引位置,如果匹配失败,该变量值为0 -
SUBSEP:arr[x,y]中下标分隔符构建成索引时对应的字符,默认值为\034,是一个不太可能出现在字符串中的不可打印字符。参考复杂数组
awk预定义内置函数
预定义函数分为几类:
- 数值类内置函数
- 字符串类内置函数
- 时间类内置函数
- 位操作内置函数
- 数据类型相关内置函数:isarray()、typeof()
- IO类内置函数:close()、system()、fflush()
awk数值类内置函数
int(expr) 截断为整数:int(123.45)和int("123abc")都返回123,int("a123")返回0
sqrt(expr) 返回平方根
rand() 返回[0,1)之间的随机数,默认使用srand(1)作为种子值
srand([expr]) 设置rand()种子值,省略参数时将取当前时间的epoch值(精确到秒的epoch)作为种子值
例如:
$ awk 'BEGIN{srand();print rand()}'
0.0379114
$ awk 'BEGIN{srand();print rand()}'
0.0779783
$ awk 'BEGIN{srand(2);print rand()}'
0.893104
$ awk 'BEGIN{srand(2);print rand()}'
0.893104
生成[10,100]之间的随机整数。
awk 'BEGIN{srand();print 10+int(91*rand())}'
awk字符串类内置函数
注意,awk中涉及到字符索引的函数,索引位都是从1开始计算,和其它语言从0开始不一样。
基本函数
-
sprintf(format, expression1, ...):返回格式化后的字符串,参考sprintfa=sprintf("%s\n","abc")
-
length():返回字符串字符数量、数组元素数量、或数值转换为字符串后的字符数量awk ' BEGIN{ print length(1.23) # 4 # CONVFMT %.6g print 1.234567 # 1.23457 print length(1.234567) # 7 print length(122341223432.1213241234) # 11 }' -
strtonum(str):将字符串转换为十进制数值- 如果str以0开头,则将其识别为8进制
- 如果str以0x或0X开头,则将其识别为16进制
-
tolower(str):转换为小写 -
toupper(str):转换为大写 -
index(str,substr):从str中搜索substr(子串),返回搜索到的索引位置(索引从1开始),搜索不到则返回0
awk substr()
-
substr(string,start[,length]):从string中截取子串
start是截取的起始索引位(索引位从1开始而非0),length表示截取的子串长度。如果省略length,则表示从start开始截取剩余所有字符。
awk '
BEGIN{
str="abcdefgh"
print substr(str,3) # cdefgh
print substr(str,3,3) # cde
}
'
如果start值小于1,则将其看作为1对待,如果start大于字符串的长度,则返回空字符串。
如果length小于或等于0,则返回空字符串。
awk split()和patsplit()
-
split(string, array [, fieldsep [, seps ] ]):将字符串分割后保存到数组array中,数组索引从1开始存储。并返回分割得到的元素个数
其中fieldsep指定分隔符,可以是正则表达式方式的。如果不指定该参数,则默认使用FS作为分隔符,而FS的默认值又是空格。
seps是一个数组,保存了每次分割时的分隔符。
例如:
split("abc-def-gho-pq",arr,"-",seps)
其返回值为4。同时得到的数组a和seps为:
arr[1] = "abc"
arr[2] = "def"
arr[3] = "gho"
arr[4] = "pq"
seps[1] = "-"
seps[2] = "-"
seps[3] = "-"
split在开始工作时,会先清空数组,所以,将split的string参数设置为空,可以用于清空数组。
awk 'BEGIN{arr[1]=1;split("",arr);print length(arr)}' # 0
如果分隔符无法匹配字符串,则整个字符串当作一个数组元素保存到数组array中。
awk 'BEGIN{split("abcde",arr,"-");print arr[1]}' # abcde
-
patsplit(string, array [, fieldpat [, seps ] ]):用正则表达式fieldpat匹配字符串string,将所有匹配成功的部分保存到数组array中,数组索引从1开始存储。返回值是array的元素个数,即匹配成功了多少次
如果省略fieldpat,则默认采用预定义变量FPAT的值。
awk '
BEGIN{
patsplit("abcde",arr,"[a-z]")
print arr[1] # a
print arr[2] # b
print arr[3] # c
print arr[4] # d
print arr[5] # e
}
'
awk match()
-
match(string,reg[,arr]):使用reg匹配string,返回匹配成功的索引位(从1开始计数),匹配失败则返回0。如果指定了arr参数,则arr[0]保存的是匹配成功的字符串,arr[1]、arr[2]、...保存的是各个分组捕获的内容
match匹配时,同时会设置两个预定义变量:RSTART和RLENGTH
- 匹配成功时:
- RSTART赋值为匹配成功的索引位,从1开始计数
- RLENGTH赋值为匹配成功的字符长度
- 匹配失败时:
- RSTART赋值为0
- RLENGTH赋值为-1
例如:
awk '
BEGIN{
where = match("foooobazbarrrr","(fo+).*(bar*)",arr)
print where # 1
print arr[0] # foooobazbarrrr
print arr[1] # foooo
print arr[2] # barrrr
print RSTART # 1
print RLENGTH # 14
}
'
因为match()匹配成功时返回值为非0,而匹配失败时返回值为0,所以可以直接当作条件判断:
awk '
{
if(match($0,/A[a-z]+/,arr)){
print NR " : " arr[0]
}
}
' a.txt
awk sub()和gsub()
sub(regexp, replacement [, target])-
gsub(regexp, replacement [, target]):sub()的全局模式
sub()从字符串target中进行正则匹配,并使用replacement对第一次匹配成功的部分进行替换,替换后保存回target中。返回替换成功的次数,即0或1。
target必须是一个可以赋值的变量名、$N或数组元素名,以便用它来保存替换成功后的结果。不能是字符串字面量,因为它无法保存数据。
如果省略target,则默认使用$0。
需要注意的是,如果省略target,或者target是$N,那么替换成功后将会使用OFS重新计算$0。
awk '
BEGIN{
str="water water everywhere"
#how_many = sub(/at/, "ith", str)
how_many = gsub(/at/, "ith", str)
print how_many # 1
print str # wither water everywhere
}
'
在replacement参数中,可以使用一个特殊的符号&来引用匹配成功的部分。注意sub()和gsub()不能在replacement中使用反向引用\N。
awk '
BEGIN{
str = "daabaaa"
gsub(/a+/,"C&C",str)
print str # dCaaCbaaa
}
'
如果想要在replacement中使用&纯字符,则转义即可。
sub(/a+/,"C\\&C",str)
两根反斜线:
因为awk在正则开始工作时,首先会扫描所有awk代码然后编译成awk的内部格式,扫描期间会解析反斜线转义,使得\\变成一根反斜线。当真正开始运行后,sub()又要解析,这时\&才表示的是对&做转义。
扫描代码阶段称为词法解析阶段,运行解析阶段称为运行时解析阶段。
awk gensub()
gawk支持的gensub(),完全可以取代sub()和gsub()。
-
gensub(regexp, replacement, how [, target]):
可以替代sub()和gsub()。
how指定替换第几个匹配,例如指定为1表示只替换第一个匹配。此外,还可以指定为g或G开头的字符串,表示全局替换。

awk 'BEGIN{
a = "abc def"
b = gensub(/(.+) (.*)/, "\\2 \\1, \\0 , &", "g", a)
print b # def abc, abc def , abc def
}'
awk asort()和asorti()
asort(src,[dest [,how]])asorti(src,[dest [,how]])
asort对数组src的值进行排序,然后将排序后的值的索引改为1、2、3、4...序列。返回src中的元素个数,它可以当作排序后的索引最大值。
asorti对数组src的索引进行排序,然后将排序后的索引值的索引改为1、2、3、4...序列。返回src中的元素个数,它可以当作排序后的索引最大值。
arr["last"] = "de"
arr["first"] = "sac"
arr["middle"] = "cul"
asort(arr)得到:
arr[1] = "cul"
arr[2] = "de"
arr[3] = "sac"
asorti(arr)得到:
arr[1] = "first"
arr[2] = "last"
arr[3] = "middle"
如果指定dest,则将原始数组src备份到dest,然后对dest进行排序,而src保持不变。
how参数用于指定排序时的方式,其值指定方式和PROCINFO["sorted_in"]一致:可以是预定义的排序函数,也可以是用户自定义的排序函数。参考指定数组遍历顺序。
IO类内置函数
-
close(filename [, how]):关闭文件或命令,参考close -
system(command):执行Shell命令,参考system -
fflush([filename]):gawk会按块缓冲模式来缓冲输出结果,使用fflush()会将缓冲数据刷出
从gawk 4.0.2之后的版本(不包括4.0.2),无参数fflush()将刷出所有缓冲数据。
此外,终端设备是行缓冲模式,此时不需要fflush,而重定向到文件、到管道都是块缓冲模式,此时可能需要fflush()。
此外,system()在运行时也会flush gawk的缓冲。特别的,如果system的参数为空字符串system(""),则它不会去启动一个shell子进程而是仅仅执行flush操作。

使用system()来flush:
awk '{print "first";system("echo system");print "second"}' | cat
awk '{print "first";system("");print "second"}' | cat
也可以使用stdbuf -oL命令来强制gawk按行缓冲而非默认的按块缓冲。
stdbuf -oL awk '{print "first";print "second"}' | cat
fflush()也可以指定文件名或命令,表示只刷出到该文件或该命令的缓冲数据。
# 刷出所有流向到标准输出的缓冲数据
awk '{print "first";fflush("/dev/stdout");print "second"}' | cat
最后注意,fflush()刷出缓冲数据不代表发送EOF标记。
数据类型内置函数
-
isarray(var):测试var是否是数组,返回1(是数组)或0(不是数组) -
typeof(var):返回var的数据类型,有以下可能的值:- "array":是一个数组
- "regexp":是一个真正表达式类型,强正则字面量才算是正则类型,如
@/a.*ef/ - "number":是一个number
- "string":是一个string
- "strnum":是一个strnum,参考strnum类型
- "unassigned":曾引用过,但未赋值,例如"print f;print typeof(f)"
- "untyped":从未引用过,也从未赋值过
例如,输出awk进程的内部信息,但跳过数组
awk '
BEGIN{
for(idx in PROCINFO){
if(typeof(PROCINFO[idx]) == "array"){
continue
}
print idx " -> "PROCINFO[idx]
}
}'
时间类内置函数
awk常用于处理日志,它支持简单的时间类操作。有下面3个内置的时间函数:
-
mktime("YYYY MM DD HH mm SS [DST]"):构建一个时间,返回这个时间点的秒级epoch,构建失败则返回-1 -
systime():返回当前系统时间点,返回的是秒级epoch值 -
strftime([format [, timestamp [, utc-flag] ] ]):将时间按指定格式转换为字符串并返回转的结果字符串
注意,awk构建时间时都是返回秒级的epoch值,表示从1970-01-01 00:00:00开始到指定时间已经过的秒数。
awk 'BEGIN{print systime();print mktime("2019 2 29 12 32 59")}'
1572364974
1551414779
awk mktime()
mktime在构建时间时,如果传递的DD给定的值超出了月份MM允许的天数,则自动延申到下个月。例如,指定"2019 2 29 12 30 59"中2月只有28号,所以构建出来的时间是2019-03-01 12:30:59。
此外,其它部分也不限定必须在范围内。例如,2019 2 23 12 32 65的秒超出了59,那么多出来的秒数将进位到分钟。
awk 'BEGIN{
print mktime("2019 2 23 12 32 65") | "xargs -i date -d@{} +\"%F %T\""
}'
2019-02-23 12:33:05
如果某部位的数值为负数,则表示在此时间点基础上减几。例如:
# 2019-02-23 12:00:59基础上减1分钟
$ awk 'BEGIN{print mktime("2019 2 23 12 -1 59") | "xargs -i date -d@{} +\"%F %T\""}'
2019-02-23 11:59:59
# 2019-02-23 00:32:59基础上减1小时
$ awk 'BEGIN{print mktime("2019 2 23 -1 32 59") | "xargs -i date -d@{} +\"%F %T\""}'
2019-02-22 23:32:59
awk strftime()
strftime([format [, timestamp [, utc-flag] ] ])
将指定的时间戳tiemstamp按照给定格式format转换为字符串并返回这个字符串。
如果省略timestamp,则对当前系统时间进行格式化。
如果省略format,则采用PROCINFO["strftime"]的格式,其默认格式为%a %b %e %H:%M%:S %Z %Y。该格式对应于Shell命令date的默认输出结果。
$ awk 'BEGIN{print strftime()}'
Wed Oct 30 00:20:01 CST 2014
$ date
Wed Oct 30 00:20:04 CST 2014
$ awk 'BEGIN{print strftime(PROCINFO["strftime"], systime())}'
Wed Oct 30 00:24:00 CST 2014
支持的格式包括:
%a 星期几的缩写,如Mon、Sun Wed Fri
%A 星期几的英文全名,如Monday
%b 月份的英文缩写,如Oct、Sep
%B 月份的英文全名,如February、October
%C 2位数的世纪,例如1970对应的世纪是19
%y 2位数的年份(00–99),通过年份模以100取得,例如2019/100的余数位19
%Y 四位数年份(如2015)
%m 月份(01–12)
%j 年中天(001–366)
%d 月中天(01–31)
%e 空格填充的月中天
%H 24小时制的小时(00–23)
%I 12小时制的小时(01–12)
%p 12小时制时的AM/PM
%M 分钟数(00–59)
%S 秒数(00–60)
%u 数值的星期几(1–7),1表示星期一
%w 数值的星期几(0–6),0表示星期日
%W 年中第几周(00–53)
%z 时区偏移,格式为"+HHMM",如"+0800"
%Z 时区偏移的英文缩写,如CST
%k 24小时制的时间(0-23),1位数的小时使用空格填充
%l 12小时制的时间(1-12),1位数的小时使用空格填充
%s 秒级epoch
##### 特殊符号
%n 换行符
%t 制表符
%% 百分号%
##### 等价写法:
%x 等价于"%A %B %d %Y"
%F 等价于"%Y-%m-%d",用于表示ISO 8601日期格式
%T 等价于"%H:%M:%S"
%X 等价于"%T"
%r 12小时制的时间部分格式,等价于"%I:%M:%S %p"
%R 等价于"%H:%M"
%c 等价于"%A %B %d %T %Y",如Wed 30 Oct 2015 12:34:48 AM CST
%D 等价于"%m/%d/%y"
%h 等价于"%b"
例如:
$ awk 'BEGIN{print strftime("%s", mktime("2077 11 12 10 23 32"))}'
3403909412
$ awk 'BEGIN{print strftime("%F %T %Z", mktime("2077 11 12 10 23 32"))}'
2077-11-12 10:23:32 CST
$ awk 'BEGIN{print strftime("%F %T %z", mktime("2077 11 12 10 23 32"))}'
2077-11-12 10:23:32 +0800
awk将字符串转换为时间:strptime1()
例如:
2019-11-11T03:42:42+08:00
1.将日期时间字符串中的年月日时分秒全都单独保存起来
2.将年月日时分秒构建成mktime()的字符串格式"YYYY MM DD HH mm SS"
3.使用mktime()可以构建出时间点
function strptime(str, time_str,arr,Y,M,D,H,m,S){
time_str = gensub(/[-T:+]/," ","g",str)
split(time_str, arr, " ")
Y = arr[1]
M = arr[2]
D = arr[3]
H = arr[4]
m = arr[5]
S = arr[6]
# mktime失败返回-1
return mktime(sprintf("%d %d %d %d %d %d", Y,M,D,H,m,S))
}
BEGIN{
str = "2019-11-11T03:42:42+08:00"
print strptime(str)
}
awk将字符串转换为时间:strptime2()
下面是更难一点的,月份使用的是英文或英文缩写,日期时间分隔符也比较特殊。
Sat 26. Jan 15:36:24 CET 2013
function strptime(str, time_str,arr,Y,M,D,H,m,S){
time_str = gensub(/[.:]+/, " ", "g", str)
split(time_str, arr, " ")
Y = arr[8]
M = month_map(arr[3])
D = arr[2]
H = arr[4]
m = arr[5]
S = arr[6]
return mktime(sprintf("%d %d %d %d %d %d", Y,M,D,H,m,S))
}
function month_map(str, mon){
# mon = substr(str,1,3)
# return (((index("JanFebMarAprMayJunJelAugSepOctNovDec", mon)-1)/3)+1)
mon["Jan"] = 1
mon["Feb"] = 2
mon["Mar"] = 3
mon["Apr"] = 4
mon["May"] = 5
mon["Jun"] = 6
mon["Jul"] = 7
mon["Aug"] = 8
mon["Sep"] = 9
mon["Oct"] = 10
mon["Nov"] = 11
mon["Dec"] = 12
return mon[str]
}
BEGIN{
str = "Sat 26. Jan 15:36:24 CET 2013"
print strptime(str)
}
几个常见的gawk扩展
使用扩展的方式:
awk -l ext_name 'BEGIN{}{}END{}'
awk '@load "ext_name";BEGIN{}{}END{}'
1.文件相关的扩展
awk和文件相关的扩展是"filefuncs"。
它支持chdir()、stat()函数。
2.awk文件名匹配扩展
"fnmatch"扩展提供文件名通配。
@load "fnmatch"
result = fnmatch(pattern, string, flags)
3.awk原处修改文件
awk通过加载inplace.awk,也可以实现sed -i类似的功能,即内容直接修改源文件(其本质是先写入临时文件,写完后将临时文件重命名为源文件进行覆盖)。
例如:

4.awk多进程扩展
"fork"扩展提供多进程相关功能。
@load "fork"
pid = fork()
创建一个子进程,对子进程返回值为0,对父进程返回值为子进程的PID,返回-1表示错误。
在子进程中,PROCINFO["pid"]和PROCINFO["ppid"]会随之更新。
ret = waitpid(pid)
等待某个子进程退出。awk的waitpid是非阻塞的,如果等待的进程还未退出,则返回值为0,等待的进程已经退出,则返回该进程pid。
ret = wait()
等待任意一个子进程退出。wait()是阻塞的,必须等待到一个子进程退出,同时返回该子进程PID。
例如:
awk '
@load "fork"
BEGIN{
if( (pid=fork()) == 0 ){
print "Child Process"
print "CHILD PID: "PROCINFO["pid"]
print "CHILD PPID: "PROCINFO["ppid"]
system("sleep 1")
} else {
while(waitpid(pid) == 0){
system("sleep 1")
}
print "Parent PID: "PROCINFO["pid"]
print "Parent PPID: "PROCINFO["ppid"]
print "Parent Process"
}
}
'
5.awk日期时间扩展
"time"扩展提供了两个函数。文章来源:https://www.toymoban.com/news/detail-741311.html
@load "time"
the_time = gettimeofday()
获取当前系统时间,以浮点数方式返回,精确的浮点小数位由操作系统决定
res = sleep(sec)
睡眠指定时间,可以是小数秒
$ awk '@load "time";BEGIN{printf "%.9f\n",gettimeofday()}'
1572422333.740148067
$ awk '@load "time";BEGIN{printf "%.19f\n",gettimeofday()}'
1572422391.5475890636444091797
睡眠是很好用的功能:文章来源地址https://www.toymoban.com/news/detail-741311.html
awk '@load "time";BEGIN{sleep(1.2);print "hello world"}'
到了这里,关于一篇文章玩透awk的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!